Java HashMap实现原理分析(一)
从本文开始,介绍一下最常用的一个集合对象HashMap,HashMap存储的是键值对,本文采用的基于JDK11的源码实现。 一般大家都知道HashMap是通过put操作把一组键值对(key和value)存储到HashMap中,然后可以通过get(key)去获取key对应的value。而最重要的这两个过程是怎么实现的呢?下面我们就来对put和get这两个过程做一个分析。
HashMap基本工作原理
下面先看一段源码:
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
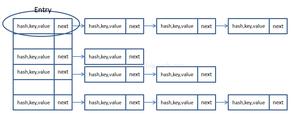
当用户调用put方法的时候把key和value放入到HashMap的时候,这个数组table就是实际存储key和value的地方。HashMap把用户传入的key和value封装成一个Node<K,V>对象,把该Node<K,V>对象放入到table对应的位置。Map执行get操作的时候,并没有传入具体的数组的索引位置信息,只是传入了key,因此这个地方就会涉及到一个key转索引的一个操作,然后根据索引获取table中对应位置的Node对象,把value值返回给用户。由于数组的访问时间复杂度是O(1),因此Map的get操作也可以认为是O(1)( 这个地方先暂时理解为O(1),具体原因见后面)。
简单来说,在执行put方法的时候,Map会根据传入的key获取它hashcode值,然后根据hashcode与table大小进行求模运算,得到的值就是它在table数组索引位置。实际这个过程又有点复杂,具体下面开始分析。
HashMap 数组寻址与hash值计算
用户通过key访问map获取value的时候,原理是用key的hash值来与数组的大小取模获取数组的索引。但实际在HashMap实现中,对取模运算进行了一下优化,采用了(n-1) & hash(key)的方法获取数组索引,这里的n是table的大小,hash(key)表示key的哈希值,这种方法可以得到与取模运算一样的效果,但是速度要比取模运算快。
下面看一下,hash(key)的实现逻辑
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
从上面的源码看:
- 调用key的hashCode()方法获取hashCode值h
- 把h进行无符号右移16位
- 把h与h右移后的值进行异或操作最后得到key的hash值。
这里大家比较好奇,为什么会进行这种复杂操作,他的用意是什么?下面来给大家说一下这个过程。
假设 table的大小是16,key1和Key2调用hashCode方法获取的值的二进制形式分别是:
1111 1111 1111 1101 0000 0000 0000 0001 # key1
1111 1111 1111 1111 0000 0000 0000 0001 # key2
首先我们直接使用key1和key2的hashCode获取的值去计算在的table的索引值。
具体过程是:
# key1在table中索引的计算过程与结果
1111 1111 1111 1101 0000 0000 0000 0001
0000 0000 0000 0000 0000 0000 0000 1111 & #n-1的二进制
---------------------------------------
0000 0000 0000 0000 0000 0000 0000 0001 # 得到的table索引是1
# key2在table中索引的计算过程与结果
1111 1111 1111 1111 0000 0000 0000 0001
0000 0000 0000 0000 0000 0000 0000 1111 & #n-1的二进制
---------------------------------------
0000 0000 0000 0000 0000 0000 0000 0001 #得到的table索引是1
根据上面计算结果可知,虽然key1和key2值不同,但是最后得到的table的索引都是1,这样就会出现了冲突。主要原因是在与n-1进行&操作的时候,通常n的值比较小,因此高16位都是0,这样0和任何数&结果都是0。通常key的hashCode取值很不固定。从最高位到最低位都会出现1的可能。比如key1和key2,他们的区别恰恰是出现在自己的hashCode的高16位,因此key1和key2与n-1进行&操作的结果是一样的。如果key1和key2经过hash()方法处理后呢,来看看结果:
# key1在table中索引的计算过程与结果
1111 1111 1111 1101 0000 0000 0000 0001 #key1本身
^ 0000 0000 0000 0000 1111 1111 1111 1101 #key1右移16的值
-----------------------------------------------
1111 1111 1111 1111 1111 1111 1111 1100 # hash(key1)计算后的值
& 0000 0000 0000 0000 0000 0000 0000 1111 #n-1的二进制
-----------------------------------------------
0000 0000 0000 0000 0000 0000 0000 1100 #得到的table索引是12
# key2在table中索引的计算过程与结果
1111 1111 1111 1111 0000 0000 0000 0001 #key2本身
^ 0000 0000 0000 0000 1111 1111 1111 1111 #key2右移16的值
-----------------------------------------------
1111 1111 1111 1111 1111 1111 1111 1110 #hash(key1)计算后的值
& 0000 0000 0000 0000 0000 0000 0000 1111 #n-1的二进制
-----------------------------------------------
0000 0000 0000 0000 0000 0000 0000 1110 #得到的table索引是14
这样key1和key2不会出现位置冲突。当key和自己的高16位进行异或操作的后的值的低16位中同时保留了原始key低16位和高16位的特征。因此key1和key2再和n-1进行&运算时,减少了出现相同值的可能性。明白了这些内容内容,下一篇文章开始结束HashMap的put和get方法的实现原理。
以上是 Java HashMap实现原理分析(一) 的全部内容, 来源链接: utcz.com/z/332115.html