HiveonMR调优

当HiveQL跑不出来时,基本上是数据倾斜了,比如出现count(distinct),groupby,join等情况,理解 MR 底层原理,同时结合实际的业务,数据的类型,分布,质量状况等来实际的考虑如何进行系统性的优化。
Hive on MR 调优主要从三个层面进行,分别是基于MapReduce优化、Hive架构层优化和HiveQL层优化。
MapReduce调优
如果能够根据情况对shuffle过程进行调优,对于提供MapReduce性能很有帮助。一个通用的原则是给shuffle过程分配尽可能大的内存,当然你需要确保map和reduce有足够的内存来运行业务逻辑。因此在实现Mapper和Reducer时,应该尽量减少内存的使用,例如避免在Map中不断地叠加。
运行map和reduce任务的JVM,内存通过mapred.child.java.opts属性来设置,尽可能设大内存。容器的内存大小通过mapreduce.map.memory.mb和mapreduce.reduce.memory.mb来设置,默认都是1024M。
1 map调优
在map阶段主要包括:数据的读取、map处理以及写出操作(排序和合并/sort&merge),其中可以针对spill文件输出数量、Combiner的merge过程和数据压缩进行优化,避免写入多个spill文件可能达到最好的性能,一个spill文件是最好的。通过估计map的输出大小,设置合理的mapreduce.task.io.sort.*属性,使得spill文件数量最小。例如尽可能调大mapreduce.task.io.sort.mb。其次增加combine阶段以及对输出进行压缩设置进行mapper调优。
(1) 合理设置map数
在执行map函数之前会先将HDFS上文件进行分片,得到的分片做为map函数的输入,所以map数量取决于map的输入分片(inputsplit),一个输入分片对应于一个map task,输入分片由三个参数决定:
参数名 默认值 备注dfs.block.size 128M HDFS上数据块的大小
mapreduce.
min.split.size 0 最小分片数mapreduce.
max.split.size 256M 最大分片数公式:分片大小=max(mapreduce.min.split.size,min(dfs.block.size, mapreduce.max.split.size)),默认情况下分片大小和dfs.block.size是一致的,即一个HDFS数据块对应一个输入分片,对应一个map task。这时候一个map task中只处理一台机器上的一个数据块,不需要将数据跨网络传输,提高了数据处理速度。
(2)spill文件输出数量
--用于mapper输出排序的内存大小,调大的话,会减少磁盘spill的次数,此时如果内存足够的话,一般都会显著提升性能mapreduce.task.io.sort.mb(default:100)
--开始spill的缓冲池阀值,默认0.80,spill一般会在Buffer空间大小的80%开始进行spill
mapreduce.map.sort.spill.percent(default:0.80)
(3)combine(排序和合并/sort&merge)
--运行combiner的最低文件数,与reduce共用;调大来减少merge的次数,从而减少磁盘的操作;mapreduce.task.io.sort.factor(default:10)
--spill的文件数默认情况下由三个的时候就要进行combine操作,最终减少磁盘数据;
min.num.spill.for.combine 默认是3
(4)压缩设置
--设置为true进行压缩,数据会被压缩写入磁盘,,压缩一般可以10倍的减少IO操作mapreduce.map.output.compress(default:false)
--压缩算法,推荐使用SnappyCodec;
mapreduce.map.output.compress.codec(default:org.apache.hadoop.io.compress.DefaultCodec)
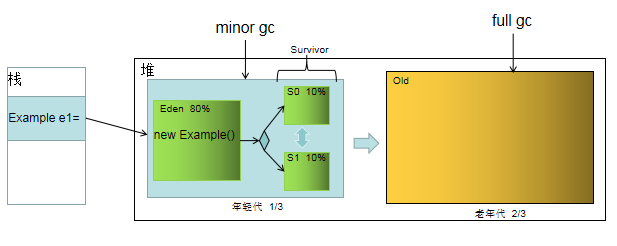
2 reduce调优
在reduce端,如果能够让所有数据都保存在内存中,可以达到最佳的性能。通常情况下,内存都保留给reduce函数,但是如果reduce函数对内存需求不是很高,将mapreduce.reduce.merge.inmem.threshold(触发合并的map输出文件数)设为0,mapreduce.reduce.input.buffer.percent(用于保存map输出文件的堆内存比例)设为1.0,可以达到很好的性能提升。在2008年的TB级别数据排序性能测试中,Hadoop就是通过将reduce的中间数据都保存在内存中胜利的。
(1)对mapper端输出数据的获取
--mr程序reducer copy数据的线程数。当map很多并且完成的比较快的job的情况下调大,有利于reduce更快的获取属于自己部分的数据mapreduce.reduce.shuffle.parallelcopies 默认5
(2)数据合并(sort&merge)
--reduce复制map数据的时候指定的内存堆大小百分比,适当的增加该值可以减少map数据的磁盘溢出,能够提高系统能。mapreduce.reduce.shuffle.input.buffer.percent 默认0.70;
--reduce进行shuffle的时候,用于启动合并输出和磁盘溢写的过程的阀值。
--如果允许,适当增大其比例能够减少磁盘溢写次数,提高系统性能。同mapreduce.reduce.shuffle.input.buffer.percent一起使用。
mapreduce.reduce.shuffle.merge.percent 默认0.66;
(3)reduce处理以及写出操作
--reduce函数开始运行时,内存中的map输出所占的堆内存比例不得高于这个值,默认情况内存都用于reduce函数,也就是map输出都写入到磁盘set mapreduce.reduce.input.buffer.percent 默认0.0;
--开始spill的map输出文件数阈值,小于等于0表示没有阈值,此时只由缓冲池比例来控制
set mapreduce.reduce.merge.inmem.threshold 默认1000;
--服务于reduce提取结果的线程数量
mapreduce.shuffle.max.threads 默认0;
--修改reducer的个数,可以通过job.setNumReduceTasks方法来进行更改。
mapreduce.job.reduces 默认为1;
(4)合理设置reduce数
reduce数决定参数
参数名 默认值 备注hive.
