走进JavaVolatile关键字

Java Volatile 关键字是一种轻量级的数据一致性保障机制,之所以说是轻量级的是因为 volatile 不具备原子性,它对数据一致性的保障体现在对修改过的数据进行读取的场景下(也就是数据的可见性)。比起对读操作使用互斥锁, volatile 是一种很高效的方式。因为 volatile 不会涉及到线程的上下文切换,以及操作系统对线程执行的调度运算。同时 volidate 关键字的另一个功能是解决“指令重排序问题”。
Volatile 可见性承诺
Java volatile关键字保证了跨线程更改线程间共享变量的可见性。这可能听起来有点抽象,让我们详细说明一下。
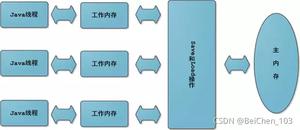
在多线程应用程序中,线程对 non-volatile 变量进行操作,出于性能原因,每个线程在处理变量时,可以将它们从主内存复制到CPU缓存中。如果你的计算机包含一个以上的CPU,每个线程可以在不同的CPU上运行。这意味着,每个线程可以将同一个变量复制到不同CPU的CPU缓存中。这就和计算机的组成和工作原理息息相关了,之所以在每一个 CPU 中都含有缓存模块是因为出于性能考虑。因为 CPU 的执行速度要比内存(这里的内存指的是 Main Memory)快很多,因为 CPU 要对数据进行读、写的操作,如果每次都和内存进行交互那么 CPU 在等待 I/O 这个过程中就消耗了大量时间,大部分时间都是在停滞等待而没有真正投入工作当中。所以为了解决这个问题就引入了CPU缓存。如下图所示:
这样就导致了一个问题同一个变量会被不同的 CPU 放在自己的缓存中,对该变量的读、写操作在缓存中进行。当然对于非共享数据来说这一点问题也没有,就比如函数内部的变量,但是对于共享数据来说就会造成多个 CPU 之间对该数据进行了操作但是别的 CPU 不知道这个数据发生了改变 ,依然使用旧的数据,最终导致程序不符合我们的预期。因为 CPU 是不知道你的程序内哪些数据是多线程共享数据,而那些数据不是,如果你不告诉 CPU 那么它默认都会认为这些数据都是不共享的,而各自在自己的缓存中随意操作。比如这个代码:
public class VolatileCase0 {
public int counter = 0;
}
这个代码在多线程执行的环境下是不安全的,counter 是共享变量。假设两个 CPU 共同操作同一个 VolatileCase0 对象,如下图所示:
目前这个情况下 counter 在两个 CPU 缓存中都存在,但是每个 CPU 对 counter 的操作对其他 CPU 来说是不可见的。因为此时我们并没有告知 CPU 和 CPU 缓存这个 counter 是一个共享内存变量。要解决多个 CPU 缓存之间变量写操作可见性的问题,就需要用 volatile 关键字来修饰这个 counter 。代码如下:
public class VolatileCase0 {
public volatile int counter = 0;
}
接下来看一个例子程序:
public class VolatileCase1 { volatile boolean running = true;
public void run() {
while (running) {
}
System.out.println(Thread.currentThread().getName() + " end of execution ");
}
public void stop() {
running = false;
System.out.println(Thread.currentThread().getName() + " thread Modified running to false");
}
public static void main(String[] args) throws Exception {
VolatileCase1 vc = new VolatileCase1();
Thread t1 = new Thread(vc::run , "Running-Thread");
Thread t2 = new Thread(vc::stop , "Stop-Thread");
t1.start();
TimeUnit.SECONDS.sleep(1);
t2.start();
}
}
如果对 running 变量不加 volatile 关键字,程序就会陷在 “Running-Thread”中一直执行而无法结束。加上了 volatile 关键字之后 “Running-Thread”会读取到被修改后的 running 值,这时就可以执行结束了。
Volatile 禁止指令重排序
首先需要解释一下什么是“指令重排序”。所谓指令重排序也就是 CPU 对程序指令进行执行的时候,会按照自己制定的顺序,并不是完全严格按照程序代码编写的顺序执行。这样做的原因也是出于性能因素考虑,CPU对一些可以执行的指令先执行可以提供总体的运行效率,而不是让CPU把时间都浪费在停滞等待上面。感兴趣的读者可以参考这篇文章:
感兴趣的读者也可以阅读 64-ia-32-architectures-software-developer-vol-3a-part-1-manual 这个开发手册。以下是该手册中对于指令重排序的一些描述:
译文:术语Memory Ordering 是指处理器通过系统总线向系统内存发出读(装入)和写(存储)的顺序。Intel 64和IA-32体系结构支持多种内存排序模型,具体取决于体系结构的实现。例如,Intel386处理器强制执行程序排序(通常称为强排序),在任何情况下,读写都是按指令流中发生的顺序在系统总线上发出的。
为了优化指令执行的性能,IA-32体系结构允许在Pentium 4、Intel Xeon和P6系列处理器中偏离称为处理器排序的强排序模型。这些处理器排序变体(在这里称为内存排序模型)允许性能增强操作,比如允许读优先于缓冲写。这些变化的目的是提高指令执行速度,同时保持内存一致性,即使在多处理器系统中也是如此。我们通过一个代码来证实CPU对指令的重排序:
public class MemoryOrderingCase1 { static int x = 0 , y = 0 , a = 0 , b = 0;
public static void main(String[] args) throws Exception {
