7.数据清洗[Python基础]

以此为例
一.重复数据处理
1.drop_duplicates
参数名 接收 意义 默认
subset
String / sequence
去重的序列
None(全部列)
keep
String
重复时保留第几个数据
first :保留第一个
last :保留最后一个
false :不保留
first(保留第一个)
inplace
Boolean
是否在原表上操作
False
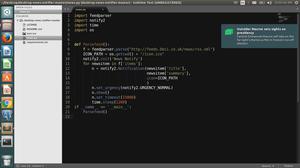
DataFrame.drop_duplicates()示例
二.缺失值处理
1.dropna删除法(减少样本)
参数名 接收 意义 默认
axis
0/1
0为删除记录特征为行
1为删除记录特征为列
0
how
String
any只要存在缺失就删除
all全部缺失才删除
any
subest
array
进行去重的行/列
None
inplace
Boolean
是否在原表上操作
Flash
DataFrame.dropna()示例
2.fillna替换法(影响标准差)
参数名 接收 意义 默认
value
Scalar
dict
series
Dataframe
表示用于替换的值
无
method
Stirng
Backfill/bfill 使用下一个缺失值来填补
Pad/ffil使用上一个缺失值填补
None
axis
0/1
轴向
1
inplace
Boolean
是否原表操作
False
limit
Int
填补缺失值的个数上限
None
DataFrame.fillna()示例
3.interpolater()插值法
参数method选择添加 参数
默认
"Linear"
数据增长速率越来越快
"quadratic"
数据集呈现出累计分布
"pchip"
平滑绘图为目标
"akima"
DataFrame.interpolater()示例
三.异常值处理
1.散点图查看异常值
可知异常为1
示例
2.箱线图查看异常值
可知异常为1
示例
3.处理方法借鉴缺失值处理
四.标准化
1.离差标准化
将数据映射到[0.1]的区间,处理线性变换数据
公式 :
[x=(x-min)/(max-min)
]
def lcbzh(DataFrame): DataFrame=(DataFrame-DataFrame.max())/(DataFrame.max()-DataFrame.min())
return DataFrame
示例
2.标准差标准
处理数据均值为0,标准差为1的数据
公式:
[x=(x-x.mean())/x.std()
]
3.小数定点标准化数据
用于移动小数点的位置至[-1,1]
公式:
[x=x/10^{np.ceil ( np.log10( x.abs().max() ) )}
]
以上是 7.数据清洗[Python基础] 的全部内容, 来源链接: utcz.com/z/530562.html