分布式事务-个人理解
cap
C:一致性被称为原子对象,任何的读写都应该看起来是“原子”,或串行的。写后面的读一定能读到前面写的内容,所有的读写请求都好像被全局排序。
A:对任何非失败节点都应该在有限时间内给出请求的回应。(请求的可终止性)
P:允许节点之间丢失任意多的消息,当网络分区发生时,节点之间的消息可能会完全丢失
个人理解:
- 对于C,就是保证在一个时间点各个节点的状态是一致的,而A是在用户的视角看来各个节点都是正常的,P就是在节点看开各个节点都是正常连接
- 但在分布式环境中,多实例部署是基本条件,因为网络的不可靠性,造成了P成了硬性条件,所以分布式系统基本都是cp和ap的
base
- 基本可用(Basically Available)
- 软状态(Soft State)
- 最终一致性(Eventually Consistent)
个人理解:
- base理论落地基本都是ap的系统,分布式事务和业务有着强耦合的关系,因为基本上业务层面要维持一个中间状态好让事务可以有回滚余地而不破坏数据
- 其次因为有中间状态所以在事务的过程中基本都是最终一致
xa
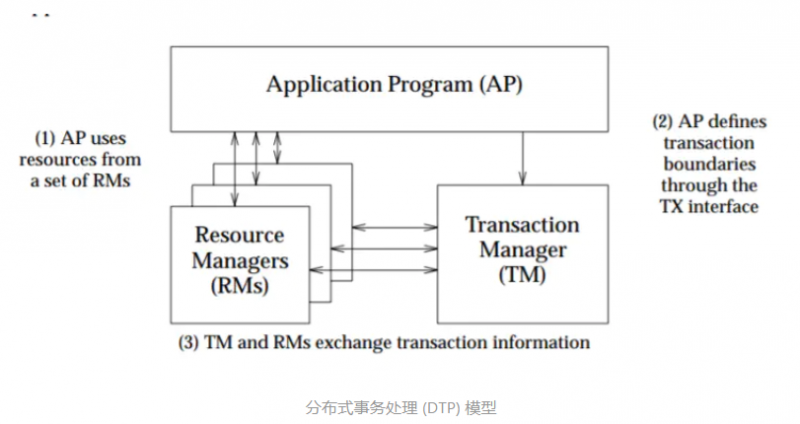
如图基本分以下三种角色
- AP 应用程序
- RM 资源管理器
- TM 事务管理器
个人理解:
- 基本各个资源管理器要实现各自的资源管理接口
- 应用程序向资源管理器申请资源,然后对资源的修改不是直接通知资源管理器,而是预先准备好,然后由三方的事务管理器统一进行修改
- 使用该协议的系统基本都是cp类型的系统
2pc/3pc
2pc
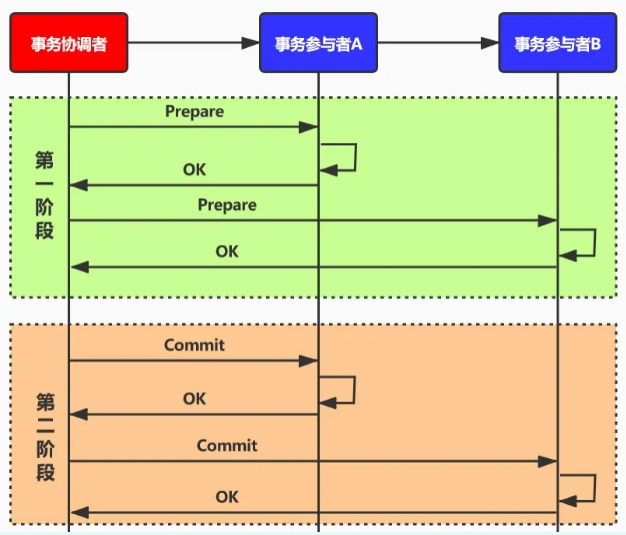
个人理解:
- 在prepare阶段对事务执行完毕剩下事务提交,只要一处执行出问题就触发事务回滚
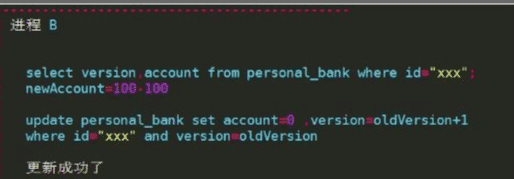
