从HPA到KPA:Knative自动扩缩容深度分析
上篇文章主要聊的是流量和网络问题,这里我们探讨一下另外一个Knative的核心功能:自动扩缩容。本文只打算围绕一个核心的问题进行深入分析,即如何设计一个自动扩缩容系统,以及Knative又是如何实现的?
如何设计一个自动扩缩容系统
自动扩缩容其实是一个相对广义的概念,这里我们只关注服务副本数的自动扩缩容,集群扩缩容和VPA则不会涉及。
假设一下,如果让我们自研一个完善的自动扩缩容系统,会如何去实现呢?首先大致可以将要解决的问题抽象成以下几点:
- 有哪些Metrics数据来决定扩缩容?
- 如何采集这些Metrics数据?
- 如何设计一个合理的自动扩缩容算法?
在Kubernetes集群下的自动扩缩容,很多人马上会联想到HPA,如果基于HPA来设计一个自动扩缩容系统,会面临什么样的挑战?
1. 有哪些Metrics数据
HPA v1版本可以根据服务的CPU使用率来进行自动扩缩容。但是并非所有的系统都可以仅依靠CPU或者Memory指标来扩容,对于大多数 Web 应用的后端来说,基于每秒的请求数量进行弹性伸缩来处理突发流量会更加的靠谱,所以对于一个自动扩缩容系统来说,我们不能局限于CPU、Memory基础监控数据,每秒请求数RPS等自定义指标也是十分重要。
幸运的是,HPA V2版本已经支持custom Metrics自定义指标。
Custom Metrics其实只是一个Kubernetes的接口,实际Metrics数据的提供,需要额外的扩展实现,可以自己写一个(参考:https://github.com/kubernetes-sigs/custom-Metrics-apiserver)或者使用开源的Prometheus adapter。如果自己实现custom-Metrics,可以自定义各种Metrics指标,使用Prometheus adapter则可以使用Prometheus中现有的一些指标数据。
2. 如何采集Metrics数据
如果我们的系统默认依赖Prometheus,自定义的Metrics指标则可以从各种数据源或者exporter中获取,基于拉模型的Prometheus会定期从数据源中拉取数据。
假设我们优先采用RPS指标作为系统的默认Metrics数据,可以考虑从网关采集或者使用注入Envoy sidecar等方式获取工作负载的流量指标。
3. 如何自动扩缩容
K8s的HPA controller已经实现了一套简单的自动扩缩容逻辑,默认情况下,每30s检测一次指标,只要检测到了配置HPA的目标值,则会计算出预期的工作负载的副本数,再进行扩缩容操作。同时,为了避免过于频繁的扩缩容,默认在5min内没有重新扩缩容的情况下,才会触发扩缩容。
不过,HPA本身的算法相对比较保守,可能并不适用于很多场景。例如,一个快速的流量突发场景,如果正处在5min内的HPA稳定期,这个时候根据HPA的策略,会导致无法扩容。
另外,在一些Serverless场景下,有缩容到0然后冷启动的需求,但HPA默认不支持。
关于HPA支持缩容至0的讨论,可以参考issues(
https://github.com/kubernetes/kubernetes/issues/69687),该PR(https://github.com/kubernetes/kubernetes/pull/74526)已经被merge,后面的版本可以通过featureGate设置开启,不过该功能是否应该由K8s本身去实现,社区仍然存在一些争议。
如果我们的系统要实现支持缩容至0和冷启动的功能,并在生产环境真正可用的话,则需要考虑更多的细节。例如HPA是定时拉取Metrics数据再决定是否扩容,但这个时间间隔即使改成1s的话,对于冷启动来说还是太长,需要类似推送的机制才能避免延迟。
总结一下,如果基于现有的HPA来实现一套Serverless自动扩缩容系统,并且默认使用流量作为扩缩容指标,大致需要:
- 考虑使用网关等流量入口来实现流量Metrics的指标检测,并暴露出接口,供Prometheus或者自研组件来采集。
- 使用Prometheus adapter或者自研Custom Metrics的K8s接口实现,使得HPA controller可以获取到具体的Metrics数据。
这样便可以直接使用HPA的功能,实现了一个最简单的自动扩缩容系统。但是,仍然存在一些问题,比较棘手的是:
- HPA无法缩容至0,也无法实现工作负载的冷启动。
- HPA的扩容算法不一定适用流量突发场景,存在一定的隐患。
我们接下来一起探究一下Knative的实现,以及思考为什么Knative要这么设计,是不是有更好更优雅的方案呢?
