Hadoop源码分析五hdfs架构原理剖析
1、 hdfs架构
在本系列文章三中出现了与hdfs相关的数个服务。
如果在hadoop配置时写的配置文件不同,启动的服务也有所区别
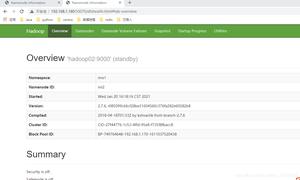
按照本系列文章二中的配置,会启动以下服务:namenode、journalnode、datanode、zkfc。其关系如图:
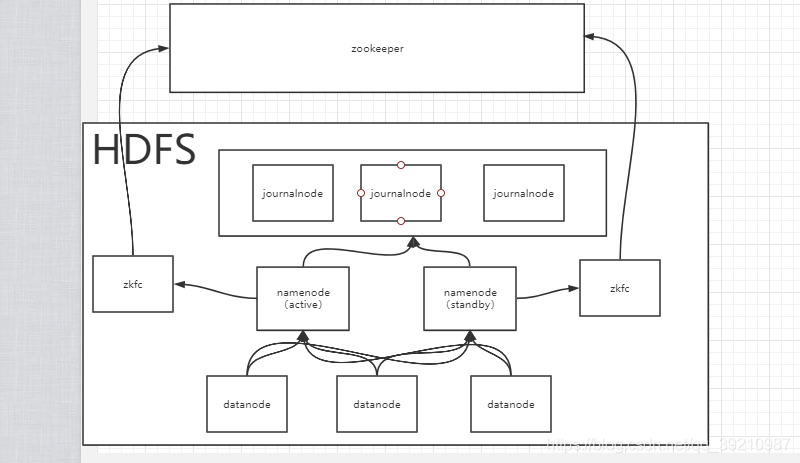
从图中可以看出namenode是绝对的中心节点,所有的节点都会和它进行交互。图中namenode有两台,一台为active,另一台为standby。其中active是正常提供namenode服务,standby不对外提供服务,它负责及时同步active的数据,并在active故障的时候转换为active继续提供服务。
namenode的下方是三台datanode。
datanode负责存储集群中的数据,并向namenode汇报其存储数据的情况。
namenode左右两边的是两个zkfc。
它负责的是namenode的故障转移,在active的namenode故障的时候,由zkfc将standby的namenode转换为active。zkfc上方连接的是zookeeper,它对namenode的故障转移是依靠zookeeper来实现的。
namenode的上方是三台journalnode集群。
journalnode负责存储namenode的日志文件,由active的namenode向journalnode写入,standby的namenode不会向journalnode写日志,standby主要会从其中读取日志文件。
注意,这里的日志文件不是普通的运行日志,而是namenode的操作日志。例如,客户端向hdfs上传了一个文件,这时namenode会执行一系列操作来完成这次上传,而这些操作连同操作方式与操作内容一起写到操作日志中(journalnode中),通过这些操作日志可以还原这次上传操作。
2、 namenode介绍
namenode作为hdfs的核心,它主要的作用是管理文件的元数据
元数据主要包括三类:文件的命名空间、文件与块的对应关系、块的存储位置。
文件与块的对应关系中的块
是由于hdfs在存储文件的时候并不是将整个文件将存储在某一台datanode上,而是将文件按照指定的大小切割成一定数量的块。
namenode负责管理hdfs的元数据
这意味着所有与hdfs相关的操作都需要与namenode进行交互。这样namenode的速度就不能太慢,所以namenode将元数据存储在内存中。但是数据不能只存储在内存中,所以这时需要将数据持久化到硬盘中。
namenode的数据持久化,采用了一种日志加快照的方式
日志即上文提到的操作日志,快照即将内存中的数据状态直接序列化到硬盘。在安装集群的时候会先格式化namenode,这时便会创建一个快照文件,名为fsimage。然后在namenode运行的时候它会将操作日志写入到fsimage文件所在的文件夹中。这里根据配置的不同写入的路径有所不同。如果使用本系列文章二中的配置,这个日志文件还会被写到journalnode中。
最后还会有一个程序读取这个快照文件和日志文件
将数据恢复到最新的状态,然后再更新原来的快照文件。下一次再读取快照和日志文件的时候就只读最新的文件。这里的程序会根据配置的不同有所区别,按照本系列文章二中的配置来说,是standby的namenode。这里为什么不直接使用active的namenode执行更新fsimage文件,而是使用standby的namenode先读取active的日志,然后再重演一遍操作日志恢复数据再由standby的namenode更新fsimage文件。这是因为更新fsimage操作很费时间,由active的namenode执行会导致整个集群不可用。
以上就是Hadoop源码分析五hdfs架构原理剖析的详细内容,本系列下一篇文章传送门Hadoop源码分析六启动文件namenode原理详解更多关于Hadoop源码分析的资料请持续关注更新!
以上是 Hadoop源码分析五hdfs架构原理剖析 的全部内容, 来源链接: utcz.com/p/248528.html