Flink 生态:Pulsar Connector 机制剖析
Apache Pulsar 是 Yahoo 开源的下一代分布式消息系统,在2018年9月从 Apache 软件基金会毕业成为顶级项目。Pulsar 特有的分层分片的架构,在保证大数据消息流系统的性能和吞吐量的同时,也提供了高可用性、高可扩展性和易维护性。
分片架构将消息流数据的存储粒度从分区拉低到了分片,以及相应的层级化存储,使 Pulsar 成为 unbounded streaming data storage 的不二之选。这使得 Pulsar 可以更完美地匹配和适配 Flink 的批流一体的计算模式。
1. Pulsar 简介
1.1 特点
随着开源后,各行业企业可以根据不同需求,为 Pulsar 赋予更丰富的功能,所以目前它也不再只是中间件的功能,而是慢慢发展成为一个 Event Streaming Platform(事件流处理平台),具有 Connect(连接)、Store(存储)和 Process(处理)功能。
■ Connect
在连接方面,Pulsar 具有自己单独的 Pub/Sub 模型,可以同时满足 Kafka 和 RocketMQ 的应用场景。同时 Pulsar IO 的功能,其实就是 Connector,可以非常方便地将数据源导入到 Pulsar 或从 Pulsar 导出等。
另外,在Pulsar 2.5.0 中,我们新增了一个重要机制:Protocol handler。这个机制支持在 broker 自定义添加额外的协议支持,可以保证在不更改原数据库的基础上,也能享用 Pulsar 的一些高级功能。所以 Pulsar 也延展出比如:KoP、ActiveMQ、Rest 等。
■ Store
Pulsar 提供了可以让用户导入的途径后就必然需要考虑在 Pulsar 上进行存储。Pulsar 采用的是分布式存储,最开始是在 Apache BookKeeper 上进行。后来添加了更多的层级存储,通过 JCloud 和 HDFS 等多种模式进行存储的选择。当然,层级存储也受限于存储容量。
■ Process
Pulsar 提供了一个无限存储的抽象,方便第三方平台进行更好的批流融合的计算。即 Pulsar 的数据处理能力。Pulsar 的数据处理能力实际上是按照你数据计算的难易程度、实效性等进行了切分。
目前 Pulsar 包含以下几类集成融合处理方式:
Pulsar Function:Pulsar 自带的函数处理,通过不同系统端的函数编写,即可完成计算并运用到 Pulsar 中。
Pulsar-Flink connector 和 Pulsar-Spark connector:作为批流融合计算引擎,Flink 和 Spark 都提供流计算的机制。如果你已经在使用他们了,那恭喜你。因为 Pulsar 也全部支持这两种计算,无需你再进行多余的操作了。
Presto (Pulsar SQL):有的朋友会在应用场景中更多的使用 SQL,进行交互式查询等。Pulsar 与 Presto 有很好的集成处理,可以用 SQL 在 Pulsar 进行处理。

1.2 订阅模型
