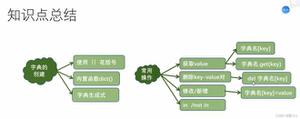
python容器类型:列表,字典,集合等

容器的概念我是从C++的STL中学到的
什么是容器?
容器是用来存储和组织其他对象的对象。
也就是说容器里面可以放很多东西,这些东西可以是字符串,可以是整数,可以是自定义类型,然后把这些东西有组织的存放在内存中。
但是C++有一点就是容器要事先定义好类型,也就是一开始是字符串的后面都只能放字符串。
但是python的容器里面可以放任何类型
li=[1,\'a\']for i in li:
print(type(i))
得出
<class \'int\'>
<class \'str\'>
容器有哪些?
以C++的STL为例,容器有向量(vector),列表(list),数组(array),队列(queue),双向队列(deque),栈(stack),集合(set),映射(map)等
那python里面也一样,有列表(list),元祖(tuple),集合(set),字典(dict),队列(queue)等
容器通常配有迭代器(iter),迭代器是用来遍历容器的利器
下面来看看python每个容器的详细功能,对照C++的STL:
列表(list)
python的列表的特点:
1,具有可伸缩性,可以随时添加和删除元素
2,可以很方便的取元素
3,列表元素可以是不同类型
python列表的操作:
添加append,插入insert,删除remove/pop,排序sort,倒序reverse,合并extend等
#!/usr/bin/env python#--coding: utf-8--
#定义小马列表
li=[\'twilight\',\'pinkiepie\',\'rainbow dash\']
#appand() 对象:列表 参数一:元素 返回值:无
li.append(\'apple jack\')
print("after append:%s"%li)
#插入insert() 对象:列表 参数一:要插入的下标 参数二:要插入的元素
li.insert(1,\'rarity\')
print("after insert:%s"%li)
#remove() 对象:列表 参数一:元素 返回值:无
li.remove(\'twilight\')
print("after remove:%s"%li)
#pop() 对象:列表 参数一:元素的下标 返回值:无
li.pop(1)
print("after pop:%s"%li)
#排序sort() 对象:列表 参数三:倒序 返回值:无
li.sort()
print("after sort:%s"%li)
#合并两个列表extend() 对象:列表 参数一:另一个列表 返回值:无
li.extend([\'twilight\',\'rainbow dash\'])
print("after extend:%s"%li)
#倒序reverse()--快速降序排序:li.sort(reverse=True)
li.reverse()
print("after reverse:%s"%li)
#计算元素的个数count()
print("rainbow dash个数:%s"%li.count(\'rainbow dash\'))
print("li 元素个数:%s"%len(li))
#查看元素的下标index() 对象:列表 参数一:要查找的元素 参数二:开始 参数三:结束 返回值:下标
print("第二个rainbow dash在哪里?%s"%li.index(\'rainbow dash\',2))
#遍历列表,sys.stdout.write为了不换行输出
import sys
for i in li: #li.__iter__()是list的迭代器,放在这里效果一样
sys.stdout.write(i+",")
print()
#清空
li.clear()
print("after clear:%s" %(li))
运行结果:
after append:[\'twilight\', \'pinkiepie\', \'rainbow dash\', \'apple jack\']
after insert:[\'twilight\', \'rarity\', \'pinkiepie\', \'rainbow dash\', \'apple jack\']
after remove:[\'rarity\', \'pinkiepie\', \'rainbow dash\', \'apple jack\']
after pop:[\'rarity\', \'rainbow dash\', \'apple jack\']
after sort:[\'apple jack\', \'rainbow dash\', \'rarity\']
after extend:[\'apple jack\', \'rainbow dash\', \'rarity\', \'twilight\', \'rainbow dash\']
after reverse:[\'rainbow dash\', \'twilight\', \'rarity\', \'rainbow dash\', \'apple jack\']
rainbow dash个数:2
li 元素个数:5
第二个rainbow dash在哪里?3
rainbow dash,twilight,rarity,rainbow dash,apple jack,
after clear:[]
元祖(tuple)----相当于常量数组
1,元素个数不会变
2,元祖的元素不会变
3,元祖的元素的元素会变
tup=(\'twilight\',\'pinkiepie\',\'rainbow dash\')
方法---参考列表:
count(),index()
字典(dict)----STL中的映射(map)
特点:
1,键值对,数据结构:散列表(hash),查找快
2,可伸缩
3,键只能是基本数据类型,值可以是任意类型,键的类型可以不同
字典的操作:单独取出键值,用键取值,用值取键,添加,删除,遍历
dic1={\'ts\':\'twilight\',\'pp\':\'pinkiepie\'}print(dic1)
