Kafka介绍

Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统。Kafka具有高性能、持久化、多副本备份、横向扩展能力。生产者往队列里写消息,消费者从队列里取消息进行业务逻辑。一般在企业架构设计中起到解耦、削峰、异步处理的作用。
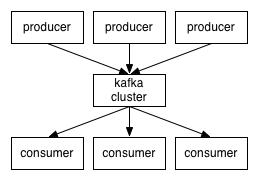
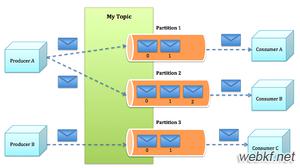
2 拓扑结构
3 相关术语
Broker
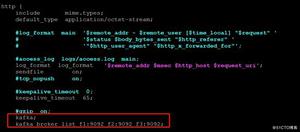
Kafka集群包含一个或多个服务器,集群中每个服务器被称为Broker
Topic
每条发布到Kafka集群的消息都有一个类别,被称为Topic
Partition
Partition是物理上的概念,每个Topic分为一个或多个Partition
Producer
负责发布消息到Kafka Broker的客户端
Consumer
消息消费者,从Kafka Broker读取消息的客户端
Consumer Group
每个Consumer术语一个特定的Consumer Group
Topic和Partition
Topic在逻辑上可以认为是一个队列,每条进入Kafka的消息都必须指定其Topic。为了使Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹用来存储该Partition的所有消息和索引文件。
Kafka是需要先写内存映射的文件,磁盘顺序读写的技术来提高性能的。Producer生产的消息按照一定的分组策略被发送到Broker的Partition中的时候,这些消息如果在内存中放不下,就会放在Partition目录下的文件中,Partition目录名是Topic的名称加上一个序号。在这个目录下有两类文件,一类是以log为后缀的文件,另一类是以index为后缀的文件。每个log文件和一个index文件相对应,这一对文件就是一个Segment File,其中的log文件就是数据文件,里面存放的就是消息,而index文件是索引文件,记录了元数据信息,指向对应的数据文件中消息的物理偏移量。
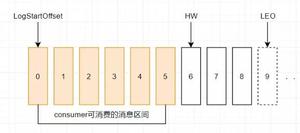
Segment File示意图如图所示。
log文件命名的规则是,Partition全局的第一个Segment从0(20个0)开始,后续的每一个文件的文件名是上一个文件最后一条消息的offset值。
index文件里面存储的是N对key-value,其中key是消息在log文件中的编号,比如1,3,6,8……,表示第1条、第3条、第6条、第8条消息等。value值表示该消息的物理偏移地址,如0,497,1407等。
索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。
log文件和index文件是对应关系,如下图所示。
其中以索引文件中元数据3 497为例,在数据文件中表示第3条消息(在全局partiton表示第368 772条消息),以及该消息的物理偏移地址为497。
例如读取offset=368776的message,需要通过下面两个步骤查找。
(1)查找Segment File
其中00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0。第二个文件00000000000000368769.index的消息量起始偏移量为368770=368769+1。同样,第三个文件00000000000000737337.index的起始偏移量为737338=737337+1,其他后续文件依次类推,以起始偏移量命名并排序这些文件,只要根据offset对文件列表进行二分查找,就可以快速定位到具体文件。当offset=368776时定位到00000000000000368769.index文件和00000000000000368769.log文件。368776 - 368769= 7 (就是index文件的第7条数,根据这个数据值取到log文件中数据的偏移量)
(2)查找消息
通过步骤(1)中定位到的Segment File进行查找,当offset=368776时,一次定位到元数据00000000000000368769.index的物理位置和00000000000000368769.log的物理偏移地址。然后通过00000000000000368769.log顺序查找直到offset=368776为止。
以上是 Kafka介绍 的全部内容, 来源链接: utcz.com/z/513702.html