while (true) {
CountDownLatch latch = new CountDownLatch(2);
x = 0;
y = 0;
a = 0;
b = 0;
Thread t1 = new Thread(() -> {
a = 1;
x = b;
latch.countDown();
});
Thread t2 = new Thread(() -> {
b = 1;
y = a;
latch.countDown();
});
t1.start();
t2.start();
latch.await();
if (x == 0 && y == 0) {
System.out.println("x = " + x + " , y = " + y + " , a = " + a + " , b = " + b);
break;
}
}
}
}
当 x = 0 同时 y = 0 的时候说明CPU在写指令完成之前执行了读指令。
另一个例子 Java Double checking locking 单例模式,代码如下:
public class MemoryOrderingCase2 { private static volatile MemoryOrderingCase2 INSTANCE;
int a;
int b;
private MemoryOrderingCase2() {
a = 1;
b = 2;
}
public static MemoryOrderingCase2 getInstance() {
if (MemoryOrderingCase2.INSTANCE == null) {
synchronized (MemoryOrderingCase2.class) {
if (MemoryOrderingCase2.INSTANCE == null) {
MemoryOrderingCase2.INSTANCE = new MemoryOrderingCase2();
}
}
}
return MemoryOrderingCase2.INSTANCE;
}
}
在这个例子中如果 INSTANCE 取除掉 volidate 关键字就会导致问题的发生。假设有两个线程在访问 getInstance() 函数,执行序列如下:
1. 线程 1 进入 getInstance 函数 , INSTANCE 为 null ,并切当前没有线程持有锁定。
2. 线程 1 再次判断 INSTANCE 是否为 null ,结果为 true 。
3. 线程 1 执行 INSTANCE = new MemoryOrderingCase2() 。
4. 线程 1 执行 new MemoryOrderingCase2() 。
5. 线程 1 在堆内存中为对象分配了空间。
6. 线程 1 INSTANCE 指向了该对象,此时 INSTANCE 已经不为 null。
7. 线程 1 new MemoryOrderingCase2() 对象开始执行初始化过程,调用父类构造函数,给一些属性赋值等。
8. 线程 2 进入 getInstance 函数 ,判断 INSTANCE 不为 null ,将 INSTANCE 返回。
这里的问题在于 MemoryOrderingCase2 对象还没有完成全部的初始化过程,就被线程2暴漏给了外界。也就是说读操作在写操作还没有完成之前就发生了。
查看 getInstance() 函数的部分汇编代码:
0x0000000003a663f4: movabs $0x7c0060828,%rdx ; {metadata("org/blackhat/concurrent/date20200312/MemoryOrderingCase2")} 0x0000000003a663fe: mov 0x60(%r15),%rax
0x0000000003a66402: lea 0x18(%rax),%rdi
0x0000000003a66406: cmp 0x70(%r15),%rdi
0x0000000003a6640a: ja 0x0000000003a66557
0x0000000003a66410: mov %rdi,0x60(%r15)
0x0000000003a66414: mov 0xa8(%rdx),%rcx
0x0000000003a6641b: mov %rcx,(%rax)
0x0000000003a6641e: mov %rdx,%rcx
0x0000000003a66421: shr $0x3,%rcx
0x0000000003a66425: mov %ecx,0x8(%rax)
0x0000000003a66428: xor %rcx,%rcx
0x0000000003a6642b: mov %ecx,0xc(%rax)
0x0000000003a6642e: xor %rcx,%rcx
0x0000000003a66431: mov %rcx,0x10(%rax) ;*new ; - org.blackhat.concurrent.date20200312.MemoryOrderingCase2::getInstance@17 (line 24)
0x0000000003a66435: movl $0x1,0xc(%rax) ;*putfield a
; - org.blackhat.concurrent.date20200312.MemoryOrderingCase2::<init>@6 (line 16)
; - org.blackhat.concurrent.date20200312.MemoryOrderingCase2::getInstance@21 (line 24)
0x0000000003a6643c: movl $0x2,0x10(%rax) ;*putfield b
; - org.blackhat.concurrent.date20200312.MemoryOrderingCase2::<init>@11 (line 17)
; - org.blackhat.concurrent.date20200312.MemoryOrderingCase2::getInstance@21 (line 24)
0x0000000003a66443: movabs $0x76b907160,%rsi ; {oop(a "java/lang/Class" = "org/blackhat/concurrent/date20200312/MemoryOrderingCase2")}
