MySQL存储过程和函数的操作(十二)
数据库对象表时存储和操作数据的逻辑结构,而数据库对象存储过程和函数,则是用来实现将一组关于表操作的sql语句当作一个整体来执行。在数据库系统中,当调用存储过程和函数时,则会执行这些对象中所设置的sql语句组,从而实现相应功能。
1. 为什么使用存储过程和函数的操作
有时针对表的一个完整操作往往不是单条sql语句就可以实现的,而是需要一组sql语句来实现。在具体应用当中,一个完整的操作会包含多条sql语句,在执行过程中需要根据前面sql语句的执行结果有选择地执行后面sql语句。
存储过程和函数可以简单理解为一条或多条sql语句的集合。存储过程和函数就是事先经过编译并存储在数据库中的一段sql语句集合。
存储过程和函数有什么区别呢?这两者的主要区别在于函数必须有返回值,而存储过程则没有。存储过程的参数类型远远多于函数的参数类型。
关于存储过程和函数的优点如下:
1. 存储过程和函数允许标准组件式编程,提高了sql语句的重用性、共享性和可移植性。
2. 存储过程和函数能够实现较快的执行速度,能够减少网络流量。
3. 存储过程和函数可以作为一种安全机制来利用。
关于存储过程和函数的缺点如下:
1. 存储过程和函数的编写比单句sql语句复杂,需要用户有更高的技能和更丰富的经验。
2. 在编写存储过程和函数时,需要创建这些数据库对象的权限。=
2. 创建存储过程和函数
2.1 创建存储过程语法形式:
语法形式如下:
create procedure procedure_name([procedure_parameter[,...]])
[characteristic...] routine_body
//说明:procedure_name参数表示所要创建的存储过程的名字,procedure_parameter参数表示存储过程的参数,
characteristic参数表示存储过程的特性,routine_body参数表示存储过程的sql语句代码,可以用begin...end来标志sql语句的开始和结束。
//注意:在具体创建存储过程时,存储过程名不能和已经存在的存储过程名重复,推荐存储过程名为procedure_xxx或者proce_xxx;
//procedure_parameter 中每个参数的语法形式为:
[IN|OUT|INOUT] parameter_name type
//该语句中每个参数由三部分组成,分别为输入/输出类型、参数名和参数类型。
characteristic参数的取值为:
language sql
|[not] deterministic
|{constains sql | no sql | reads sql data|modifies sql data}
|sql security {definer | invoker}
|comment 'string'
1. language sql,表示存储过程的routine_body部分由sql语言的语句组成。为mysql软件所有默认的语句。
2. [not] deterministic,表示存储过程的执行结果是否确定。如果值是deterministic表示执行结果是确定的。即每次执行存储过程时,如果输入相同的参数将得到相同的输出;如果值为not deterministic,表示执行结果不确定,即相同的输入可能得到不同的输出。默认值为deterministic。
3. {contains sql|no sql|reads sql data|modifies sql data},表示sql语句的限制,如果值为contains sql表示可以包含sql语句,但不包含读或写数据的语句;如果值为no sql表示不包含sql语句;如果值为reads sql data表示包含读数据的语句;如果值为modifies sql data表示包含读数据的语句。默认值为contains sql。
4. sql security{definer|invoker},设置谁有权限来执行。如果值为definer,表示只有定义者才能执行,如果值为invoker表示调用者可以执行。默认值为definer。
5. comment ‘string', 表示注释语句。
2.2 创建函数语法形式:
语法形式如下:
create function function_name([function_parameter[,...]])
[characteristic...] routine_body
上述语句中,function_name参数表示所要创建的函数的名字;function_parameter参数表示函数的参数,characteristic参数表示函数的特性,该参数的取值与存储过程中的取值相同。routine_body参数表示函数的sql语句代码,可以用begin…end来表示sql语句的开始和结束。
function_parameter中每个参数的语法形式如下:
parameter_name type
在上述语句中每个参数由两部分组成,分别为参数名和参数类型。parameter_name表示参数名。type表示参数类型。
2.3 创建简单的存储过程和函数:
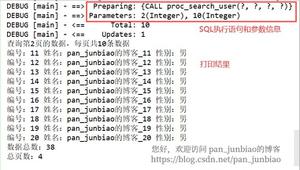
//查询雇员表中所有雇员工资的存储过程:
示例:
mysql> delimiter $$
mysql> delimiter $$ create procedure proce_employee_sal()
comment '查询所有雇员的工资'
begin
select sal from t_employee;
end $$
dilimiter ;
通常在创建存储过程时,通过命令delimiter && 将sql语句的结束符由“;”符号修改成两个美元符号。这主要是因为sql语句中默认语句结束符为分好(;),即存储过程中的sql语句也需要用分号来结束,将结束符号修改成两个美元符之后,就可以在执行过程中避免冲突。不过最后不要忘记将通过命令“delimiter ;”将结束符修改为sql语句中默认的结束符号。
创建函数示例:
delimiter $$
create function func_employee_sal (empno int(11))
returns double(10,2)
comment '查询某个雇员的工资'
begin
return (
select sal from t_employee where t_employee.empno=empno;
)
end$$
delimiter ;
创建了一个名为func_employee_sal的函数,该函数拥有一个类型为int(11),名为empno的参数,返回值为double(10,2)类型。select语句从t_employee表中查询empnoo字段值等于所传入参数empno值的记录,同时将该条记录的sal字段的值返回。
3. 关于存储过程和函数的表达式
3.1 操作变量:
变量是表达式语句中最基本的元素,可以用来临时存储数据。可以通过变量存储从表中查询到的数据。
3.1.1 声明变量:
语法形式如下:
declare var_name[,...] type [default value]
在上述语句中,var_name参数表示要声明的变量的名字;参数type表示所要声明变量的类型;default value用来实现设置变量的默认值,如果无该语句默认值为null。在具体声明变量时,可以同时定义多个变量。
3.1.2 赋值变量:
语法形式如下:
语法一:
set var_name=expr[,...]