从使用来看,Pulsar 的用法与传统的消息系统类似,是基于发布-订阅模型的。使用者被分为生产者(Producer)和消费者(Consumer)两个角色,对于更具体的需求,还可以以 Reader 的角色来消费数据。用户可以以生产者的身份将数据发布在特定的主题之下,也可以以消费者的身份订阅(Subscription)特定的主题,从而获取数据。在这个过程中,Pulsar 实现了数据的持久化与数据分发,Pulsar 还提供了Schema 功能,能够对数据进行验证。
如下图所示,Pulsar 里面有几种订阅模式:
- 独占订阅(Exclusive)
- 故障转移订阅(Failover)
- 共享订阅(Shared)
- Key保序共享订阅(Key_shared)
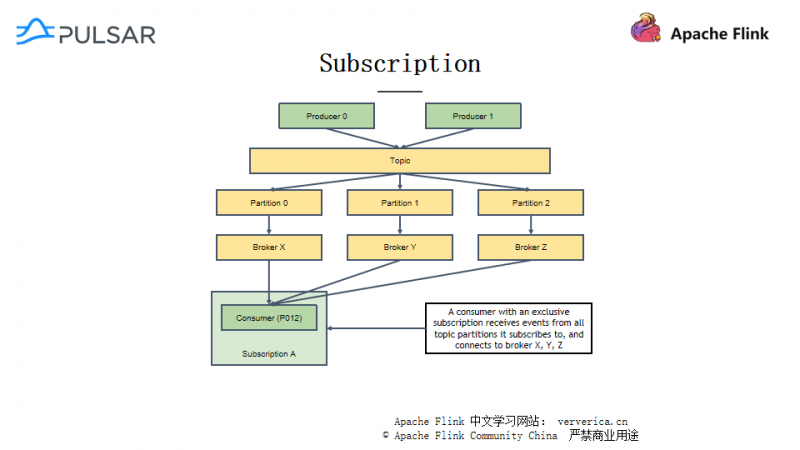
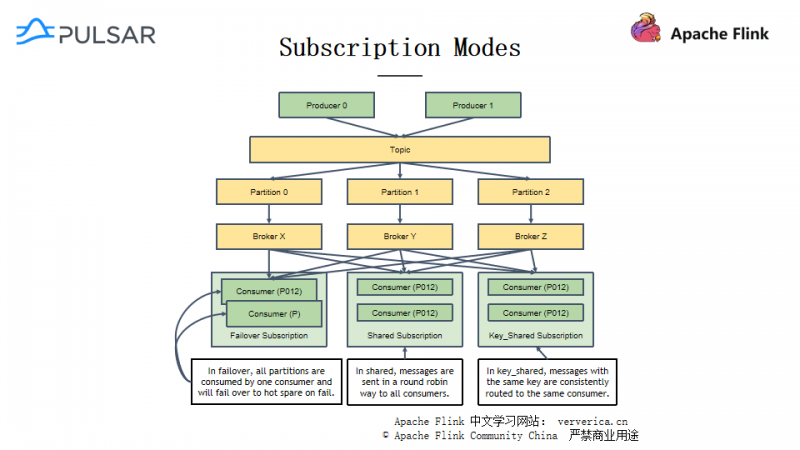
Pulsar 里的主题分成两类,一类是分区主题(Partitioned Topic),一类是非分区主题(Not Partitioned Topic)。
分区主题实际上是由多个非分区主题组成的。主题和分区都是逻辑上的概念,我们可以把主题看作是一个大的无限的事件流,被分区切分成几条小的无限事件流。
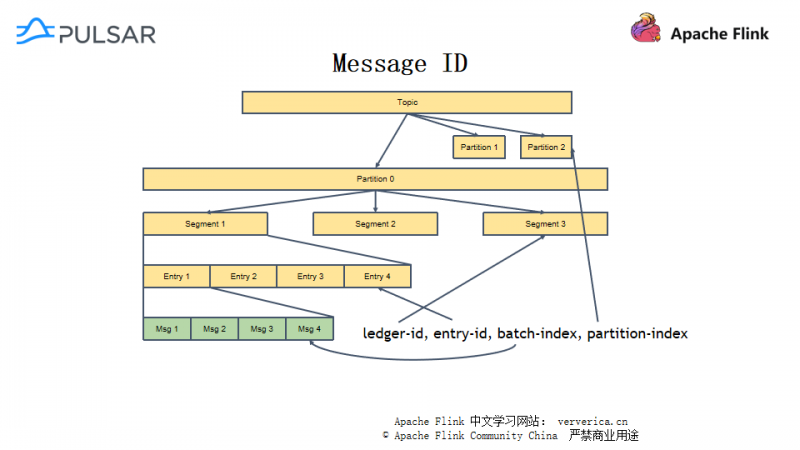
而对应的,在物理上,Pulsar 采用分层结构。每一条事件流存储在一个 Segment 中,每个Segment 包括了许多个Entry,Entry 里面存放的才是用户发送过来的一条或多条消息实体。
Message 是 Entry 中存放的数据,也是 Pulsar 中消费者消费一次获得的数据。Message 中除了包括字节流数据,还有 Key 属性,两种时间属性和 MessageId 以及其他信息。MessageId 是消息的唯一标识,包括了ledger-id、entry-id、 batch-index、 partition-index 的信息,如下图,分别记录了消息在Pulsar 中的Segment、Entry、Message、Partition 存储位置, 因此也可以据此从物理上找到Message的信息内容。
2. Pulsar 架构
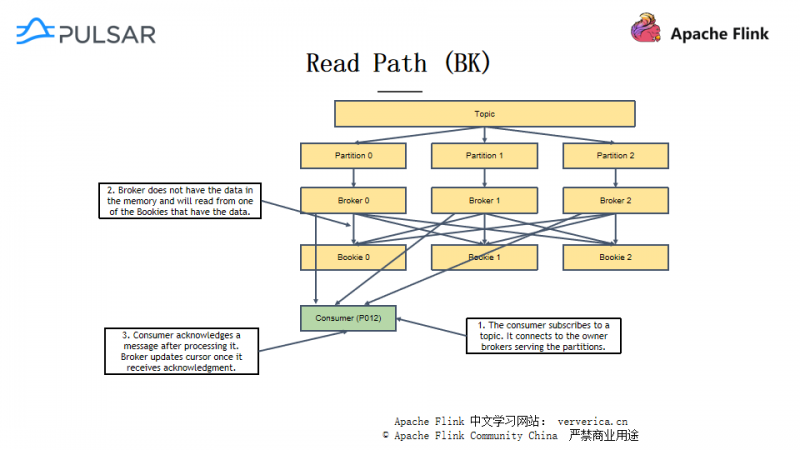
一个 Pulsar 集群由 Brokers 集群和 Bookies 集群组成。Brokers 之间是相互独立的,负责向生产者和消费者提供关于某个主题的服务。Bookies 之间也是相互独立的,负责存储 Segment 的数据,是消息持久化的地方。为了管理配置信息和代理信息,Pulsar 还借助了 Zookeeper 这个组件,Brokers 和 Bookies 都会在 zookeeper 上注册,下面从消息的具体读写路径(见下图)来介绍 Pulsar 的结构。
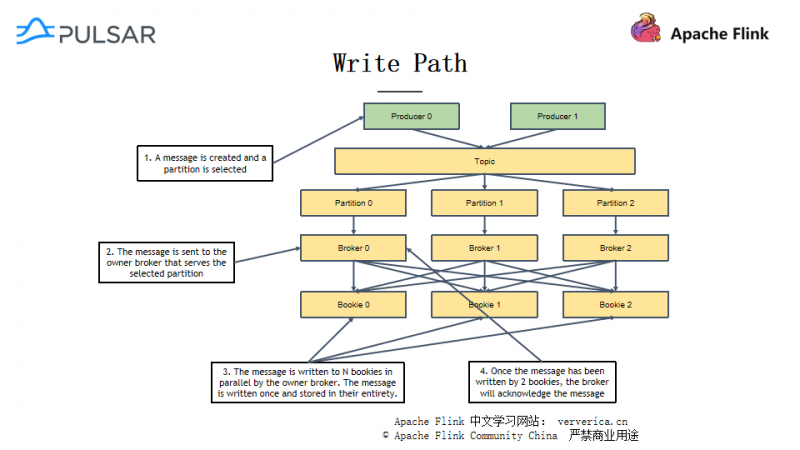
