React同构与极致的性能优化

React同构与极致的性能优化
前言
随着React的兴起, 结合Node直出的性能优势和React的组件化,React同构已然成为趋势之一。享受技术福利的同时,直面技术挑战,在复杂场景下,挑战10倍以上极致的性能优化。
什么是同构?
一套代码既可以在服务端运行又可以在客户端运行,这就是同构应用。简而言之, 就是服务端直出和客户端渲染的组合, 能够充分结合两者的优势,并有效避免两者的不足。
为什么同构?
性能: 通过Node直出, 将传统的三次串行http请求简化成一次http请求,降低首屏渲染时间
SEO: 服务端渲染对搜索引擎的爬取有着天然的优势,虽然阿里电商体系对SEO需求并不强,但随着国际化的推进, 越来越多的国际业务加入阿里大家庭,很多的业务依赖Google等搜索引擎的流量导入,比如Lazada.
兼容性: 部分展示类页面能够有效规避客户端兼容性问题,比如白屏。
性能数据
性能是一个综合性的问题, 不能简单地断言同构应用一定比非同构应用性能好,只能说合适的场景加上合理的运用,同构应用确实能带来一定的性能提升, 先来看一个线上的案例。
通常来说,网络状况越差,同构的优势越明显,下图是在不同网络状况下首屏渲染时间的一组对比:
线上案例
近两年,无论是业界还是阿里内部都涌现了大量同构实践, 业界比较有影响力的包括Facebook, Quora, Medium, Twitter, Airbnb, Walmart、手Q以及QQ兴趣部落等
阿里内部也有大量的应用,仅列举部分beidou开发组做过技术支持的项目
阿里云 - 大数据地产
钉钉 - 企业主页
钉钉 - 钉钉日志和审批模板市场
菜鸟 - 物流大市场
云零售 - 店掌柜
Lazada - PDP
国际事业部 - AGLA
AILab - 行业解决方案
AILab - 智能硬件平台
AILab - AliGenie开放平台
AILab - AR官网
ICBU - ICBU店铺
业务平台 - 门店评价
国际UED - 数据运营
国际UED - 知之
国际UED - 探花
国际UED - Nuke官网及过程管理
国际UED - 会议记录,实时翻译
国际UED - LBS数据地图
国际UED - 数探
国际UED - 微策
国际UED - shuttle
国际UED - fie portal
...
业界生态
react-server: React服务端渲染框架
next.js: 轻量级的同构框架
beidou: 阿里自己的同构框架,基于eggjs, 定位是企业级同构框架
除了开源框架,底层方面React16重构了SSR, react-router提供了更加友好的SSR支持等等, 从某种程度上来说,同构也是一种趋势,至少是方向之一。
思考 与 实现
同构的出发点不是 “为了做同构,所以做了”, 而是回归业务,去解决业务场景中SEO、首屏性能、用户体验 等问题,驱动我们去寻找可用的解决方案。在这样的场景下,除了同构本身,我们还需要考虑的是:
高性能的 Node Server
可靠的 同构渲染服务
可控的 运维成本
可复用的 解决方案
...
简单归纳就是, 我们需要一个 企业级的同构渲染解决方案。
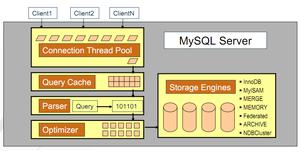
我们是怎么做的?
基于 eggjs 加入可拔插的同构能力
beidou-plugin-react 作为原有MVC架构中, view
层的替换, 使用 React 组件作为视图层模板, 可以直接渲染 React Component 并输出给客户端
beidou-plugin-webpack集成 Webpack 到框架中, 在开发阶段, 提供代码的编译和打包服务
beidou-plugin-isomorphic服务端的 React 运行时: babel-register
polyfill 注入: 环境变量, BOM等 非js文件解析: css, images, fonts...
服务端支持css modules
自动路由: 纯静态页面无需编写任何服务端代码,像写纯前端页面一样简单
...
这里不再赘述具体如何实现,有兴趣的读者可以阅读我们的开源同构框架beidou -- https://github.com/alibaba/beidou
热点问题
任何一种技术都有其适用场景和局限性, 同构也不例外,以下试举一二,以做抛砖引玉。
内存泄漏
性能瓶颈
...