语法二:
select filed_name[,...] into var_name[,...]
from table_name
where condition
var_name参数表示所要赋值变量名字,参数expr是关于变量的赋值表达式。在为变量赋值时,可以同时为多个变量赋值,各个变量的赋值语句之间用逗号隔开。
语法二中将查询到的结果赋值给变量,参数filed_name表示查询的字段名,参数var_name表示变量名。将查询结果赋值给变量,该查询语句的返回结果只能是单行。
示例:
declare employee_sal int default 1000;
declare employee_sal int default 1000;
set employee_sal = 3500;
select sal into employee_sal from t_employee where empno=7556;
3.2 操作条件:
3.2.1 定义条件:
语法形式如下:
declare condition_name condition for condition_value
condition_value:
sqlstate[value] sqlstate_value
|mysql_error_code
condition_name参数表示所要定义的条件名称;参数condition_value用来实现设置条件的类型;参数sqlstate_value和mysql_error_code用来设置条件的错误。
3.2.2 定义处理程序:
语法形式为:
declare handler_type handler for condition_value[,...] sp_statement
handler_type:
continue
|exit
|undo
condition_value:
sqlstate[value] sqlstate_value
|condition_name
|sqlwarning
|not found
|sqlexception
|mysql_error_code
这个语句指定每个可以处理一个或多个条件的处理程序。如果产生一个或多个条件,指定的语句被执行。对一个continue处理程序,当前子程序的执行处理程序语句之后继续。对于exit处理程序,当前begin…end复合语句的执行被终止。undo处理程序类型语句还不被支持。
1. sqlwarning是对所有以01开头的sqlstate代码的速记。
2. not found是对所有以02开头的sqlstate代码的速记。
3. sqlexception 是对所有没有被sqlwarning或not found捕获的sqlstate代码的速记。
3.3 使用游标:
mysql的查询语句可以返回多条记录结果,那么在表达式中如何遍历这些记录结果呢?mysql提供了游标来实现。通过指定由select语句返回的行集合(包括满足该语句的where子句所列条件的所有行),由该语句返回完整的行集合叫结果集。应用程序需要一种机制来一次处理结果集中的一行或连续的几行,而游标通过每次指定一条记录完成与应用程序的交互。
游标可以看做一种数据类型,可以用来遍历结果集,相当是指针或数组的下标。处理结果集的方法可以通过游标定位到结果集的某一行,从当前结果集的位置搜索一行或者一部分行或者结果集中的当前行进行数据修改。
3.3.1 声明游标:
语法形式如下:
declare cursor_name cursor for select_statement;
上述语句中,cursor_name参数表示有游标的名称,参数select_statement表示select语句。因为游标需要遍历结果集中的每一行,增加了服务器的负担,导致游标的效率并不高。如果游标操作的数据超过1万行,那么应该采用其他方式,另外如果使用了游标,还应尽量避免在游标循环中进行表连接操作。
3.3.2 打开游标:
语法形式为:
open cursor_name
//注意,打开一个游标时,游标并不指向第一条记录,而是指向第一条记录的前边。
3.3.3 使用游标:
语法形式如下:
fetch cursor_name into var_name [,var_name] ...
3.3.4 关闭游标:
语法形式如下:
close cursor_name
4. 修改存储过程和函数
对于已经创建好的存储过程和函数,当使用一段时间后,就会需要进行一些定义上的修改。可以通过alter procedure语句实现修改存储过程,通过alter function语句实现修改函数。
4.1 修改存储过程:
语法形式如下:
alter procedure procedure_name
[characteristic...]
procedure_name参数表示所要修改存储过程的名字,而characteristic参数指定修改后存储过程的特性,与定义存储过程的该参数相比,取值只能是如下值:
|(contains sql|no sql|reads sql data|modifys sql data)
|sql security {definer|invoker}
|comment ‘string'
)
4.2 修改函数:
语法形式如下:
alter function function_name
[characteristic...]
function_name参数表示所要修改函数的名字,而characteristic参数指定修改后的函数特性,与定义函数的该参数相比,取值只能是如下值:
|(contains sql|no sql|reads sql data|modifys sql data)
|sql security {definer|invoker}
|comment ‘string'
5. 删除存储过程和函数
5.1 通过drop语句删除存储过程:
语法形式如下:
drop prcedure proce_name;
5.2 通过drop function语句删除函数:
语法形式如下:
drop function func_name;
以上是 MySQL存储过程和函数的操作(十二) 的全部内容, 来源链接: utcz.com/z/329914.html