0x0000000003a6644d: mov %rax,%r10
0x0000000003a66450: shr $0x3,%r10
0x0000000003a66454: mov %r10d,0x68(%rsi)
0x0000000003a66458: shr $0x9,%rsi
0x0000000003a6645c: movabs $0xf6fd000,%rax
0x0000000003a66466: movb $0x0,(%rsi,%rax,1)
0x0000000003a6646a: lock addl $0x0,(%rsp) ;*putstatic INSTANCE
; - org.blackhat.concurrent.date20200312.MemoryOrderingCase2::getInstance@24 (line 24)
这些代码并不是严格按照我们看到的顺序在 CPU 中执行的 ,15行 ~ 23 行都是对象的初始化过程 ,在 CPU 执行过程中有可能会在对象初始化过程没有执行完整之前将 INSTANCE 指向对象的内存地址。汇编代码中的 lock addl 就是加了 volatile 关键字后出现的。
Volatile & LOCK prefix
通过汇编代码我们发现了 volatile 的底层是用了汇编中 LOCK 指令前缀。那么这个 LOCK 指令前缀又有什么作用呢?关于 LOCK 指令前缀我在64-ia-32-architectures-software-developer-vol-3a-part-1-manual 开发手册中找到了相关说明。
LOCK prefix 对 Volatile 可见性保障的部分说明
【原文】
8.1 LOCKED ATOMIC OPERATIONS
The 32-bit IA-32 processors support locked atomic operations on locations in system memory. These operations are typically used to manage shared data structures (such as semaphores, segment descriptors, system segments, or page tables) in which two or more processors may try simultaneously to modify the same field or flag. The processor uses three interdependent mechanisms for carrying out locked atomic operations:
• Guaranteed atomic operations
• Bus locking, using the LOCK# signal and the LOCK instruction prefix
• Cache coherency protocols that ensure that atomic operations can be carried out on cached data structures (cache lock); this mechanism is present in the Pentium 4, Intel Xeon, and P6 family processors
【译文】
32位的IA-32处理器支持系统内存中位置上的锁定原子操作。这些操作通常用于管理共享数据结构(如信号量、段描述符、系统段或页表),其中两个或多个处理器可能同时尝试修改相同的字段或标记。处理器使用三种相互依赖的机制来执行锁定的原子操作:
•保证原子操作
•总线锁定,使用 LOCK# 信号和 LOCK 指令前缀
•缓存一致性协议,确保原子操作可以在缓存的数据结构上进行(缓存锁);这种机制出现在Pentium 4、Intel Xeon和P6系列处理器中
【原文】
These mechanisms are interdependent in the following ways. Certain basic memory transactions (such as reading or writing a byte in system memory) are always guaranteed to be handled atomically. That is, once started, the processor guarantees that the operation will be completed before another processor or bus agent is allowed access to the memory location. The processor also supports bus locking for performing selected memory operations (such as a read-modify-write operation in a shared area of memory) that typically need to be handled atomically, but are not automatically handled this way. Because frequently used memory locations are often cached in a processor’s L1 or L2 caches, atomic operations can often be carried out inside a processor’s caches without asserting the bus lock. Here the processor’s cache coherency protocols ensure that other processors that are caching the same memory locations are managed properly while atomic operations are performed on cached memory locations.
