深度长文|百度PaddleLite性能进化之路!

Paddle Lite作为一款主打端侧高性能轻量化部署的推理引擎,具有
高扩展性
、训练推理无缝衔接,通用性、高性能和轻量化等优点。
Paddle Lite是如何进行性能优化、提升自身竞争力的?
下面我们将围绕
框架层性能优化
、
GPU算子优化
、
CPU算子优化
以及
模型剪裁与搜索
四方面介绍性能优化的手段及思路。
(本文根据百度资深研发工程师杨延展在2019年11月19日软件绿色联盟开发者大会发表的《深度剖析Paddle Lite性能进化之路》主题演讲整理而成。)
Paddle Lite是百度自研的一款深度学习框架库,它的前身是Paddle Mobile,自2019年升级至Paddle Lite的全新架构后,拥有了更广泛的适用平台,支持从移动端到服务端的各类场景。
重点发力的移动端中,安卓和IOS已同时覆盖CPU和GPU,而且在安卓方面已经覆盖了华为NPU。
提到Paddle Lite的作用,大家在工作和生活中接触较多的有人脸识别、图片、视频分辨率提升、物体检测与跟踪等深度学习的场景。
Paddle Lite如何实现上述场景中提到的功能呢?简单概括就是Paddle Lite通过解析、加载并运行Paddle训练的模型,并将模型结果展示到业务层。Paddle Lite框架就是保证在运行过程中执行模型规定的每个计算步骤,这里的计算步骤被称之为算子,也就是说一个预测框架库的任务就是让算子按照它的定义依次执行。
Paddle Lite性能优化手段
2.1 框架层性能优化
2.1.1 传统Paddle Mobile架构简介
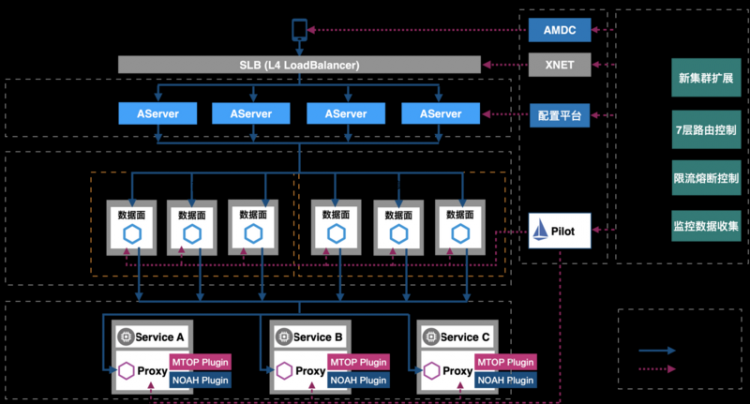
首先看下Paddle Mobile的框架结构图,对于运行环境来说,它是由算子列表和Scope两部分组成的,算子列表是要执行的运算内容,而Scope是作用域。通过架构图右侧区域可以看到算子包含输入、输出、参数以及执行计算的计算单元Kernel四部分,这里涉及的输入和输出都需要经过内存的分配和重用,而Scope的作用就相当于算子运算过程中所需要资源生成和释放的池子。
对于算子的四个组成部分来说,最重要的是计算单元Kernel。Kernel是与平台绑定到一起的,比如想要实现CPU Kernel,就需要编写Arm Kernel相关代码,也就是说在Paddle Mobile架构中,所有的Kernel都是耦合在算子的范畴中的。如想要优化OPenCL代码时,需要将代码嵌入到整体的算子中,并且将OPenCL代码与其他代码做隔离,但这样做不利于代码解耦和重用,扩展性也相对较差。因此百度基于这个架构做了调整和升级,也就是Paddle Lite架构。
Lite架构在算子和Kernel中插入了中间层IR Pass,IR是和算子以及Kernel无关的基于类型系统的抽象表示。引入IR之后,再采用优化手段时就可以很明确的知道优化手段处于哪个层级,也就是通过中间表示的引入可以很好的进行代码解耦。
算子要选择什么类型的Kernel受到业务多方面的影响,如设备限制、用户偏好、性能预估、预期精度、预期排布等等,开发者要综合各方面因素来确定要执行的Kernel。对于图结构来说,需要移除一些死代码,如无效算子或拓扑排序位于输出节点之后等情况下的无效算子。有些情况下要对算子做融合操作,如卷积、加法以及激光函这三个算子需要三个循环,融合之后就只需一套数据,从而起到框架优化的作用。Scope持有和管理所有资源,它随着输入网络的不同需要重新分配内存,但重新分配是有一定代价的,因此通过设置Scope重新分配的前置触发策略来实现尽量低频的触发,从而实现框架优化。2.2 GPU算子优化
除了框架层外,还可以通过算子来进行PaddleLit性能优化。算子分为GPU算子和CPU算子两种,首先来看GPU算子优化。
讲师根据自己多年的工作经验总结了PaddleGPU的7种优化手段:包含工作组动态划分、向量化操作、半精度计算、CPU逻辑分离、分支条件剪枝、数据结构选择和WinoGrad算法,其中重点介绍了分支条件剪枝、工作组优化、向量化操作和WinoGrad算法这四种优化手段。
