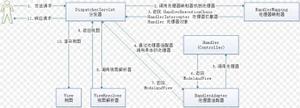
详解Flask前后端分离项目案例
简介
学习慕课课程,Flask前后端分离API后台接口的实现demo,前端可以接入小程序,暂时已经完成后台API基础架构,使用 postman 调试.git
重构部分:
- ken校验模块
- auths认证模块
- scope权限模块,增加全局扫描器(参考flask HTTPExceptions模块)
收获
- 我们可以接受定义时的复杂,但不能接受调用时的复杂
- 如果你觉得写代码厌倦,无聊,那你只是停留在功能的实现上,功能的实现很简单,你要追求的是更好的写法,抽象的艺术,不是机械的劳动而是要 创造 ,要有自己的思考
- Sqlalchemy 中对类的创建都是用元类的方式,所以调用的时候都不用实例化,当我们重写 __init__ 方法是需要调用 orm.reconstrcut 装饰器,才会执行实例化对象的构造函数
- 权限等级模块的设计( api访问权限 ),如超级管理员,管理员,普通用户,访客,这四者之间的关系,有包含的关系,所以可以考虑合并也可以考虑排除的方式来构建权限控制模块. 参考本项目中的 app.libs.scope
- 学的是解决问题的方法,首先要有深度,在去考虑广度,还要懂得迁移应用,形成自己的思维模型。
知识点复盘
初始化flask应用程序
app = Flask(__name__, static_folder='views/statics', static_url_path='/static', template_folder="templates")
创建Flask应用程序实例对象, 如果模块存在,会根据模块所在的目录去寻找静态文件和模块文件, 如果模块不存在,会默认使用app对象所在的项目目录
- __name__ 表示以此模块所在的目录作为工作目录,就是静态文等从这个目录下去找
- static_folder 指定静态文件存放相对路径 flask默认会用/进行分割然后取最后一个作为访问 url 类似 Django 中的 STATICFILES_DIRS
- static_url_path 指定访问静态文件的 url 地址前缀, 类似 Django 中的 STATIC_URL
- template_folder 指定模板文件的目录
@property
def static_url_path(self):
"""The URL prefix that the static route will be accessible from.
If it was not configured during init, it is derived from
:attr:`static_folder`.
"""
if self._static_url_path is not None:
return self._static_url_path
if self.static_folder is not None:
basename = os.path.basename(self.static_folder)
return ("/" + basename).rstrip("/")
@static_url_path.setter
def static_url_path(self, value):
if value is not None:
value = value.rstrip("/")
self._static_url_path = value
Flask 中 url 相关底层类
- BaseConverter 子类:保存提取 url 参数匹配规则
- Rule 类:记录一个 url 和一个视图函数的对应关系
- Map 类:记录所有 url 地址和试图函数对应的关系 Map(Rule, Rule, ....)
- MapAdapter 类:执行 url 匹配的过程,其中有一个 match 方法, Rule.match(path, method)
自定义路由管理器
from flask import Flask
app = Flask(__name__)
from werkzeug.routing import BaseConverter
class RegexUrl(BaseConverter):
# 指定匹配参数时的正则表达式
# 如: # regex = '\d{6}'
def __init__(self, url_map, regex):
"""
:param url_map: flask会自动传递该参数
:param regex: 自定义的匹配规则
"""
super(RegexUrl, self).__init__(url_map)
self.regex = regex
# 在对应的试图函数之前调用
# 从url中提取出参数之后,会先调用to_python
# 会把提取出的值作为参数传递给to_pthon在返回给对应的试图
def to_python(self, value):
"""可以在这里做一些参数的类型转换"""
return value
# 调用url_for时会被调用, 用来处理url反向解析时url参数处理
# 返回值用来拼接url
def to_url(self, value):
"""对接收到参数做一些过滤等"""
return value
# 将自定义路由转换器类添加到转换器字典中
app.url_map.converters['re'] = RegexUrl
# 案例
@app.route('/user/<re("[a-z]{3}"):id>')
def hello(id):
return f'hello {id}'
if __name__ == '__main__':
app.run(debug=True)
全局异常捕获
AOP编程思想,面向切面编程,把事件统一在一个地方处理,在一个统一的出口做处理
errorhandler 在flask 1.0版本之前只支持填写对应的错误码,比如 @app.errorhandler(404)
在flask1.0版本之后就支持全局的异常捕获了 @app.errorhandler(code_or_exception) ,有了这个之后,就可以在全局做一个异常捕获了,不用每个视图函数都做异常捕获。
@app.errorhandler(Exception)
def framework_error(e):
if isinstance(e, APIException):
return e
elif isinstance(e, HTTPException):
code = e.code
msg = e.description
error_code = 1007
return APIException(msg, code, error_code)
else:
if not current_app.config['DEBUG']:
return ServerError()
else:
raise e
异常类型
- 可预知的异常(已知异常)
- 完全没有意识的异常(未知异常)
- abort函数
- abort(状态码) 是一个默认的抛出异常的方法
- 调用abort函数可以抛出一个指定状态码对应的异常信息
- abort函数会立即终止当前视图函数的运行**
模型对象的序列化
场景:我们有时候可能需要返回模型对象中的某些字段,或者全部字段,平时的做法就是将对象中的各个字段转为字典在返回 jsonnify(data) , 但是这样的写法可能在每个需要返回数据的试图函数中都写一个对应的字典。。对象转字典在返回。 json 默认是不能序列化对象的,一般我们的做法是 json.dumps(obj, default=lambda o: o.__dict__) 但是 __dict__ 中只保存实例属性,我们的模型类基本定义的类属性。解决这个问题就要看 jsonify 中是如何做序列化的,然后怎么重写。
