通过logstash实现mysql同步elasticsearch实现全文检索

目的:文本型数据无法实现关键字查询,某个汉字查询,思路: 实现将mysql某表中 id(mysql某张表中的主键)和content内容同步到elasticsearch ,利用elasticsearch倒排序特性,分词器,对content进行建立索引,通过分词在该elasticsearch查到记录,然后获得该记录的id,并通过该id进入mysql中通过该id(主键)去查询记录。提升查询速度。
(1) 自定义动态模板,在elasticsearch安装目录下新建templates目录(注意,elasticsearch下自定义模板,必须建这个目录)
如下,所有以所有test开头的 都会默认走这个模板配置,release_date指定date类型,des指定text,text类型默认是会分词的,将改des里的字符(汉字)按照默认分词器进行分词(倒排序,建索引的过程)
(2)启动elasticsearch, ./bin/elasticsearch
(3)实现mysql同步到elasticsearch,必须要借助logstash-input-jdbc插件(插件安装省略,logstash7.0默认已自带该插件)
(4)新建logstash配置文件 vi logstatic-test.sh
注意点:如果出现“LogStash::ConfigurationError com.mysql.jdbc.Driver not loaded. Are you sure you"ve included the correct jdbc driver in :jdbc_driver_library?”错误,可能jdbc_driver_library路径不对,也可能mysql-connector-java.jar 和当前环境不兼容,我在操作过程中,就出现该问题
jdk1.8 LogStash7.1.1 elastisearch 7.1 我刚开始用的mysql-connector-java.5.1.4.jar 就出现以上错误,我修改为mysql-connector-java-6.0.6.jar 才解决掉
(5)启动logstash ./bin/logstash -f ./config/logstash-test.conf
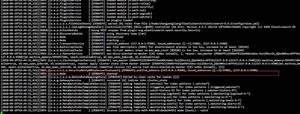
以下是数据同步的过程日志,/logstash7.1.1/logs/logstash-plain.log
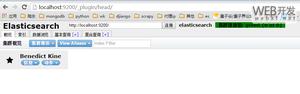
(6)借助elasticsearch-head 进行查看 进入elasticsearch-head 安装目录下并启动 npm run start
http://xxx.xxx.xxx.xxx:9100
验证查询des、title 是否分词可以查到
分词有时候会把词分成多个字进行查询 例如 “稳伦”,会分为“稳” “稳伦” “伦”等,具体怎么分,和用的分词器有关(具体分词器如何安装、指定、使用此处不做详解,可自行百度)
以上是 通过logstash实现mysql同步elasticsearch实现全文检索 的全部内容, 来源链接: utcz.com/z/512722.html