对于GPU的多个核心而言,一部分被圈定在SSID组中,而同一个SSID组中的核心是执行同一段代码的。比如GPU有12个核心都执行if语句,如果这些核心中有部分命中了if的一个分枝,另外一些核心命中了其他分枝,那么核心之间要进行等待和同步后才可以将代码运行下去,这会造成耗时。因此尽量让SSID组的当中所有核心执行同一套代码,命中同一个分枝,以起到性能优化的作用。卷积是一个过滤子在输入的图片上进行滑窗,每次滑窗时运算一个节点。这样的操作天然体现一种并行化的结构,可以使用和输出节点大小相同的GPU核心排布来计算每一个输出的节点,下图演示了一个简单的实现。工作组优化除了卷积外,还可以通过全局指标计算和负载调整来优化。首先通过一个例子来看全局指标计算,假如有一个6X6的输入矩阵,相对矩阵所有元素做累加和,一个方法是使用一个节点采样所有64个数据然后累加,另一个方法是将矩阵进行分组,然后累加各个分组的和以计算整体数据,这种方式可以很好的发挥并行性特点。接下来看工作组负载调整,大家都知道当GPU线程组工作负载过低时,就会花费大量时间在线程切换上,因此要适当提高工作负载。问题解决思路是将多个输出节点的工作量负载到一个GPU核心上,用来提高这个核心的工作负载,这样就可以在工作负载以及线程切换之间达到平衡。可以通过将输入数据进行分组,然后对每组数据进行线量化操作,也就是通过一次操作多组数据的形式提高运算效率。可以通过WinoGrad 算法来进行了解,通过下方算法示意图可以看到,算法原型是两个矩阵相乘,要进行四次乘法以及两次加减法来完成计算过程,如果将计算结果进行进行多项式的展开以及合并同类项后会发现,实际上只需要三次乘法和五次加减法。这样做有什么好处呢?主要是在大多数体系结构中,乘法的代价是要远大于加法,所以适当的增加加法而减少乘法,某种意义上可以获得一个全局的正向收益。百度Paddle团队基于WinoGrad算法对一些常见的卷积形式进行了公式推导并把这些公式进行提取和化解,最终变成一个可以落地的代码形式,这个落地代码就是WinoGrad的工程实现,实践过程中发现收益非常明显。由此可见,当GPU无法通过工程手段进行优化时,可以考虑算法优化的形式来达到同样的目的。2.3 CPU算子优化
这部分主要汇总了Padlle团队常用单独优化手段,涉及ARM汇编、Neon指令、LoopUnrolling + 流水线重排、缓存预充 + 缓存排布优化、核心算子Int8化、大小核心绑定 + 多线程OpenMP优化、WinoGrad算法等7个方面。此外还可以通过量化手段进行优化,比如当问题空间是基于float32进行预算时,可以将float32空间量化成int8空间,也就是通过降低精度来实现高效的、大规模的计算。
CPU中最快的存取单元是寄存器,往下有L1缓存、L2缓存以及内存级的缓存等,所有缓存间都存在读写的速度差异。假设每一个层级有十倍的差异,当一些数据在计算器中是miss状态时,想要在内存当中读取数据的话可能会受到上百倍的速度屏障。如何解决这个问题呢?接下来通过卷积运算被化简成矩阵乘法的例子来说明。矩阵乘法天然具有子问题结构,可以通过加速子问题结构来实现整体的优化。如图所示,当要计算绿色块时,可以看做是A的某些行和B的某些列根据矩阵乘法得到的,形象的看就是如紫色行拿出一块,黄色列拿出一块,这两个块按照矩阵法进行运算从而贡献了的绿色块的一部分,这个小型的输入是可以塞入到L1缓存和L2缓中的,这样的话就可以对子问题进行缓存预处理加速。CPU运行过程中指令是天然并行化的,而计算机体系结构中一个指令的执行并不是原子操作,需要由多个流水线操作组合而成,因此要充分利用这个并行化过程。以缓存预充的例子来说明,采用一边读取一边计算的方式要优于将所有数据读取完成后再计算,因为第一种方法可以将读和计算进行分组,组与组之间没有耦合关系,但又在组内又相互依赖,最终起到更好的运算效果。2.4 模型裁剪与搜索
百度团队采用了粗筛和精筛结合的方式来进行模型的剪裁和搜索。大家都知道模型有很多种,但是模型的基本组成算子是不变的,可以先对算子给出一个非常精准的基于真机的打分,根据算子的打分大概估算出模型打分,用这样的预估打分进行粗筛,经过粗筛后可能已经由上万个模型变为上百个模型,这时候再利用真机给出基于真机的模型打分,这样就可以选出真正符合预期的模型了。
本文集合了百度Paddle团队多年的性能优化经验,希望通过阅读本文可以为开发者带来一些新的方向和思路。
转发本篇文章至朋友圈,并附上文案“#文末有福利,爱奇艺月卡免费领取啦#本文集合了百度Paddle团队多年的性能优化经验,希望通过阅读本文可以为开发者带来一些新的方向和思路。”朋友圈保留到3月26日(本周四)哦,3月26日16点前将截图发送至“软件绿色联盟”公众号后台,截图内容需要有“文案+转发文章的时间+转发文章链接”。
绿盟君随机抽取10名幸运用户免费送爱奇艺月卡一张。仅限10张哦。快去转发吧!经核实后,爱奇艺月卡会在3月27日19点前统一发放。
·END·
本文分享自微信公众号 - 软件绿色联盟(sgachina)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
以上是 深度长文|百度PaddleLite性能进化之路! 的全部内容,
来源链接:
utcz.com/z/509267.html