重写 JSONEncoder
from datetime import date
from flask import Flask as _Flask
from flask.json import JSONEncoder as _JSONEncoder
class JSONEncoder(_JSONEncoder):
"""
重写json序列化,使得模型类的可序列化
"""
def default(self, o):
if hasattr(o, 'keys') and hasattr(o, '__getitem__'):
return dict(o)
if isinstance(o, date):
return o.strftime('%Y-%m-%d')
super(JSONEncoder, self).default(o)
# 需要将重写的类绑定到应用程序中
class Flask(_Flask):
json_encoder = JSONEncoder
模型类的定义
class User(Base):
id = Column(Integer, primary_key=True)
email = Column(String(24), unique=True, nullable=False)
nickname = Column(String(24), unique=True)
auth = Column(SmallInteger, default=1)
_password = Column('password', String(100))
def keys(self):
return ['id', 'email', 'nickname', 'auth']
def __getitem__(self, item):
return getattr(self, item)
注意: 修改了 json_encode 方法后,只要调用到 flask.json 模块的都会走这个方法
为什么要写 keys 和 __getitem__ 方法
当我们使用 dict(object) 操作一个对象的时候, dict 首先会到实例中找 keys 的方法,将其返回列表的值作为 key , 然后会根据 object[key] 获取对应的值,所以实例要实现 __getitem__ 方法才可以使用中括号的方式调用属性
进阶写法- 控制返回的字段
场景:当我们有一个 Book 的模型类,我们的 api 接口可能需要返回 book 的详情页所以就要返回所有字典,但另外一个接口可能只需要返回某几个字段。
class Book(Base):
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
author = Column(String(30), default='未名')
binding = Column(String(20))
publisher = Column(String(50))
price = Column(String(20))
pages = Column(Integer)
pubdate = Column(String(20))
isbn = Column(String(15), nullable=False, unique=True)
summary = Column(String(1000))
image = Column(String(50))
# orm实例化对象, 字段需要写在构造函数中,这样每个实例对象都会有自己的一份,删除增加都不会互相影响
@orm.reconstructor
def __init__(self):
self.fields = ['id', 'title', 'author', 'binding',
'publisher', 'price', 'pages', 'pubdate',
'isbn', 'summary', 'image']
def keys(self):
return self.fields if hasattr(self, 'fields') else []
def hide(self, *keys):
for key in keys:
self.fields.remove(key)
return self
def append(self, *keys):
for key in keys:
self.fields.append(key)
return self
@api.route('/search')
def search():
books = Book.query.filter().all() # 根据某些条件搜索的
books = [book.hide('summary') for book in books]
return jsonify(books)
@api,route('/<isbn>/detail')
def detail(isbn):
book = Book.query.filter_by(isbn=isbn).first_or_404()
return jsonify(book)
请求钩子函数
- before_first_request:在处理第一个请求前运行。
- before_request:在每次请求前运行。
- after_request:如果没有未处理的异常抛出,在每次请求后运行。
- teardown_request:在每次请求后运行,即使有未处理的异常抛出。
全局扫描器
模仿flask exceptions 预加载各个异常类的方式,将用户组自动加载进内存中,这样获取的话就更方便
str2obj = {}
level2str = {}
def iteritems(d, *args, **kwargs):
return iter(d.items(*args, **kwargs))
def _find_scope_group():
for _name, obj in iteritems(globals()):
try:
is_scope_obj = issubclass(obj, BaseScope)
except TypeError:
is_scope_obj = False
if not is_scope_obj or obj.level < 1:
continue
old_obj = str2obj.get(_name, None)
if old_obj is not None and issubclass(obj, old_obj):
continue
str2obj[_name] = obj
level2str[obj.level] = _name
# 模仿flask exceptions 预加载各个异常类的方式,将用户组自动加载进内存
_find_scope_group()
del _find_scope_group
常见bug
form 正则校验注意事项
r'{6, 25}$'
带空格和不带空格是两码事, 正则里面{,} 连续不带空格
r'{6,25}$'
参考
Python Flask高级编程之RESTFul API前后端分离精讲
到此这篇关于详解Flask前后端分离项目案例的文章就介绍到这了,更多相关Flask前后端分离 内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 详解Flask前后端分离项目案例 的全部内容, 来源链接: utcz.com/z/350640.html