- 在提交阶段由于网络问题可能会有不一致的问题
- 各个事务之间相互依赖成功,锁定资源的时间过长(阻塞时间过长)
- 对于事务协调器有超时重新选举,但是各个服务没有超时机制
3pc
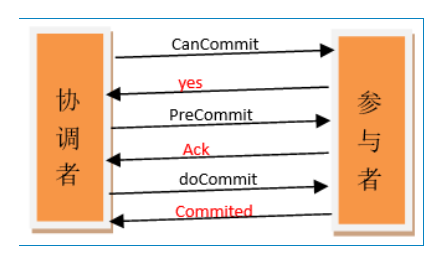
- 在2pc之上增加了一层,个人理解这一层是为了辅助超时阶段,因为在preCommit阶段事务已经就剩下提交其他服务也都确认成功,最后每个服务都会启动一个超时计划,到时直接提交而不是等待协调器来docommit, 而docommit就是提交命令,但是各个服务可能因为网络无法接收所以有个超时机制,也就是为了弥补2pc中的阻塞过长和服务端没有超时机制
tcc
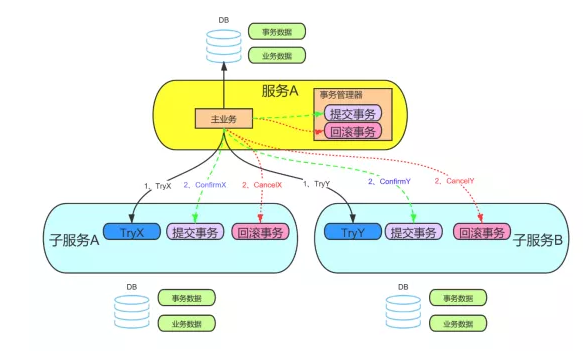
- tcc本质就是base中的业务提供一种中间态,通过准备提交和回滚来完成整体事务
- 整体增加了事务管理器来自动化的进行管理事务的进程,比如宕机后事务管理器会定时的去执行日志记录中事务的进程保证最终一致性
- 一般分布式事务都会传递全局事务id来标识事务和解决幂等性
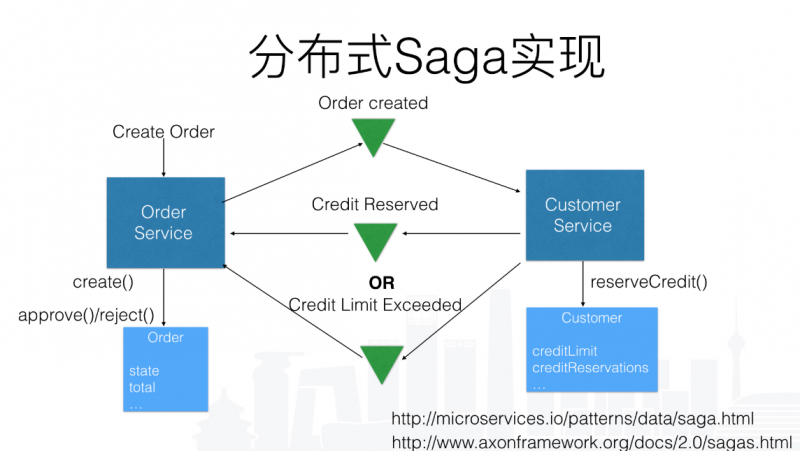
sega
个人理解sega很像2pc但是sega的事务都是自己提交自己的,对于集中式出问题由主业务进行回滚或者重试,对于分布式而是递归的形式进行回滚
上述的几个问题
- 整体上我这样理解,sega是最终一致性的,但是又不会有base的中间状态,所以会有隔离性的问题,容易出现幻读重复度,读更改等各种问题,对于解决方案一般都是sega对应的框架自行提供全局读写锁来进行提供隔离性
- 对于sagas框架来看,他实现了事务协调器来简化事务的回滚和重试,实现了一套自行生成回滚sql的机制来进行
- 对于sagas还有很多设计,目前个人没有时间研究后续研究透了会重写相关sagas的问题(对于sagas历史好像最开始是阿里收费项目gks,当时看人反汇编代码说实现可能是自动生成回滚代码的tcc,现在看来是saga的模式加全局锁)
