分布式ID的简单总结

简单总结一下流行的分布式id的实现方法
雪花算法
snowflake是twitter开源的分布式ID生成算法.
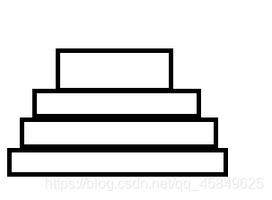
核心思想是:分布式ID固定是一个long型的数字,一个long型占8个字节,也就是64个bit,原始snowflake算法中对于bit的分配如下图:
- 第一个bit位是标识部分,在java中由于long的最高位是符号位,正数是0,负数是1,一般生成的ID为正数,所以固定为0
- 时间戳部分占41bit,这个是毫秒级的时间,一般实现上不会存储当前的时间戳,而是时间戳的差值(当前时间-固定的开始时间)
- 这样可以使产生的ID从更小值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年
- 工作机器id占10bit,这里比较灵活,比如,可以使用前5位作为数据中心机房标识,后5位作为单机房机器标识,可以部署1024个节点
- 序列号部分占12bit,支持同一毫秒内同一个节点可以生成4096个ID
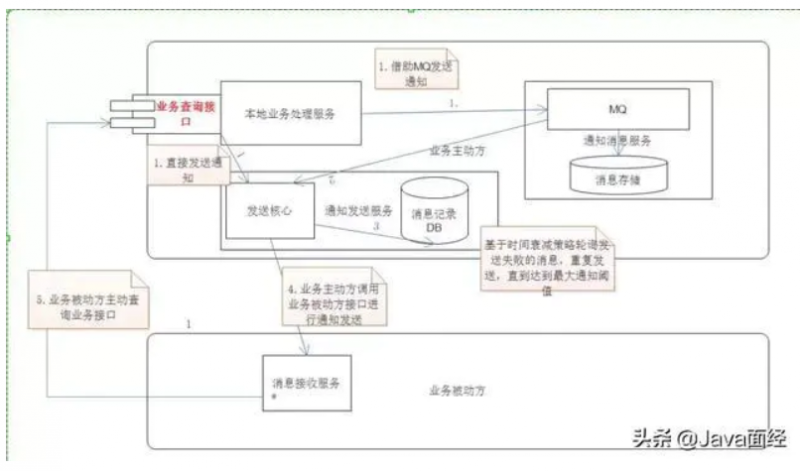
snowflake算法需要人工为每台机器去指定一个机器id,如果机器很多或者机器扩展时, 挨个配置肯定不太现实,而且类似docker容器的流行, 使得这个机器id已经不能狭隘地停留在“物理”层面上了, 应该把机器id扩展为当前“实例”的id, 比如百度开源的基于snowflake算法的uid-generator, 在每个应用实例启动时, 会插一条记录到数据库并返回所谓的机器id. 类似的还有美团开源的leaf.
基于中间件
分布式ID和分布式锁有一些类似, 一般也可以依赖mysql、redis、zk等中间件, 其中mysql基于auto_increment, redis基于incr, zk基于有序节点.
分布式id要求key值不停地渐变, 所以为了提高性能, 一般会采用“预生成”策略, 即一次生成N个id的号段缓存在本地, 这样做还有另外一个好处, 就是哪怕中间件宕机一小会儿也没什么影响.
此外, 如果中间件部署架构是无中心的, 比如两个master, 那么为了防止冲突, 一般采用初始id不一样但“步长”一样的策略, 比如两台mysql的初始id为1和2, 步长为2, 则各自节点的id为1、3、5...; 2、4、6... 不会冲突.
以上是 分布式ID的简单总结 的全部内容, 来源链接: utcz.com/z/511909.html