内存泄漏不是同构应用所特有的,理论上所有服务端应用都可能内存泄漏,但同构应用是“高危群体”, 具体如何解决请参考本人的《Node应用内存泄漏分析方法论与实战》(https://github.com/alibaba/beidou/blob/master/packages/beidou-docs/articles/node-memory-leak.md),接下来重点剖析下性能优化。
极致的性能优化
前面也提到了,同构应用并不一定就比非同构应用性能好,影响性能的因素实在太多了,再来看一组数据:
上图是基于Node v8.9.1 和 [email protected], 开4个进程采集到的数据, X轴是最终生成页面节点数量,Y轴红色的线表示RT(包括渲染时间和网络时间), 绿色的柱子表示QPS. 可以看出来:
随着页面节点的增多渲染时间可能变得很长,QPS下降非常迅速。在页面节点超过3000左右的时候,QPS接近个位数了,而且实际页面中可能包含较复杂的逻辑以及不友好的写法,情况可能会更糟。
顺带提一下, 笔者采样了淘宝首页 和淘宝某详情页以及Lazada某详情页,页面节点数分别是2620、2467和3701.
大部分情况下,页面节点数低于1000, 比如菜鸟物流市场首页看起来内容不少,其实节点数是775。
那针对3000节点以上的页面,我们该怎么做呢?笔者总结了以下策略并重点阐述其中一两点:
采用编译后的React版本: 根据Sasha Aickin的博客,React15在Node4、Node6、Node8下,采用编译后的版本性能相比未编译版本分别提升了2.36倍、3倍、3.85倍
模块拆分: 模块拆分有利于并发渲染,目前ICBU店铺装修采用的就是这种方式
模块级别缓存: 页面中某些模块其实是很适合缓存的,比如Lazada详情页中节点数虽然高达3701, 但其实页头部分就占比55.5%,页尾占比3.5%,而页头页尾是常年不变的.
组件级缓存: 最小粒度的缓存单位了,性能提升依赖于缓存的范围和命中率,运用得当,可能带来非常大的性能提升。参考walmartlabs(https://medium.com/walmartlabs/reactjs-ssr-profiling-and-caching-5d8e9e49240c)
采用hsf代替http对外提供服务: hsf的网络消耗远低于http, 在店铺同构实践中,改用hsf, java端调用Node端的耗时缩短了一半。
部分模块客户端渲染(对SEO无用的部分): 直接降低SSR部分的复杂度
智能降级: 当流量暴增,接近或超过阈值时,会直接导致服务的RT快速上升。可以实时监测CPU和内存的使用率,超过一定的比例自动降级为客户端渲染,降低服务端压力,CPU和内存恢复常态时,自动切回服务端渲染。
采用Node8: 同样在店铺实践中,采用Node8相比Node6, 渲染时间从28ms降低到了18ms, 提升幅度为36%.
采用最新版React16: facebook官方数据(https://reactjs.org/blog/2017/09/26/react-v16.0.html#better-server-side-rendering),在Node8下,React16相比编译后的react15仍有3.8倍提升,相比未编译的React15更是有数量级的提升。
组件级缓存
如果说性能优化有"万能"的招式,那一定是缓存, 从Nigix缓存到模块级缓存到组件级缓存,其中最让人兴奋的就是组件级缓存,让我们一起来看看如何实现。
拦截React的渲染逻辑,业界主要有三种实现方式
Fork一份React, 暴力加入缓存逻辑, 代表库是react-dom-stream,
虽然这个库的人气很高,但笔者还是反对这种实现方式的。
通过require hook拦截instantiateReactComponent的载入并注入缓存逻辑,参考react-ssr-optimization(https://github.com/aickin/react-dom-stream)
扩展ReactCompositeComponent的mountComponent方法,参考electrode-react-ssr-cachin(https://github.com/electrode-io/electrode-react-ssr-caching/blob/master/lib/ssr-caching.js#L148-L161)
注入缓存逻辑, 代码如下
const ReactCompositeComponent
= require("react/lib/ReactCompositeComponent");
ReactCompositeComponent.Mixin._mountComponent = ReactCompositeComponent.Mixin.mountComponent;
ReactCompositeComponent.Mixin.mountComponent = function(rootID, transaction, context) {
const hashKey = generateHashKey(this._currentElement.props);
if (cacheStorage.hasEntry(hashKey)) {
// 命中缓存则直接返回缓存结果
return cacheStorage.getEntry(hashKey);
} else {
// 若未命中,则调用react的mountComponent渲染组件,并缓存结果
const html = this._mountComponent(rootID, transaction, context);
