Java用广度优先搜索快速搜索文件

背景
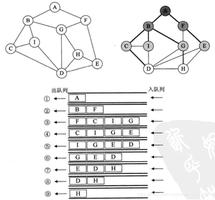
在开发的过程中,经常需要在文件系统里按某些条件搜索文件,比如音乐播放器扫描音乐,而搜索文件,大多人喜欢用递归的方式,而这也是最容易想到的方式。递归方式如果文件夹很深就容易造成栈溢出,而且不断的压栈退栈也会使搜索效率变低。我们常用的文件通常不会放在太深的文件夹,我们应该一层一层下去搜索,放在浅层目录先被搜索,如果实时显示结果,得到想要的结果即停止,用广度优先搜索的优势就更能体现出来了。
|--E:/ |--Music/
|--pop/
|--Jay/
|--Leehom Wang/
|--rock/
|--beyond/
|--QQ/
|--q.mp3
|--k.mp3
假设有以上的目录结构,E:/是要搜索的根目录,搜索的的内容是后缀为mp3的文件,名称加斜杠的表示文件夹,只有名称的表示文件。
1. 如果用递归,它会依次搜索Music->pop-> LeehomWang->rock->beyond->QQ然后才到我们mp3文件,假设Music这个目录很深,它会一直搜下去,而我们在浅层目录的MP3文件却要等到最后才搜到。
2. 如果用广度优先搜索,我们一下子就可以搜索到我们的MP3文件,而且不需要压栈和退栈,如果文件夹数很多明显可以加快搜索速度。
总之在文件搜索时用广度优先搜索优于深度优先搜索(递归)
代码
/** * 广度优先搜索文件或文件夹
* @param path 要搜索的目录
* @param regex 搜索的通配符
* @param isDisplyDir 是否在搜索结果中显示文件夹
* @param isDisplayFile 是否在搜索结果中显示文件
*/
private static void bfsSearchFile(String path,String regex,boolean isDisplyDir,boolean isDisplayFile)
{
if(!(isDisplayFile||isDisplyDir))
{
throw new IllegalArgumentException("isDisplyDir和isDisplayFile中至少要有一个为true");
}
Queue<File> queue=new LinkedList<>();
File[] fs=new File(path).listFiles();
//遍历第一层
for(File f:fs)
{
//把第一层文件夹加入队列
if(f.isDirectory())
{
queue.offer(f);
}
else
{
if(f.getName().matches(regex)&&isDisplayFile)
{
System.out.println(f.getName());
}
}
}
//逐层搜索下去
while (!queue.isEmpty()) {
File fileTemp=queue.poll();//从队列头取一个元素
if(isDisplyDir)
{
if(fileTemp.getName().matches(regex))
{
System.out.println(fileTemp.getAbsolutePath());
}
}
File[] fileListTemp=fileTemp.listFiles();
if(fileListTemp==null)
continue;//遇到无法访问的文件夹跳过
for(File f:fileListTemp)
{
if(f.isDirectory())
{
queue.offer(f);////从队列尾插入一个元素
}
else
{
if(f.getName().matches(regex)&&isDisplayFile)
{
System.out.println(f.getName());
}
}
}
}
}
以上是 Java用广度优先搜索快速搜索文件 的全部内容, 来源链接: utcz.com/z/393060.html