【译文】
这些机制在以下方面相互依赖。某些基本的内存事务(例如在系统内存中读取或写入一个字节)总是保证以原子方式处理。也就是说,一旦启动,处理器保证操作将在另一个处理器或总线代理被允许访问内存位置之前完成。处理器还支持总线锁定,用于执行选择的内存操作(例如在共享内存区域中的读-修改-写操作),这些操作通常需要以原子方式处理,但不会以这种方式自动处理。由于经常使用的内存位置通常缓存在处理器的L1或L2缓存中,所以原子操作通常可以在处理器的缓存中执行,而无需断言总线锁。在这里,处理器的缓存一致性协议确保在缓存内存位置上执行原子操作时,正确管理缓存相同内存位置的其他处理器。
【原文】
8.1.2 Bus Locking
Intel 64 and IA-32 processors provide a LOCK# signal that is asserted automatically during certain critical memory operations to lock the system bus or equivalent link. While this output signal is asserted, requests from other processors or bus agents for control of the bus are blocked. Software can specify other occasions when the LOCK semantics are to be followed by prepending the LOCK prefix to an instruction.
【译文】
Intel 64和IA-32处理器提供一个LOCK#信号,该信号在某些关键内存操作期间自动断言,以锁定系统总线或等效链路。当这个输出信号被断言时,来自其他处理器或总线代理的控制总线的请求被阻塞。软件可以指定在锁语义之后将 LOCK 前缀加到指令之前的其他情况。
【原文】
Locked operations are atomic with respect to all other memory operations and all externally visible events. Only instruction fetch and page table accesses can pass locked instructions. Locked instructions can be used to synchronize data written by one processor and read by another processor.
【译文】
相对于所有其他内存操作和所有外部可见事件,锁定操作是原子性的。只有指令获取和页表访问才能传递锁定的指令。锁定指令可以用来同步一个处理器写的数据和另一个处理器读的数据。
【原文】
8.1.4 Effects of a LOCK Operation on Internal Processor Caches
For the Intel486 and Pentium processors, the LOCK# signal is always asserted on the bus during a LOCK operation, even if the area of memory being locked is cached in the processor.For the P6 and more recent processor families, if the area of memory being locked during a LOCK operation is cached in the processor that is performing the LOCK operation as write-back memory and is completely contained in a cache line, the processor may not assert the LOCK# signal on the bus. Instead, it will modify the memory location internally and allow it’s cache coherency mechanism to ensure that the operation is carried out atomically. This operation is called “cache locking.” The cache coherency mechanism automatically prevents two or more processors that have cached the same area of memory from simultaneously modifying data in that area.
