Lucene索引存储结构

- 字典数据结构:字典树(Trie tree)、FST
- 字典树(Trie tree)
- 典型应用是用于统计和排序大量的字符串(但不仅限于字符串),
- 所以经常被搜索引擎系统用于文本词频统计。
- 它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
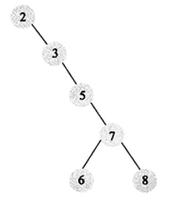
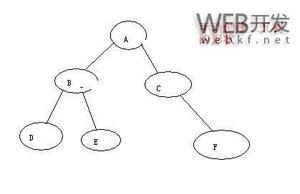
- 基本的实现有array与linked-list两种:
- array实现:
- linked-list实现:
- array实现:
- 双数组Trie树
- 在Trie数实现过程中,我们发现了每个节点均需要 一个数组来存储next节点,非常占用存储空间,空间复杂度大,
- 双数组Trie树正是解决这个问题的。
- 双数组Trie树(DoubleArrayTrie)是一种空间复杂度低的Trie树,
- 应用于字符区间大的语言(如中文、日文等)分词领域。
- 双数组的原理是,将原来需要多个数组才能表示的Trie树,使用两个数组就可以存储下来,可以极大的减小空间复杂度
- 使用两个数组base和check来维护Trie树,
- base负责记录状态,
- check负责检查各个字符串是否是从同一个状态转移而来,
- 当check[i]为负值时,表示此状态为字符串的结束。
- check[i] 代表从什么状态转换过来,如下,都是从base[t] 转换过来,所以 check[ta] = check[tb]
- base[t] + a.code = base[ta]
base[t] + b.code = base[tb]
check[ta] = check[tb]
- 在Trie数实现过程中,我们发现了每个节点均需要 一个数组来存储next节点,非常占用存储空间,空间复杂度大,
- 典型应用是用于统计和排序大量的字符串(但不仅限于字符串),
- FST
- lucene从4开始大量使用的数据结构是FST(Finite State Transducer)。
- FST有两个优点:
- 1)空间占用小。
- 通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
- 2)查询速度快。
- 1)空间占用小。
- http://www.shenyanchao.cn/blog/2018/12/04/lucene-fst/
- FST,不但能共享前缀还能共享后缀。
- 不但能判断查找的key是否存在,还能给出响应的输入output。
- 它在时间复杂度和空间复杂度上都做了最大程度的优化,
- 使得Lucene能够将Term Dictionary完全加载到内存,快速的定位Term找到响应的output(posting倒排列表)。
- 字典树(Trie tree)
数据结构
优缺点
排序列表Array/List
使用二分法查找,不平衡
HashMap/TreeMap
性能高,内存消耗大,几乎是原始数据的三倍
Skip List
跳跃表,可快速查找词语,在lucene、redis、Hbase等均有实现。相对于TreeMap等结构,特别适合高并发场景(Skip List介绍)
Trie
适合英文词典,如果系统中存在大量字符串且这些字符串基本没有公共前缀,则相应的trie树将非常消耗内存(数据结构之trie树)
Double Array Trie
适合做中文词典,内存占用小,很多分词工具均采用此种算法(深入双数组Trie)
Ternary Search Tree
三叉树,每一个node有3个节点,兼具省空间和查询快的优点(Ternary Search Tree)
Finite State Transducers (FST)
一种有限状态转移机,Lucene 4有开源实现,并大量使用
- 倒排索引
以上是 Lucene索引存储结构 的全部内容, 来源链接: utcz.com/z/512785.html