在写路径中,生产者创建并发送一条消息到主题中,该消息可能会以某种算法(比如Round robin)被路由到一个具体的分区上,Pulsar 会选择一个Broker 为这个分区服务,该分区的消息实际会被发送到这个 Broker上。当Broker 拿到一条消息,它会以 Write Quorum (Qw)的方式将消息写入到 Bookies 中。当成功写入到 Bookies 的数量达到设定时,Broker 会收到完成通知,并且 Broker 也会返回通知生产者写入成功。
在读路径中,消费者首先要发起一次订阅,之后才能与主题对应的 Broker 进行连接,Broker 从 Bookies 请求数据并发送给消费者。当数据接受成功,消费者可以选择向 Broker 发送确认信息,使得 Broker 能够更新消费者的访问位置信息。前面也提到,对于刚写入的数据,Pulsar 会存储在缓存中,那么就可以直接从 Brokers 的缓存中读取了,缩短了读取路径。
Pulsar 将存储与服务相分离,实现了很好的可拓展性,在平台层面,能够通过调整Bookies 的数量来满足不同的需求。在用户层面,只需要跟 Brokers 通信,而Brokers 本身被设计成没有状态的,当某个 Broker 因故障无法使用时,可以动态的生成一个新的 Broker 来替换。
3. Pulsar Connector 内部机制
首先,Pulsar Connector 在使用上是比较简单的,由一个 Source 和一个 Sink 组成,source 的功能就是将一个或多个主题下的消息传入到 Flink 的Source中,Sink的功能就是从 Flink 的 Sink 中获取数据并放入到某些主题下,在使用方式上,如下所示,与 Kafa Connector 很相似,使用时需要设置一些参数。
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment(); Properties props = new Properties();props.setProperty("topic", "test-source-topic") FlinkPulsarSource<String> source = new FlinkPulsarSource<>(
serviceUrl,
adminUrl,
new SimpleStringSchema(),
props);
DataStream<String> stream = see.addSource(source);
FlinkPulsarSink<Person> sink =
new FlinkPulsarSink(
serviceUrl,
adminUrl,
Optional.of(topic), // mandatory target topic
props,
TopicKeyExtractor.NULL, // replace this to extract key or topic for each record
Person.class);
stream.addSink(sink);
现在介绍 Kulsar Connector 一些特性的实现机制。
3.1 精确一次
因为 Pulsar 中的 MessageId 是全局唯一且有序的,与消息在 Pulsar 中的物理存储也对应,因此为了实现 Exactly Once,Pulsar Connector 借助 Flink 的 Checkpoint 机制,将 MessageId 存储到 Checkpoint。