sega2种回滚方案
- backward recovery,向后恢复,补偿所有已完成的事务,如果任一子事务失败。即上面提到的第二种执行顺序,其中j是发生错误的sub-transaction,这种做法的效果是撤销掉之前所有成功的sub-transation,使得整个Saga的执行结果撤销。
- forward recovery,向前恢复,重试失败的事务,假设每个子事务最终都会成功。适用于必须要成功的场景,执行顺序是类似于这样的:T1, T2, ..., Tj(失败), Tj(重试),..., Tn,其中j是发生错误的sub-transaction。该情况下不需要Ci
集中式
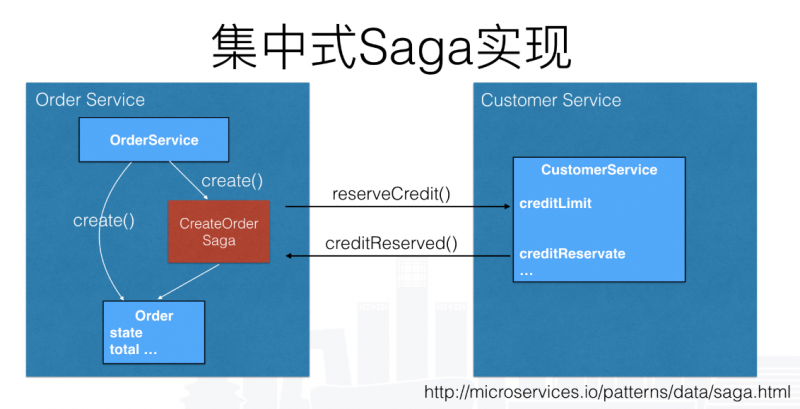
分布式
消息事务/本地消息事务
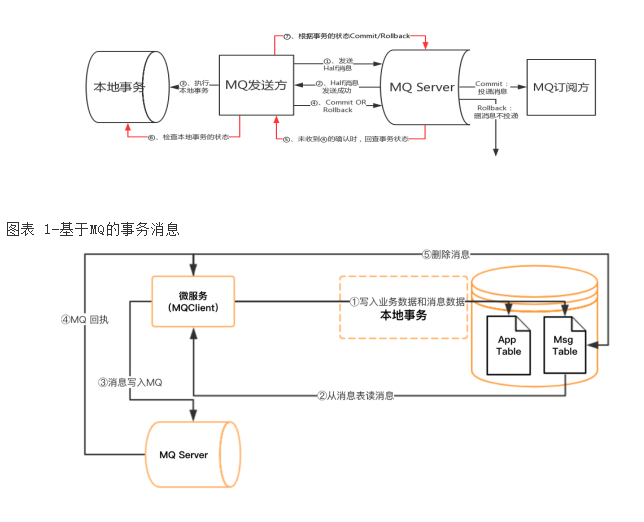
个人理解:
- 对于消息事务,本质就是保证消息能进入mq, 还要保证消息不丢失和持久化,然后其他业务是通过消息订阅来完成对应业务,主要还是要保证幂等性和重复投递的问题
- 而本地消息事务,本质就是将事务数据和本地事务一起持久化,而服务通过监听数据表来执行业务,当然也可以my直接通知
- 2者的本质都是将事务进行持久化,然后有个中间系统(宕机后继续事务)保证事务能完成整个流程
最大通知事务
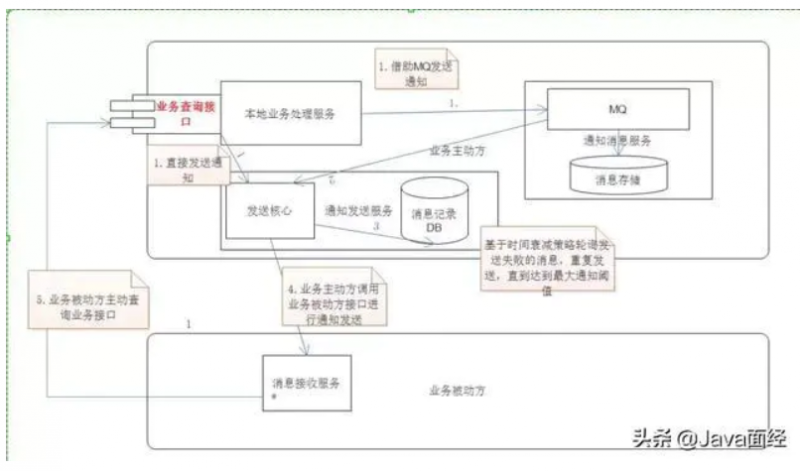
- 保证本地事务处理完,事务处理器能接收到mq的数据和对记录有个日志,然后通过有规律的对外部系统进行主动通知(类似微信和支付宝支付回调)
- 当通知超时后后续不再通知,而是由外部系统自行调用接口进行查询
以上是 分布式事务-个人理解 的全部内容, 来源链接: utcz.com/a/29119.html