性能优化(4)案例总结

jconsole远程连接须配置JMX
/data/noob/jdk1.8.0_151/bin/java
-Djava.rmi.server.hostname=127.0.0.1 #远程服务器ip,即本机ip
-Dcom.sun.management.jmxremote #允许JMX远程调用
-Dcom.sun.management.jmxremote.port=7018 #自定义jmx 端口号
-Dcom.sun.management.jmxremote.rmi.port=7019 # JMX在远程连接时,会随机开启一个RMI端口作为连接的数据端口,很有可能这个端口会被防火墙给阻止,以至于连接超时失败。可以将这个端口和jmx.port的端口设置成一个端口,这样防火墙策略就只需要同行一个端口就可以了
-Dcom.sun.management.jmxremote.authenticate=false #是否需要秘钥
-Dcom.sun.management.jmxremote.ssl=false # 是否需要ssl 安全连接方式
-jar ./bussiness-0.0.1-SNAPSHOT.jar
-Xms2048m -Xmx2048m -Xmn1024g -Xss2m -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:ParallelGCThreads=4 -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=3 -XX:+UseParNewGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -XX:+PrintGCApplicationConcurrentTime -XX:+PrintTenuringDistribution -XX:+PrintGCApplicationStoppedTime -Xloggc:../log/gc.log
案例分析过程
CPU 过高
查看进程下的子线程tid: top -Hp pid
- load average: 数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了
nid转十六进制: printf "%x
" tid
查看堆栈信息: jstack -l pid | grep nid -A [条数]
nid 就是线程ID
NIO的epoll空轮询bug
EPollArrayWrapper.epollWait 导致CPU占用率过高
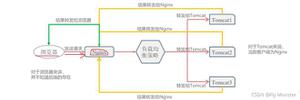
上图中,CPU占用率高的线程堆栈信息: 线程状态一直是RUNNABLE。
参见 https://bugs.java.com/bugdatabase/view_bug.do?bug_id=6403933
这是Linux上poll(和epoll)的问题。已连接套接字的文件描述符在轮询中如果使用掩码0来标识事件,高并发下,大量连接突然终止(RST),事件集合设置的POLLHUP(POLLERR)位将唤醒选择器!
但由于SocketChannel的事件key为0,这意味着没有任何选定的事件,select不阻塞并立即返回0,将再次进行轮询。
需要解决此错误以避免在重置连接时选择器旋转。如果事件掩码为0,则可以通过取消注册文件描述符(如果事件集合已更改,则重新注册)来解决此问题。
当key为非0时,POLLHUP(POLLERR)将需要转换为就绪集中的OP_READ或OP_WRITE事件,以便应用程序有机会处理IOException。
Netty的解决办法
对Selector的select操作周期进行统计,每完成一次空的select操作进行一次计数,若在某个周期内连续发生N次空轮询,则触发了epoll死循环bug。
重建Selector,判断是否是其他线程发起的重建请求,若不是则将原SocketChannel从旧的Selector上去除注册,重新注册到新的Selector上,并将原来的Selector关闭。
解决代码在 io.netty.channel.nio.NioEventLoop.select 方法中
上述问题也佐证了: 因NIO要轮询判定,对比BIO而言CPU的占用率可能会高些(BIO在阻塞时会释放CPU资源)。
解决方案可以参考:
https://blog.csdn.net/zhouhao88410234/article/details/76041702
https://bugs.java.com/bugdatabase/view_bug.do?bug_id=2147719
https://www.cnblogs.com/JAYIT/p/8241634.html
https://www.cnblogs.com/Jimmy104/p/5258205.html
正则表达式需要预编译
使用了错误的处理方式: 每次都重新生成Pattern
Pattern pattern = Pattern.compile(datePattern1);Matcher match = pattern.matcher(sDate);
导致系统线程长时间RUNNING在
优化
Pattern要定义为static final静态变量,以避免执行多次预编译
private static final Pattern pattern = Pattern.compile(regexRule);private void func(...) {
Matcher m = pattern.matcher(content);
if (m.matches()) {
...
}
在方法Pattern.matcher 具体实现中通过synchronized来保证线程安全。
ArrayList & LinkedList & HashSet 的选择
ArrayList & LinkedList 在remove指定对象时,都进行了遍历了List。
ArrayList:
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
LinkedList:
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
ArrayList底层实现是数组;LinkedList则是双向链表(内部类Node封装外部Object)
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
- get(int index):
ArrayList 直接数组操作性能会好些;
LinkedList 需要遍历双向链表定位index下的Node。 - add(Object o) :
ArrayList 可能要做扩容Arrays.copyOf(核心是System.arraycopy)。
LinkedList 则直接将原末尾Node的next指针指向新封装Node对象。 - add(int index, E element) :
ArrayList 需要做System.arraycopy操作。
LinkedList 最坏情况下需要遍历查找指定index上的Node, 前后指针的重新指向。(最好情况:直接是在队尾,通过判定index = size) - 删除时,
ArrayList 需要做System.arraycopy操作, remove(Object o) 需要提前遍历查找。
LinkedList 无论是remove(int index)还是remove(Object o),都需要遍历双向链表查找指定的Node(这里有个小细节: 查找过程(node方法)会优先判定 “index < (size >> 1)”来选择从首还是从尾开始遍历 )。
LinkedList的删除、新增时会比 ArrayList 好一点, 查询就差一点。
优化
最终按实际的业务场景的需要,选择使用 HashSet.
hashSet的底层实现是通过HashMap来实现hashCode散列定位(hashMap的底层也还是数组,内部有Node来封装外部数据Object)。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
hashMap在做查找、put、 remove等操作时,都会先通过对象hashCode计算定位在数组table上的具体存储位置。
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- ArrayList.forEach: 通过遍历数组下标顺序查找对象, hashSet.remove(t) 使用hashMap.remove;
- HashSet.removeAll(ArrayList):
- 若HashSet的size()大于ArrayList的size() 时, 顺序遍历数组元素, 使用hashMap.remove;
- 否则:顺序遍历HashSet的Node链, 再判定ArrayList.contains才删除。
因在具体实践中, 两边的size基本是相等的;所以,会多出一个判定ArrayList.contains的过程,那时间复杂度从O(n)上升为O(n2) 。
所以此时: ArrayList.forEach(t -> HashSet.remove(t)) 比 HashSet.removeAll(ArrayList) 效率快。
// HashSet extends AbstractSet
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
boolean modified = false;
if (size() > c.size()) {
for (Iterator<?> i = c.iterator(); i.hasNext(); )
modified |= remove(i.next());
} else {
for (Iterator<?> i = iterator(); i.hasNext(); ) {
if (c.contains(i.next())) {
i.remove();
modified = true;
}
}
}
return modified;
}
// ArrayList
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
action.accept(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
// ArrayList$Itr
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
以上是 性能优化(4)案例总结 的全部内容, 来源链接: utcz.com/z/517439.html