Knative的自动扩缩容实现
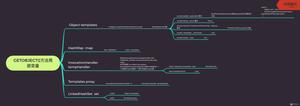
Knative相关组件
这里我们只关心数据面的组件:
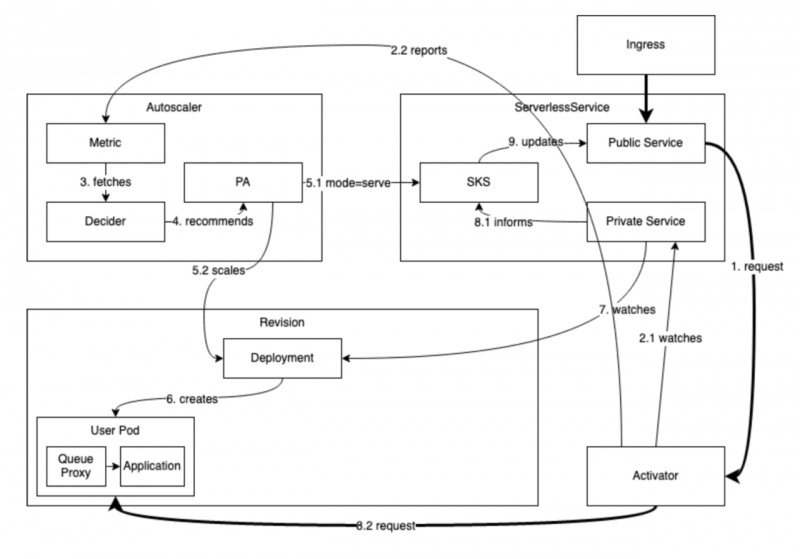
Queue-proxy
针对每个业务容器Knative都会自动注入一个sidecar容器,本质上是一个基于Golang的反向代理服务,主要功能是检测流量,暴露出RPS和concurrency数据供Autoscaler组件采集。另外,如果用户配置containerConcurrency,还会限制单个容器的并发请求数,超过并发数的请求,会被缓存下来放入队列,这也是Queue-proxy名称的含义。
Autoscaler
Autoscaler是自动扩缩容的核心控制组件,主要功能是采集Queue-proxy的Metrics数据,然后对比配置的数据,计算出预期的副本数,最后进行扩缩容操作。
Activator
Activator的引入,最开始的目的是在冷启动的时候,由于服务副本数为0,需要有一个组件来保持住请求,通知Autoscaler扩容对应的服务,然后再将请求发送至运行后的服务。除此之外,还承担了当流量瞬间突增的时候,缓存请求,等扩容完成后再代理发送至后端服务的功能。
有哪些Metrics数据?
HPA的Metrics来源一般是Pod的CPU或者Memory,当然也支持自定义的Metrics数据,不过对于大部分在线业务来说,并非CPU密集型,而是IO密集型,这意味着单纯依赖CPU来自动扩缩容往往并不满足实际需求,可能工作负载接收的流量已经很大了,延迟已经很高了,但是HPA还没有帮我们扩容服务。
为了更好的满足这种情况,Knative KPA自动扩缩容则设计支持了请求并发(concurrency)和RPS(request-per-second)两种Metrics数据,相比CPU数据,这两者更贴近负载的load,更适合描述在线业务。数据源来自Activator组件和每个工作负载Pod,当然工作负载的Pod数据由Queue-proxy sidecar暴露出Metrics接口。
RPS比较好理解,在一个采集周期内(默认1s),来一次http request,计数加1即可,比如1s内检测到来了100个请求,那么RPS就是100。
Concurrency可以理解为一个采集周期内正在处理http request的数量,比如1s内有50个请求正在被处理则Concurrency为50。实际上Knative会记录request来的时刻和返回的时刻,如果1s内只有一个请求,并且处理了500ms即返回,则Concurrency为0.5。
Metrics是如何被采集的?