cacheStorage.addEntry(hashKey, html);
return html;
}
};
设置最大缓存和缓存更新策略
lruCacheSettings: {
max: 500, // The maximum size of the cache
maxAge: 1000 * 5 // The maximum age in milliseconds
}
上述缓存逻辑是基于属性的,能覆盖大部分的应用场景,但有一个要求,属性值必须可枚举且可选项很少. 请看下面的场景。
淘宝某页面上有大量的商品,而淘宝的商品又何止百万,就算某个被缓存,下次被命中的可能性依然微乎其微。那如何解决这个问题?聪明的读者可能已经看出来了,虽然每个商品最终渲染的结果千变万化,但结构始终是一致的,因此结构是可以缓存的。
要实现结构的缓存,需要在上述逻辑上额外新增三步。
生成中间结构:
以组件<Price>${price}</Price>为例,将变量price以占位符${price}代替set(price,
"${price}"), 再调用react原生的mountComponent方法则可以生成中间结构<div>${price}</div
缓存中间结构
生成最终组件
以上就是组件级缓存的实现方式, 特别要提醒的是缓存是把双刃剑,运用不当可能会引发内存泄漏以及数据的不一致。
React16 SSR
FB在9.26发布了React16正式版,之前万众期待的SSR性能提升(https://hackernoon.com/whats-new-with-server-side-rendering-in-react-16-9b0d78585d67)没有让大家失望,
引用React核心开发Sasha Aickin的对比图:
笔者拿之前的应用升级到React16, 对比下3909节点,RT从295ms降到了51ms, QPS从9提升到了44, 提升非常明显。
实战
接下来通过一个例子,展示如何一步步地提升性能。代码仓库(https://github.com/alibaba/beidou/tree/master/examples/performance)
-- https://github.com/alibaba/beidou/
10倍以上性能提升
首先构造一个非常复杂的页面, 页面节点数是3342, 对比之下,淘宝首页首屏的页面节点数是831,
异步充分加载之后(懒加载完成),整个页面节点数为3049. 注: 淘宝页面为动态页面,每次采样可能会有差异。
初始平均渲染时间为295.75ms(Node6.92, React15.6.2), 注: 图中有296.50ms,317.25ms,297.25ms,295.75ms四个平均值,是因为开启了四个进程,采样最后一个,下同。
启用babel性能加速插件,
平均渲染时间为219.00ms
采用Node8.9.1(或更新版本)平均渲染时间为207ms
采用production模式平均渲染时间为81.75ms
部分内容客户端渲染,平均渲染时间为44.63ms
部分内容组件级别cache,平均渲染时间为22.65ms
采用React16(或更新版本),平均渲染时间为5.17ms
结合React16和部分客户端渲染,平均渲染时间为2.68ms
至此,服务端渲染时间已经最初的295.75ms降低到了2.68ms,提升了超过100倍。
更多性能策略
其实除了上述应用的策略,还有其它的策略,比如:
采用Async, 有数据称性能提升30%, 笔者试了下,未见明显提升。应该是经过了babel的编译,最终没有发挥出Async的优势,这是因为beidou框架在服务端要支持import等ES6的写法以及支持React的JSX语法。其实也非常简单,直接缩小babel的编译范围,在beidou框架中是可以自己定义的。
降低React组件的嵌套层级。试验数据,同样的页面节点数,服务端渲染时间和组件的嵌套层级是线性正相关的。
热点缓存 ...
万变不离其宗
借用《功夫》中的一句经典台词天下武功,无坚不破,唯快不破,同样的, 随着时间的推移,上面这些策略策略迟早会被破,比如react16 ssr重构之后,之前的组件级别缓存逻辑不再有效。 另外,可能由于架构设计/技术选型根本就使不上劲,比如react16是今年9月26才正式发版,很多第三方组件还没来得及升级,如果应用中有些组件强依赖于react15或者更早的版本,可能根本就没法利用react16的性能优势。
那么有没有一种万能的办法,能够做到唯快不破呢?
答案是: 有的。 只有掌握了方法论,才能在不断变化中,找到适合自己应用的性能优化策略。
具体的方法论,请参考本人的另外一篇文章《唯快不破,让nodejs再快一点》(https://github.com/alibaba/beidou/blob/master/packages/beidou-docs/articles/node-performance-optimization.md)。
注: 本文为第12届D2前端技术论坛《打造高可靠与高性能的React同构解决方案》分享内容,已经过数据脱敏处理。
出处:https://github.com/alibaba/beidou/blob/master/packages/beidou-docs/articles/high-performance-isomorphic-app.md
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
-END-
以上是 React同构与极致的性能优化 的全部内容, 来源链接: utcz.com/z/383502.html