kafka随机写

- 设计目标
时间复杂度O(1)的方式提供消息持久化能力的。即使TB级别以上数据也能保证常数时间的访问性能,单机支持每秒100K条消息的传输。
- 特点:
- 高吞吐量。
- 消息持久化。
- 分布式。
- 消费消息采用Pull模式。
- 支持Online和Offine场景,同时支持离线数据处理和实时数据处理。
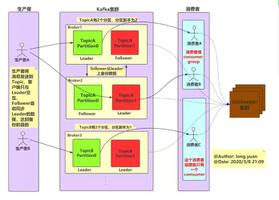
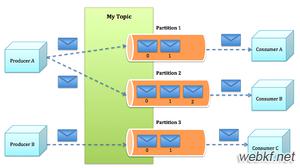
Kafka的基本存储单元是分区(Partition),在一个Topic中会有一个或 多个Partition,不同的Partition可位于不同的服务器节点上,物理上一个Partition对应于一个文件夹。需要注意的是,Partition不能在多个服务器节点之间再进行细分,也不能在一台服务器的多个磁盘上再细分,所以其大小会受挂载点可用空间的限制。
Partition内包含一个或多个Segment,每个Segment又包含一个数据文件和一个与之对应的索引文件。虽然物理上最小单位是Segment,但是Kafka并不提供同一个Partition内不同Segment的并行处理能力。对于写操作,每次只会写Partition内的一个Segment;对于读操作,也只会顺序读取同一个。
- 消息重复解决方案
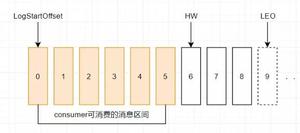
3.1 消费偏移量:
kafka在设计上不同于其他JMS队列的地方是生产者的消息不需要消费者确认,而消息在分区中又都是顺序排列的,那么必然就可以通过一个偏移量(offset)来确定每一条消息的位置。
kafka中有一个叫作_consumer_offset的特殊主题用来保存消息在每个分区的偏移量,消费者每次消费时都会往这个主题中发送消息,消息包含每个分区的偏移量。
如果所提交的偏移量小于客户端处理的最后一条消息的偏移量,那么两个偏移量之间的消息就会被重复处理;如果所提交的偏移量大于客户端处理的最后一条消息的偏移量,那么两个偏移量之间的消息就会被丢掉。所以想要用好kafka,维护消息偏移量对于避免消息被重复消费和遗漏消费,确保消息的ExactlyOnce是至关重要的,在org.apache.kafka.clients.consumer.KafkaConsumer类中提供了很多方式来提交偏移量:
自动提交(默认的时间间隔是5秒)
这种自动提交的方式看起来很简便,但会产生重复处理消息的问题。手动提交
在进行手动提交之前需要先关闭消费者的自动提交配置,然后使用commitSync提交偏移量。每接收到一批消息(或单个消息)并处理完之后提交一次偏移量,这样相对来说可以减少重复消息的数量,但会降低消费端的吞吐量。异步提交
以上是 kafka随机写 的全部内容, 来源链接: utcz.com/z/518647.html