#取值get() 对象:dict 参数一:键 参数二:没有值时代替值 返回值:值
print("ts the fullname:%s"%dic1.get(\'ts\'))
print("rd the fullname:%s"%dic1.get(\'rd\',\'rainbow dash\'))
#添加键值或输出值setdefault() 对象:dict 参数一:键 参数二:没有值时代替值
# 返回值:键的值
print(dic1.setdefault(\'pp\'))
print("pp the fullname:%s"%dic1[\'pp\'])
print(dic1.setdefault(\'rd\',"rainbow dash"))
print("rd the fullname:%s"%dic1[\'rd\'])
#遍历字典
import sys
my_keys=[]
my_values=[]
for k in dic1:
my_keys.append(k)
print(my_keys)
for k in dic1:
my_values.append(dic1[k])
print(my_values)
#键值格式化显示
for k,v in dic1.items():
print("%s--->%s"%(k,v))
#直接变成列表
print(list(dic1.keys()))
print(list(dic1.values()))
print(list(dic1.items()))
#dic1.pop(\'rr\') #pop删除时,如果原来已经没有的会报错,可以设置默认值
dic1.pop(\'pp\')
print(dic1)
#合并两个字典update()
dic2={\'aj\':\'apple jack\',\'fs\':\'fluttershy\'}
dic1.update(dic2)
print(dic1)
dic1.update(rr=\'rarity\',pp=\'pinkiepie\') #可以使用函数可变值来更新字典
print(dic1)
#fromkeys用于创建一个新字典,以序列seq中元素做字典的键,value为字典所有键对应的初始值。
seq = (\'name\', \'age\', \'sex\')
dict = dict.fromkeys(seq)
print("New Dictionary : %s" % str(dict))
dict = dict.fromkeys(seq, 10)
print("New Dictionary : %s" % str(dict))
运行结果:
{\'pp\': \'pinkiepie\', \'ts\': \'twilight\'}
ts the fullname:twilight
rd the fullname:rainbow dash
pinkiepie
pp the fullname:pinkiepie
rainbow dash
rd the fullname:rainbow dash
[\'pp\', \'rd\', \'ts\']
[\'pinkiepie\', \'rainbow dash\', \'twilight\']
pp--->pinkiepie
rd--->rainbow dash
ts--->twilight
[\'pp\', \'rd\', \'ts\']
[\'pinkiepie\', \'rainbow dash\', \'twilight\']
[(\'pp\', \'pinkiepie\'), (\'rd\', \'rainbow dash\'), (\'ts\', \'twilight\')]
{\'rd\': \'rainbow dash\', \'ts\': \'twilight\'}
{\'aj\': \'apple jack\', \'rd\': \'rainbow dash\', \'ts\': \'twilight\', \'fs\': \'fluttershy\'}
{\'pp\': \'pinkiepie\', \'rr\': \'rarity\', \'rd\': \'rainbow dash\', \'ts\': \'twilight\', \'fs\': \'fluttershy\', \'aj\': \'apple jack\'}
New Dictionary : {\'name\': None, \'sex\': None, \'age\': None}
New Dictionary : {\'name\': 10, \'sex\': 10, \'age\': 10}
集合(set)
集合的特点:
1,一个容器,集合的元素不重复
2,是无序的hash表
3,集合的操作:并集,交集,差集
4,集合判断:是否是子集,是否有交集
集合的操作:
#!/user/bin/env python#-- coding: utf-8 --
set1={"pp","rr","tw"}
set2={"rd","pp","tw"}
print(set1,set2)
#专门用来输出
def output(*arg):
fm1="{0}是{1}和{2}的{3}"
fm2="{0}{1}{2}的{3}"
if arg[1]==True:
print(fm2.format(arg[0],"是",arg[2],arg[3]))
elif arg[1]==False:
print(fm2.format(arg[0],"不是",arg[2],arg[3]))
else:
print(fm1.format(arg[0],arg[1],arg[2],arg[3]))
#并集
set3=set1.union(set2) #set3=set1|set2 set1|=set2
output(set3,set1,set2,"并集")
#交集
set3=set1.intersection(set2) #set3=set1&set2 intersection_update更新对象,没有返回值
output(set3,set1,set2,"交集")
#差集一
set3=set1.difference(set2) #set1=set1-set2 difference_update
output(set3,set1,set2,"差集")