我们都知道Prometheus为pull拉模型,即服务本身提供Metrics接口,供Prometheus去拉取监控数据。
对于工作负载Pod而言,Queue-proxy sidecar承担了检测请求流量的职责,Autoscaler会从中拉取concurrency和RPS数据。
但是Activator则不同,Activator通过和Autoscaler组件建立websocket连接,使用push的方式将Metrics数据定时推到Autoscaler组件中。
如果Activator检测到流量是请求到一个副本数为0的负载,则会推送一个带有poke标记的Metrics数据到Autoscaler,Autoscaler会马上扩容负载,相比拉模式,这种推送push的方式会减少冷启动延迟。这也是Knative设计者在Activator这里采用push的方式的一个重要原因。
整体数据链路图如下所示:
KPA算法
虽然Knative本身也支持HPA,但这里我们还是只关心默认使用的KPA,我们可以简单的把KPA认为是区别于HPA的Knative自动扩缩容的方式。
Autoscaler的KPA算法本质上就是计算出多少个Pod可以满足现在的流量需求,计算逻辑便是在一个无限循环中,每隔2s触发一次,最核心的逻辑如下所示:
desiredPodCount = metricInSystem / targetPerPod例如,检测到一共有100个并发请求,我们目标是每个Pod处理5个并发,那么期望的Pod数为100/5=20个。
当然实际的处理逻辑不会这么简单粗暴,还需要考虑不能超过配置的Pod最大副本数等等。
另外,KPA还设计了Stable和Panic模式,主要是为了区分和解决正常情况和流量突发的场景,避免流量突发时扩容不及时。
默认Stable为60s(可配置)的时间窗口,Panic时间窗口默认为10%即6s。
正常情况下,Autoscaler使用Stable时间窗口去聚合Metrics数据并计算期望的Pod个数。在一个60s的窗口周期内计算平均值,可以避免Pod过于频繁的扩缩容。
但是如果突发流量,6s内检测到的指标超过目前能处理的200%(可配置),则会进入Panic模式,在更短的时间内快速扩容Pod副本数。是否进入Panic模式可参考如下公式:
isPanic = metricInSystempanic / (readyPods * targetPerPod) >= panicThreshold例如,检测到系统有100个并发请求(metricInSystempanic=100),目前有5个正在运行的Pod(readyPods=5)并且目标是每个Pod处理10个并发(targetPerPod=10),默认配置的进入Panic模式阈值为200%(panicThreshold=2),则根据如上公式:
100 / (5 * 10) >= 2即会进入Panic模式。
突发流量
相比HPA,Knative会考虑更多的场景,其中一个比较重要的是流量突发的时候。
除了Autoscaler会进入Panic模式更快的去扩容外,上面也提到过Activator和Queue-proxy本身也带有缓存请求的功能,这个功能的目的也是为了在请求流量突发来不及处理时,进行缓存再转发。但是非冷启动情况下的请求缓存,会被视为一种迫不得已的兜底行为,同时会带来一定的请求时延。
Knative中会有很多的配置,可以调整用于突发流量的场景。下面为常见的配置项:
- container concurrency:容器并发度,如果设置为0,则视为不限制容器并发。
- target utilization:目标使用率,达到该使用率后会被视为达到容器的并发度,会触发扩容。
- target burst capacity (TBC) :可容忍的请求爆发容量,这个参数比较关键而且不太好理解。
举一个例子,假设我们的容器container concurrency被设置为50,目标使用率target utilization为80%,即每个容器目标是接收50*80%=40的并发请求,TBC设置为100。当有180的并发请求进来后,我们很容易算出最终会被扩容为5个副本(这里会按照目标请求40来计算),但实际上5个副本的最大容量为5*50=250个并发请求,则实际剩余可容忍的爆发为250-180=70个并发。