exec.reducers.bytes.per.reducer 1G 一个reduce数据量的大小hive.
exec.reducers.max999 hive 最大的个数mapred.reduce.tasks
-1 reduce task 的个数,-1 是根据hive.exec.reducers.bytes.per.reducer 自动调整所以可以用set mapred.reduce.tasks手动调整reduce task个数。
Hive架构层优化
1 不执行mapreduce
hive从HDFS读取数据,有两种方式:启用mapreduce读取、直接抓取。
set hive.fetch.task.conversion=more
hive.fetch.task.conversion参数设置成more,可以在 select、where 、limit 时启用直接抓取方式,能明显提升查询速度。
2 本地执行mapreduce
hive在集群上查询时,默认是在集群上N台机器上运行,需要多个机器进行协调运行,这个方式很好地解决了大数据量的查询问题。但是当hive查询处理的数据量比较小时,其实没有必要启动分布式模式去执行,因为以分布式方式执行就涉及到跨网络传输、多节点协调等,并且消耗资源。这个时间可以只使用本地模式来执行mapreduce job,只在一台机器上执行,速度会很快。
3 JVM重用
因为hive语句最终要转换为一系列的mapreduce job的,而每一个mapreduce job是由一系列的map task和Reduce task组成的,默认情况下,mapreduce中一个map task或者一个Reduce task就会启动一个JVM进程,一个task执行完毕后,JVM进程就退出。这样如果任务花费时间很短,又要多次启动JVM的情况下,JVM的启动时间会变成一个比较大的消耗,这个时候,就可以通过重用JVM来解决。这个设置就是制定一个jvm进程在运行多次任务之后再退出,这样一来,节约了很多的 JVM的启动时间。
--JVM重用特别是对于小文件场景或者task特别多的场景set mapred.job.reuse.jvm.num.tasks=10;
--启动JVM虚拟机时,传递给虚拟机的启动参数,表示这个 Java 程序可以使用的最大堆内存数,一旦超过这个大小,JVM 就会抛出 Out of Memory 异常,并终止进程。
--设置的是 Container 的内存上限,这个参数由 NodeManager 读取并进行控制,当 Container 的内存大小超过了这个参数值,NodeManager 会负责 kill 掉 Container。
--mapreduce.map.java.opts一定要小于mapreduce.map.memory.mb。
mapreduce.map.java.opts 默认 -Xmx200m;
mapreduce.map.memory.mb
--同上
mapreduce.reduce.java.opts;
mapreduce.map.java.opts;
--是否启动map阶段的推测执行,其实一般情况设置为false比较好。可通过方法job.setMapSpeculativeExecution来设置。
mapreduce.map.speculative 默认为true;
--是否需要启动reduce阶段的推测执行,其实一般情况设置为fase比较好。可通过方法job.setReduceSpeculativeExecution来设置。
mapreduce.reduce.speculative 默认为true;
4 并行化
一个hive sql语句可能会转为多个mapreduce job,每一个job就是一个stage,这些 job 顺序执行,这个在hue的运行日志中也可以看到。但是有时候这些任务之间并不是是相互依赖的,如果集群资源允许的话,可以让多个并不相互依赖stage并发执行,这样就节约了时间,提高了执行速度,但是如果集群资源匮乏时,启用并行化反倒是会导致各个job相互抢占资源而导致整体执行性能的下降。
--开启任务并行执行set hive.exec.parallel=true;
--同一个sql允许并行任务的最大线程数
set hive.exec.parallel.thread.number 默认为8;
HiveQL调优
1 利用分区表优化
分区表是在某一个或者某几个维度上对数据进行分类存储,一个分区对应于一个目录。在这中的存储方式,当查询时,如果筛选条件里有分区字段,那么hive只需要遍历对应分区目录下的文件即可,不用全局遍历数据,使得处理的数据量大大减少,提高查询效率。
当一个hive表的查询大多数情况下,会根据某一个字段进行筛选时,那么非常适合创建为分区表。
2 利用桶表优化
就是指定桶的个数后,存储数据时,根据某一个字段进行哈希后,确定存储再哪个桶里,这样做的目的和分区表类似,也是使得筛选时不用全局遍历所有的数据,只需要遍历所在桶就可以了。
hive.optimize.bucketmapJOIN=true;hive.input.format
=org.apache.hadoop.hive.ql.io.bucketizedhiveInputFormat; hive.optimize.bucketmapjoin
