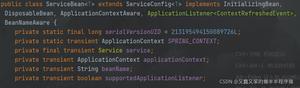
python docx的超链接网址和链接文本操作
我就废话不多说了,大家还是直接看代码吧~
from docx import Document
from docx import RT
import re
d=Document("./liu2.docx")
for p in d.paragraphs:
rels = d.part.rels
for rel in rels:
if rels[rel].reltype == RT.HYPERLINK:
print("\n 超链接文本为", rels[rel], " 超链接网址为: ", rels[rel]._target)
补充:Python输出“test.docx“文档正文中的所有红色的文字、输出文档中所有的超链接地址和文本
一、题目:
1、查阅资料了解.docx文档结构,然后编写程序,输出"test.docx"文档正文中的所有红色的文字。
2、查阅资料了解.docx文档结构,然后查阅资料,编写程序,输出"测试.docx"文档中所有的超链接地址和文本。
3、已知文件“超市营业额1.xlsx”中记录了某超市2019年3月1日至5日各员工在不同时段、不同柜台的销售额。部分数据如图,要求编写程序,读取该文件的数据,并统计每个员工的销售总额、每个时段的销售总额、每个柜台的销售总额。
超市营业额1.xlsx文件图
二、代码展示:
# -*- coding: utf-8 -*-
""""
@Author : Jackma
@Time : 2020/11/7 21:26
@File : 2020_11_7.py
@Software: PyCharm
@URL : www.jackmark.top
@Version :
"""
# 1、查阅资料了解.docx文档结构,然后编写程序,输出"test.docx"文档正文中的所有红色的文字。
# 2、查阅资料了解.docx文档结构,然后查阅资料,编写程序,输出"测试.docx"文档中所有的超链接地址和文本。
# 3、已知文件“超市营业额1.xlsx”中记录了某超市2019年3月1日至5日各员工在不同时段、不同柜台的销售额。
# 部分数据如图,要求编写程序,读取该文件的数据,并统计每个员工的销售总额、每个时段的销售总额、每个
# 柜台的销售总额。
# 4、查阅资料,编写程序操作Excel文件。已知当前文件夹中的文件“每个人的爱好.xlsx”的内容如图中A到H列所
# 示,要求追加一列,并如图中方框所示进行汇总。
from docx import Document
from docx.shared import RGBColor
from docx.opc.constants import RELATIONSHIP_TYPE as RT
from openpyxl import load_workbook
# 1
def find_bold_red():
'''
输出文档中的所有红色的、加粗的文字
:return:
'''
# 定义两个列表
boldText = [] # 存储加粗的文字
redText = [] # 存储红色字体的文字
name1 = input('输入你要查询的文件名(without .docx):')
# doc1 = Document('test.docx') # 打开文档
doc1 = Document(name1 + '.docx') # 打开文档
for p in doc1.paragraphs: # 遍历里面的每个段落
for r in p.runs: # 找每段中所有的run, run指连续的相同格式的字体
if r.bold: # 找到加粗字体
boldText.append(r.text) # 把run的文本放到boldText文本中
if r.font.color.rgb == RGBColor(255,0,0): # rgb(255,0,0)代表红色,找到红色字体
redText.append(r.text)
result = {'red text': redText,
'bold text': boldText,
'both': set(redText) & set(boldText) # 集合的交集
}
# 输出结果
for title in result.keys():
print(title.center(30, '=')) # 长度为30,center指居中,效果如下
# ===========red text============
for text in result[title]:
print(text)
find_bold_red()
# 2
# def find_Hyperlink():
# '''
# 只适用于WPS创建的文档
# 输出"test.docx"文档中所有的超链接地址和文本
# :return:
# '''
# doc2 = Document('test.docx')
# for p in doc2.paragraphs:
# for index, run in enumerate(p.runs):
# if run.style.name == 'Hyperlink':
# print(run.text, end =':')
# for child in p.runs[index-2].element.getchildren():
# text = child.text
# if text and text.stratswith('HYPERLINK'):
# print(text[12:-2])
#
# find_Hyperlink()
def find_Hyperlink():
'''
输出"test.docx"文档中所有的超链接地址和文本
:return:
'''
docx_file=input(" 输入你要查询的文件名(without .docx): ")
document = Document(docx_file + ".docx")
rels = document.part.rels
for rel in rels:
if rels[rel].reltype == RT.HYPERLINK:
# print("\n 超链接文本为", rels[rel], " 超链接网址为: ", rels[rel]._target)
print(" 超链接网址为: ", rels[rel]._target)
find_Hyperlink()
# 3
def money():
'''
统计每个员工的销售总额、每个时段的销售总额、每个柜台的销售总额。
:return:
'''
# 3个字典分别存储按员工、按时段、按柜台的销售总额
persons = dict()
periods = dict()
goods = dict()
ws = load_workbook('超市营业额1.xlsx').worksheets[0]
for index, row in enumerate(ws.rows):
# 跳过第一行的表头
if index == 0:
continue
# 获取每行的相关信息
_, name, _, time, num, good = map(lambda cell: cell.value, row)
# 根据每行的值更新三个字典
persons[name] = persons.get(name, 0) + num
periods[time] = periods.get(time, 0) + num
goods[good] = goods.get(good, 0) + num
print(persons)
print(periods)
print(goods)
money()
三、结果展示:
首先是测试文档test.docx内容
图1 test.docx文件图
程序1、
输出"test.docx"文档正文中的所有红色的文字。
程序2、
输出"test.docx"文档中所有的超链接地址和文本。
程序3、
统计每个员工的销售总额、每个时段的销售总额、每个柜台的销售总额。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。
以上是 python docx的超链接网址和链接文本操作 的全部内容, 来源链接: utcz.com/z/350547.html