当剩余可容忍的并发小于TBC时,Knative会让流量经过Activator,而不是直接发送到后端服务,那么在这个例子中,由于70<TBC=100,此时相当于Knative认为剩余的爆发请求容量不足以支撑目标的可容忍容量(TBC),所以流量全部都会走到Activator再进行负载均衡转发,因为Activator可以感知到哪些容器目前接收的请求已经达到极限,哪些容器却还能继续接收更多请求。
同时,如果在示例的场景中,再突然进来了100个请求,在扩容来不及的情况下,Activator会代理70个请求到后端服务,同时缓存30个请求,等后端服务有更多容量时再转发处理。
由此可见,Activator缓存请求并非只是在冷启动时,在突发流量场景下,Activator也会起到相同的作用,而冷启动其实只是后端服务副本为0的一种特殊场景而已。
从上面的分析可以看出,TBC参数十分重要,会影响到什么时候请求流量会经过Activator,什么时候则直接从网关到后端。但是,如果在非冷启动的时候,流量也经过Activator,增加了一层链路,对于延迟敏感的服务,有点得不偿失。
那TBC应该设置成多少呢?这对于很多人来说,也是一个头疼的问题。
这里给出一些参考:
- 对于非CPU密集型的服务,例如常规的web应用、静态资源服务等,建议直接将TBC设置为0,同时container concurrency也设置为0,即不限制容器的请求并发。
当TBC=0时,系统剩余的可爆发请求容量会永远大于TBC,也意味着除了冷启动的时候,请求流量永远不会走到Activator,同时我建议设置Knative Service的最小保留副本数为1,这样Activator组件其实都不会被用到,也减少了一层链路。
其实,我们使用Serverless的时候,很多的服务都是常规的在线业务,使用如上的配置,可以最小化请求延迟,增大RPS。
- 对于非常CPU密集型的服务、单线程等极端场景的服务,需要严格限制单个容器的请求并发,一般都需要设置container concurrency<5,此时建议设置TBC=-1,因为这种场景下往往扩容等不及请求流量的突增。
当TBC=-1,也意味着所有的请求,都会走到Activator,Activator会重新转发请求或者缓存超额的请求,这个时候的Activator组件在非冷启动情况下就有存在的价值。
- 对于除了上述两种情况,还需要限制一些并发请求的场景,此时一般container concurrency>5,建议设置TBC为一个预期的值,例如100,至于这个值具体设置多少,需要系统管理员根据实际的场景去评估。
思考
根据上述的分析,为什么Knative要抛弃HPA现有的实现,重新设计一个自动扩缩容系统呢?
大概主要有以下的原因:
- HPA本身扩缩容算法实现简单,不一定能满足所有需求,所以Knative提供了Autoscaler组件,提供了更加自定义的扩容算法。
- HPA默认不支持缩容至0和冷启动,这也是Activator的主要能力。
但是,Knative的现状就是合适和最理想的吗?这个值得我们更多的思考。
首先,KPA完全是定制化的,虽然HPA可以支持自定义指标的扩缩容,但HPA无法采用KPA的Metrics数据,二者比较割裂。如下图所示:
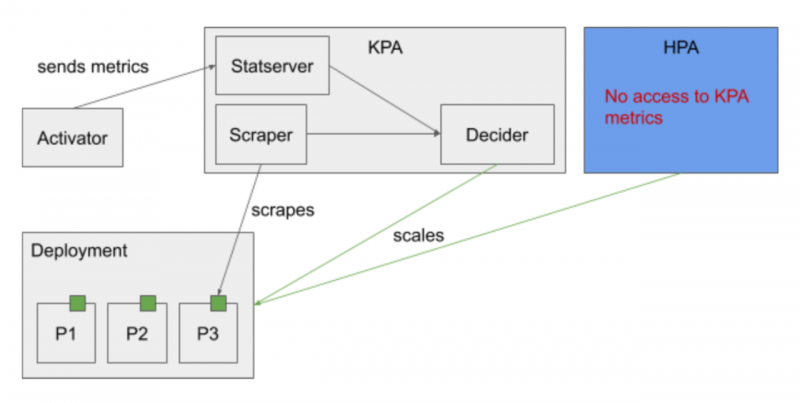
并且,KPA也只能支持PRS和Concurrency两种指标,无法接入用户自定义的其他指标。另外,虽然KPA可配置自动扩缩容算法的很多参数,但仍然缺乏可扩展性和可定制性。
不过,社区也意识到了这些问题,并在一步步的优化和改进。毕竟相比K8s,Knative还很年轻,相信随着时间推移,Knative会越来越完善和强大,成为Serverless领域的事实标准或许就在不远的前方。
以上是 从HPA到KPA:Knative自动扩缩容深度分析 的全部内容, 来源链接: utcz.com/a/29102.html