Kafka数据同步

Kafka中Topic的每个Partition有一个预写式的日志文件,虽然Partition可以继续细分为若干个Segment File,但是对于上层应用来说可以将Partition看成最小的存储单元(一个含有多个Segment文件拼接的“巨型”文件),每个Partition都由不可变的消息组成,这些消息被连续的追加到Partition中。
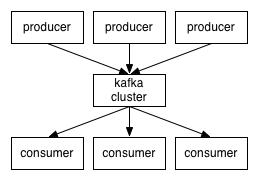
为了提高消息的可靠性,Kafka中每个Topic的partition有N个副本(replicas),其中N(大于等于1)是Topic的复制因子(replica fator)个数。Kafka通过多副本机制实现故障自动转移。当Kafka集群中一个Broker失效情况下仍然保证服务可用。在Kafka中发生复制时确保Partition的日志能有序地写到其他节点上。当N个replicas中有一个为Leader,其他都为Follower,Leader处理Partition的所有读写请求,与此同时,Follower会被动定期地去复制Leader上的数据。
Kafka的复制原理如图所示。
ISR副本同步队列
如果Leader发生故障或挂掉,Kafka将从同步副本列表中选举一个副本为Leader,这个新Leader被选举出来并被接受客户端的消息成功写入。Leader负责维护和跟踪ISR(In-Sync Replicas的缩写,表示副本同步队列)中所有Follower滞后的状态。当Producer发送一条消息到Broker后,Leader写入消息并复制到所有Follower中。消息提交之后才被成功复制到所有的同步副本。消息复制延迟受最慢的Follower限制,对于那些“落后”太多或者失效的Follower,Leader将会把它从ISR中删除。
下面先介绍LEO和HW两个概念,如图所示。
• LEO:LogEndOffset的缩写,表示每个Partition的log文件中的最后一条消息的位置。
• HW是HighWatermark的缩写,是指Consumer能够看到的Partition消息的位置。
Consumer无法消费分区下Leader副本中(Follower)位移值大于分区HW的任何消息(即如上图中6~10部分消息)。这个涉及多副本的概念。
下面通过一个案例说明当Producer生产消息至Broker后,ISR、HW和LEO的流转过程。
(1)初始状态下,HW等于LEO,Follower将Leader中全部消息备份,此时有生产者向Kafka写入消息,如下图所示。
(2)生产者将消息写入Leader中,此时Leader将变更LEO的位置,Follower1和Follower2将对Leader中的新增消息进行备份,如下图所示。
(3)Follower1完成Leader中所有消息的备份,Follower2未完成备份,此时HW更新为4,如下图所示。
(4)所有的Follower都将Leader中的消息备份完成,如下图所示。
以上是 Kafka数据同步 的全部内容, 来源链接: utcz.com/z/513701.html