人脸识别(基于Caffe)

人脸识别(基于Caffe, 来自tyd)
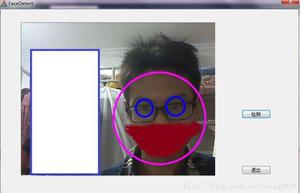
人脸识别(判断是否为人脸)
LMDB(数据库, 为Caffe支持的分类数据源)
mkdir face_detectcd face_detectmkdir train valmkdir train/{0,1}mkdir val/{0,1}- 将人脸数据放到
train/1和val/1下 - 将非人脸数据放到
val/0和val/0下 vim train.txt
0/xxx.jpg 0
1/xxx.jpg 1
vim val.txt
1/xxx.jpg 1
0/xxx.jpg 0
- 拷贝Caffe自带的脚本根据上面的train.txt和val.txt制作LMDB数据源, 名为
face_detect_lmdb.sh
# 修改部分EXAMPLE=/home/jh/face_detect
DATA=/home/jh/face_detect
TOOLS=caffe安装目录/build/tools
TRAIN_DATA_ROOT=/home/jh/face_detect/train/
VAL_DATA_ROOT=/home/jh/face_detect/val/
# 对输入的数据进行大小的调整, 大小的调整是要根据我们要使用的网络模型, 比如AlexNet或者VGG(速度慢)为227x227
RESIZE=true
if $RESIZE; then
RESIZE_HEIGHT=227
RESIZE_WIDTH=227
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0
fi
# 接着修改GLOG_logtostderr那里的$DATA/train.txt, 这个为那个train.txt, $EXAMPLE/face_train_lmdb, 这个为生成的lmdb数据源的位置
# 下面也一样, 修改为val.txt, $EXAMPLE/face_val_lmdb, 这个为val的lmdb数据源生成的位置
- 指定
face_detect_lmdb.sh脚本文件, 如果那些face_val_lmdb已经存在则直接报错, 在执行过程中, 可能会出现Could not open ..., 这个没有关系, 执行的细节为, 先配置train, 在配置val - 因为数据源很大, 大约4W, 我们生成的lmdb文件为好几个GB, 再提一下, model大概为好几百MB
模型调优
- 选择更深的网络, 改用VGG-16
- 调整学习率
- 图像增强
训练AlexNet网络(忘了, 去网上找AlexNet的结构图)
- 对AlexNet进行简单的修改, 对最后的全连接层从1000改为2
- 创建train.prototxt文件, 在里面写神经网络结构
- 创建solver.prototxt文件
- 指定
test_iter, 测试多少个batch test_interval: 1000, 迭代1000次进行测试base_lr: 0.001: 基础学习率max_iter: 10000: 最大迭代次数gamma: 0.1stepsize: 20000display: 1000: 每1000次迭代显示一次momentum: 0.9weight_decay: 0.0005snapshot: 10000: 每个10000次保存一次modelsnapshot_prefix: "/path/to/model": 模型保存的目录solver_mode: CPU: 使用CPU还是GPU
- 指定
执行模型
- 创建一个train.sh脚本
/path/to/caffe train --solver=/path/to/solver.prototxt
sh train.sh执行- 结束会生成一个模型文件(就一个, 就可以直接拿来用了)
网络训练速度限制
- 网络大小
- 输入数据的大小, 图片大小
人脸检测
Multi-Scale变换
- 进行多个Scale变换->会导致有多个bbox, 后续需要NMS
- 保存原始的bboxes, 在后续的时候通过scale factor映射到原始图形上
滑动窗口
- 多尺度的Scale变换, 对小人脸(如50x50)进行放大转为224x224, 对大脸进行缩小; 对原始图像进行多此缩放, 也就是不断的乘以scale factor知道到一个临界值, 变成一个图像金字塔
以上是 人脸识别(基于Caffe) 的全部内容, 来源链接: utcz.com/z/508902.html