RabbitMQ消息的100%投递

生产端的可靠性投递
- 保障消息的成功发出
- 保障MQ节点的成功接收
- 发送端收到MQ节点确认应答
- 完善的消息进行补偿机制
解决方案
- 消息落库,对消息状态进行打标
- 消息的延迟投递,做二次确认,回调检查
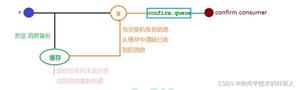
消息落库架构图
上图中BIZ DB为我们的业务库,比方说保存订单;MSG DB为消息库,保存我们发送到MQ消息。如果在Step 3的时候,网络出现故障,Confirm机制没有收到broker的消息确认。我们需要设置一个时间临界点,比如说5分钟,检索出消息库中状态为0的消息,通过分布式定时任务,比如XXL-Job或者Elastic-Job。但有可能出现消息刚发出去,还没有Confirm成功,定时任务就已经启动了,并把发送成功的消息确认为未成功,所以我们需要有一个Step 6,给入库消息一个最大的容忍时间,比如说2分钟到5分钟。比如消息入库的时候需要带上时间,我们取出状态为0的消息形成一个集合,然后过滤该集合的时间为2分钟以上的消息进行重新发送。由于MQ消息的配置本身有问题的情况下(比如说路由,队列,交换机),会出现消息永远无法发送成功,这个时候我们需要有一个消息重试的机制,比如3次,如果3次都没有发送成功,则更新该消息状态为2,表示失败。
但是这种方式有一定的局限性,因为要做数据库的二次入库操作,磁盘io会成为瓶颈,在高并发的场景下并不合适。由于我们的业务入库是必须的,所以我们要考虑消息入库是否可以取消。所以我们要考虑第二种方式:消息的延迟投递,做二次确认,回调检查。
这里的Upstream service为我们的上流业务,我们肯定要做的是进行业务入库,然后再发消息到Broker,这里的不同在于Step2,Step2需要再发一条消息,但这条消息是一个延迟消息(这种延迟消息并不是死信队列那种延迟消息,我们可以用DelayQueue来发这条消息),可能是2到5分钟之后才发出去的,该消息与Step1虽然消息内容一样,但是它们投递的队列不同,该队列被Call back service监听。Downstream service为MQ消费者,但它同时也是消息投递者,它会在Step4发送一个confirm消息(该消息也是一个MQ消息)到Broker,但是这条消息并不是发给上流生产者的,而是发给Call back service的,Call back service作为消息消费者收到这条消息,然后做一个消息的持久化存储,存入数据库中。3到5分钟之后,Call back service收到延迟发送的Step2的消息,再去对比消息数据库中的消息,更新消息数据库中的状态为1。如果在此过程中,Downstream service没有发送消息给Call back service,则消息数据库中没有这条消息,当Call back service收到Step2的延迟消息的时候,就通过RPC或者Restful重新调用upstream中的业务库检查后,再重新发送一条step1消息,走下一个流程。
以上的这个方案并不能保证100%的消息投递,但是它对于第一种方案的好处是少进行了一次DB操作,保证高并发的性能。比如说第一种方式的吞吐量为1000,那第二种方式的吞吐量就可以翻倍到2000,可以节省一台服务器。这里把消息补偿机制从第一种方式的嵌入到核心链路给解耦为一个单独的微服务,核心链路则只有消息发送到消息处理。同时下游业务处理应该加上消息的幂等,确保只处理一个消息。
以上是 RabbitMQ消息的100%投递 的全部内容, 来源链接: utcz.com/z/511599.html