=true; hive.optimize.bucketmapjoin.sortedmerge
=true;3 对于整个sql的优化
(1)where 条件优化
where只在map端阶段执行,不会在reduce阶段执行,尽早地过滤数据,减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使用到的字段。
(2)join优化
① 优先过滤后再join,最大限度地减少参与join的数据量。② 小表join大表原则
应该遵守小表join大表原则,原因是join操作的reduce阶段,位于join左边的表内容会被加载进内存,将条目少的表放在左边,可以有效减少发生内存溢出的几率。join中执行顺序是从做到右生成job,应该保证连续查询中的表的大小从左到右是依次增加的。
③
join on条件相同的放入一个job hive中,当多个表进行join时,如果join on的条件相同,那么他们会合并为一个mapreduce job,所以利用这个特性,可以将相同的join on的放入一个job来节省执行时间。
select pt.page_id,count(t.url) PV
from rpt_page_type pt
join (select url_page_id,url from trackinfo where ds='2016-10-11' ) t on pt.page_id=t.url_page_id
join (select page_id from rpt_page_kpi_new where ds='2016-10-11' ) r on t.url_page_id=r.page_id groupby pt.page_id;④Common
/shuffle/Reduce JOIN发生在reduce 阶段, 适用于大表 连接 大表(默认的方式)
⑤Map
JOIN连接发生在map阶段 ,适用于小表 连接 大表,大表的数据从文件中读取,小表的数据存放在内存中(hive中已经自动进行了优化,自动判断小表,然后进行缓存)
set hive.auto.convert.join=true; ⑥SMB
JOIN,Sort -Merge -Bucket Join 对大表连接大表的优化,用桶表的概念来进行优化。在一个桶内发送生笛卡尔积连接(需要是两个桶表进行join)
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;(3) Group By数据倾斜优化
Group By很容易导致数据倾斜问题,因为实际业务中,通常是数据集中在某些点上,这也符合常见的2/8原则,这样会造成对数据分组后,某一些分组上数据量非常大,而其他的分组上数据量很小,而在mapreduce程序中,同一个分组的数据会分配到同一个reduce操作上去,导致某一些reduce压力很大,其他的reduce压力很小,这就是数据倾斜,整个job 执行时间取决于那个执行最慢的那个reduce。
解决这个问题的方法是配置一个参数:set hive.groupby.skewindata=true。 当选项设定为true,生成的查询计划会有两个MR job。第一个MR job 中,map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。
(4) Order By 优化
因为order by只能是在一个reduce进程中进行的,所以如果对一个大数据集进行order by,会导致一个reduce进程中处理的数据相当大,造成查询执行超级缓慢。
(5)mapjoin
mapjoin是将join双方比较小的表直接分发到各个map进程的内存中,在map进程中进行join操作,这样就省掉了reduce步骤,提高了速度。
但慎重使用mapjoin,一般行数小于2000行,大小小于1M(扩容后可以适当放大)的表才能使用,小表要注意放在join的左边。否则会引起磁盘和内存的大量消耗。
(6) 桶表mapjoin
当两个分桶表join时,如果join on的是分桶字段,小表的分桶数时大表的倍数时,可以启用map join来提高效率。启用桶表mapjoin要启用hive.optimize.bucketmapjoin参数。
(7) 消灭子查询内的 group by 、 COUNT(DISTINCT),MAX,MIN。 可以减少job的数量。
(8) 不要使用count (distinct cloumn) ,改使用子查询。
(9) 如果union all的部分个数大于2,或者每个union部分数据量大,应该拆成多个insert into 语句,这样会提升执行的速度。尽量不要使用union (union 去掉重复的记录)而是使用 union all 然后在用group by 去重。
(10) 中间临时表使用orc、parquet等列式存储格式。
(11) Join字段显示类型转换。
(12) 单个SQL所起的JOB个数尽量控制在5个以下。
以上是 HiveonMR调优 的全部内容, 来源链接: utcz.com/z/508745.html