set3=set2.difference(set1) #set1=set2-set1
output(set3,set2,set1,"差集")
#差集二
set3=set1.symmetric_difference(set2) #set1=set1-set2|set2-set1 symmetric_difference_update
output(set3,set1,set2,"差集二")
#判断两个集合的关系
#是否是子集
set3={"pp","rr"}
output(set3,set3.issubset(set1),set1,"子集")
output(set1,set1.issubset(set3),set3,"子集")
#判断是否为父集
output(set3,set3.issuperset(set1),set1,"父集")
output(set1,set1.issuperset(set3),set3,"父集")
#判断是否没有交集
output(set2,set2.isdisjoint(set1),set1,"交集")
#执行之后
集合一:{\'pp\', \'tw\', \'rr\'} 集合二:{\'rd\', \'pp\', \'tw\'}
{\'rd\', \'pp\', \'tw\', \'rr\'}是{\'pp\', \'tw\', \'rr\'}和{\'rd\', \'pp\', \'tw\'}的并集
{\'pp\', \'tw\'}是{\'pp\', \'tw\', \'rr\'}和{\'rd\', \'pp\', \'tw\'}的交集
{\'rr\'}是{\'pp\', \'tw\', \'rr\'}和{\'rd\', \'pp\', \'tw\'}的差集
{\'rd\'}是{\'rd\', \'pp\', \'tw\'}和{\'pp\', \'tw\', \'rr\'}的差集
{\'rd\', \'rr\'}是{\'pp\', \'tw\', \'rr\'}和{\'rd\', \'pp\', \'tw\'}的差集二
{\'pp\', \'rr\'}是{\'pp\', \'tw\', \'rr\'}的子集
{\'pp\', \'tw\', \'rr\'}不是{\'pp\', \'rr\'}的子集
{\'pp\', \'rr\'}不是{\'pp\', \'tw\', \'rr\'}的父集
{\'pp\', \'tw\', \'rr\'}是{\'pp\', \'rr\'}的父集
{\'rd\', \'pp\', \'tw\'}不是{\'pp\', \'tw\', \'rr\'}的交集
collections模块-----扩展容器
Counter,nametuple,defaultdict,OrderDict
Counter:
Dict subclass for counting hashable items. Sometimes called a bag
or multiset. Elements are stored as dictionary keys and their counts
are stored as dictionary values.
传入一个包,元素变成字典的key,元素的计数变成字典的值
可传入一个迭代去,或者一个字典
#Counter继承dict,具有dict的特性import collections
dic=collections.Counter()
c = collections.Counter() # 可传入空
print(c)
c = collections.Counter({\'a\': 4, \'b\': 2}) # 传入一个字典
print(c)
c = collections.Counter(a=4, b=2) #可传入有关键字的参数
print(c)
c = collections.Counter(\'gallahad\') # 迭代器
print(c)
#一些方法
#most_common提取计数最多的前n个元素 对像:Counter 参数一:n 返回值:元组的列表
print(c.most_common(3))
#有序字典
#通常一个字典是无序的,当popitem时,删除的元素通常会变
dic1={}
dic1.setdefault(\'k1\',\'v1\')
dic1.setdefault(\'k2\',\'v2\')
dic1.setdefault(\'k3\',\'v3\')
dic1.popitem()
print(dic1)
#OrderedDict会记录传入的数据,当popitem时保证删除的元素是最后传入的那个
#OrderedDict是dict的继承类,可以用dict的各种方法
dic2=collections.OrderedDict()
dic2.setdefault(\'k1\',\'v1\')
dic2.setdefault(\'k2\',\'v2\')
dic2.setdefault(\'k3\',\'v3\')
dic2.popitem()
print(dic2)
#默认字典
#默认如果没有定义字典的值,直接使用类型的方法会出错
li={}
li[\'key01\']=[10]
print(li)
#defaultdict会事先定义字典的值的类型
li=collections.defaultdict(list)
li[\'key01\'].append(10)
print(li)
得出:
Counter()
Counter({\'a\': 4, \'b\': 2})
Counter({\'a\': 4, \'b\': 2})
Counter({\'a\': 3, \'l\': 2, \'d\': 1, \'g\': 1, \'h\': 1})
[(\'a\', 3), (\'l\', 2), (\'d\', 1)]
{\'k2\': \'v2\', \'k3\': \'v3\'}
OrderedDict([(\'k1\', \'v1\'), (\'k2\', \'v2\')])
{\'key01\': [10]}
defaultdict(<class \'list\'>, {\'key01\': [10]})
View Code
以上是 python容器类型:列表,字典,集合等 的全部内容, 来源链接: utcz.com/z/387664.html