对于连接器的 Source 任务,在每次触发 Checkpoint 的时候,会将各个分区当前处理的 MessageId 保存到状态存储里面,这样在任务重启的时候,每个分区都可以通过 Pulsar 提供的 Reader seek 接口找到 MessageId 对应的消息位置,然后从这个位置之后读取消息数据。
通过 Checkpoint 机制,还能够向存储数据的节点发送数据使用完毕的通知,从而能准确删除过期的数据,做到存储的合理利用。
3.2 动态发现
考虑到Flink中的任务都是长时间运行的,在运行任务的过程中,用户也许会需要动态的增加部分主题或者分区,Pulsar Connector 提供了自动发现的解决方案。
Pulsar 的策略是另外启动一个线程,定期的去查询设定的主题是否改变,分区有没有增删,如果发生了新增分区的情况,那么就额外创建新的Reader 任务去完成主题下的数据的反序列化,当然如果是删除分区,也会相应的减少读取任务。
3.3 结构化数据
在读取主题下的数据的过程中,我们可以将数据转化成一条条结构化的记录来处理。Pulsar 支持 Avro schema and avro/json/protobuf Message 格式类型的数据转化成 Flink 中的 Row格式数据。对于用户关心的元数据,Pulsar 也在 Row 中提供了对应的元数据域。
另外,Pulsar 基于 Flink 1.9 版本进行了新的开发,支持 Table API 和 Catalog,Pulsar 做了一个简单的映射,如下图所示,将 Pulsar 的租户/命名空间对应到 Catalog 的数据库,将主题对应为库中的具体表。

4. 未来规划
首先,之前提到 Pulsar 将数据存储在 Bookeeper 中,还可以导入到 Hdfs 或者 S3 这样的文件系统中,但对于分析型应用来说,我们往往只关心所有数据中每条数据的部分属性,因此采用列存储的方式对 IO 和网络都会有性能提升,Pulsar 也在尝试在Segment 中以列的方式存储。
其次,在原来的读路径中,不管是 Reader 还是Comsumer,都需要通过 Brokers 来传递数据。如果采用新的 Bypass Broker方式,通过查询元数据,就能直接找到每条 Message 存储的 Bookie 位置,这样可以直接从 Bookie 读取数据,缩短读取路径,从而提升效率。
最后,Pulsar 相对 Kafka 来说,由于数据在物理上是存放在一个个 Segment 中的,那么在读取的过程中,通过提高并行化的方式,建立多线程同时读取多个 Segment,就能够提升整个作业的完成效率,不过这也需要你的任务自身对每个Topic 分区的访问顺序没有严格要求,并且对于新产生的数据,是不保存在 Segement 的,还是需要做缓存的访问来获取数据,因此,并行读取将成为一个可选项,为用户提供更多的选择方案。
以上是 Flink 生态:Pulsar Connector 机制剖析 的全部内容, 来源链接: utcz.com/a/33286.html