【译文】
8.1.4锁操作对内部处理器缓存的影响
对于Intel486和Pentium处理器,LOCK#信号总是在锁操作期间在总线上断言,即使被锁的内存区域被缓存在处理器中。P6和最近的处理器家族,如果内存的面积被锁在一个锁操作缓存的处理器执行锁定操作,回写式记忆和完全包含在一个高速缓存线路,处理器不能断言 LOCK#信号在总线上。相反,它将在内部修改内存位置,并允许它的缓存一致性机制,以确保操作是自动执行的。这个操作称为 “cache locking”。“缓存一致性机制自动防止两个或多个已缓存同一内存区域的处理器同时修改该区域内的数据。
LOCK prefix 对 Volatile 禁止指令重排序保障的部分说明
【原文】
Any locked instruction (either the XCHG instruction or another read-modify-write instruction with a LOCK prefix) appears to execute as an indivisible and uninterruptible sequence of load(s) followed by store(s) regardless of alignment.Other instructions may be implemented with multiple memory accesses. From a memory-ordering point of view, there are no guarantees regarding the relative order in which the constituent memory accesses are made. There is also no guarantee that the constituent operations of a store are executed in the same order as the constituent operations of a load.
【译文】
任何被锁定的指令(无论是XCHG指令还是另一条带有LOCK前缀的read-modify-write指令)看起来都是作为不可分割的、不可中断的加载序列执行的,不管是否对齐。其他指令可以通过多次内存访问来实现。从内存排序的角度来看,无法保证构成内存访问的相对顺序。也不能保证store的组成操作与load的组成操作以相同的顺序执行。
【原文】
8.2.5 Strengthening or Weakening the Memory-Ordering Model
The Intel 64 and IA-32 architectures provide several mechanisms for strengthening or weakening the memory ordering model to handle special programming situations. These mechanisms include:
• The I/O instructions, locking instructions, the LOCK prefix, and serializing instructions force spaner ordering on the processor.
• The SFENCE instruction (introduced to the IA-32 architecture in the Pentium III processor) and the LFENCE and MFENCE instructions (introduced in the Pentium 4 processor) provide memory-ordering and serialization capabilities for specific types of memory operations.
• The memory type range registers (MTRRs) can be used to strengthen or weaken memory ordering for specific area of physical memory (see Section 11.11, “Memory Type Range Registers (MTRRs)”). MTRRs are available only in the Pentium 4, Intel Xeon, and P6 family processors.
• The page attribute table (PAT) can be used to strengthen memory ordering for a specific page or group of pages (see Section 11.12, “Page Attribute Table (PAT)”). The PAT is available only in the Pentium 4, Intel Xeon, and Pentium III processors.
【译文】
8.2.5加强或弱化 Memory-Ordering 排序模型
Intel 64和IA-32体系结构提供了几种增强或减弱内存排序模型的机制,以处理特殊的编程情况。这些机制包括:
•I/O指令、锁定指令、锁定前缀和序列化指令强制处理器进行更强的排序。
•SFENCE指令(在奔腾III处理器中引入IA-32体系结构)和LFENCE和MFENCE指令(在奔腾4处理器中引入)为特定类型的内存操作提供内存排序和序列化功能。
•内存类型范围寄存器(MTRRs)可用于增强或削弱物理内存特定区域的内存顺序(参见第11.11节“内存类型范围寄存器(MTRRs)”)。mtrr仅适用于奔腾4、Intel Xeon和P6系列处理器。
•页面属性表(PAT)可用于加强对特定页面或页面组的内存排序(参见11.12节,“页面属性表(PAT)”)。PAT只能在奔腾4、Intel Xeon和奔腾3处理器上使用。
【原文】
Synchronization mechanisms in multiple-processor systems may depend upon a span memory-ordering model. Here, a program can use a locking instruction such as the XCHG instruction or the LOCK prefix to ensure that a read-modify-write operation on memory is carried out atomically. Locking operations typically operate like I/O operations in that they wait for all previous instructions to complete and for all buffered writes to drain to memory (see Section 8.1.2, “Bus Locking”).
【译文】
多处理器系统中的同步机制可能依赖于强大的内存排序模型。在这里,程序可以使用诸如XCHG指令或锁前缀之类的锁定指令来确保对内存的读-修改-写操作是自动执行的。锁定操作通常与I/O操作类似,因为它们等待所有前面的指令完成,并等待所有缓冲写操作耗尽内存(参见8.1.2节,“总线锁定”)。
看完本文有收获?请分享给更多人
微信关注「黑帽子技术」加星标,看精选 IT 技术文章
以上是 走进JavaVolatile关键字 的全部内容, 来源链接: utcz.com/z/514447.html