Zookeeper和etcd比较
本文内容纲要:Zookeeper和etcd比较
zookeeper:
zookeeper是基于paxos的简化版zab,我觉得确实很难理解?,以前看了好多遍《从paxos到zookeper》才感觉似懂非懂了,然而过了几个月发现又一脸蒙蔽了,在这里在整理一下(仅表示我自己的理解)
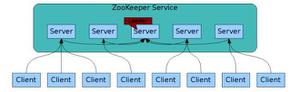
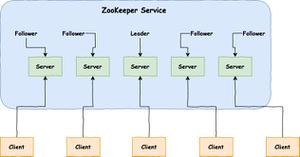
ZAB协议中存在着三种状态,每个节点都属于以下三种中的一种:
Looking :系统刚启动时或者Leader崩溃后正处于选举状态
Following :Follower节点所处的状态,Follower与Leader处于数据同步阶段;
Leading :Leader所处状态,当前集群中有一个Leader为主进程;
在开始时,所有的节点都是looking状态并且每个节点都希望自己能成为leader节点,所有每个节点都会向集群中发送一个提案内容是选取自己作为leader节点,提案编号是ZXID
(ZAB协议中使用ZXID作为事务编号,ZXID为64位数字,低32位为一个递增的计数器,每一个客户端的一个事务请求时Leader产生新的事务后该计数器都会加1,高32位为Leader周期epoch编号,当新选举出一个Leader节点时Leader会取出本地日志中最大事务Proposal的ZXID解析出对应的epoch把该值加1作为新的epoch,将低32位从0开始生成新的ZXID;ZAB使用epoch来区分不同的Leader周期),如果得到的提案的zxid比自己的大则说明发出这个题案的节点数据更新,则进行同意的投票,否则继续投自己,先得到多数的同意的节点当选为leader
现在leader就可以进行管理了,zookeeper也是两段提交的实现,客户端提交事务请求时Leader节点为每一个请求生成一个事务Proposal,将其发送给集群中所有的Follower节点,收到过半Follower的反馈后开始对事务进行提交,ZAB协议使用了原子广播协议
Leader节点为每一个Follower节点分配一个队列按事务ZXID顺序放入到队列中,且根据队列的规则FIFO来进行事务的发送。Follower节点收到事务Proposal后会将该事务以事务日志方式写入到本地磁盘中,成功后反馈Ack消息给Leader节点,Leader在接收到过半Follower节点的Ack反馈后就会进行事务的提交,以此同时向所有的Follower节点广播Commit消息,Follower节点收到Commit后开始对事务进行提交;?
如果leader宕机,则集群进入恢复阶段,根据上面的方式选举出ZXID最大的节点当选leader,并进入恢复阶段,所有的follewer都会将自己的ZXID发送个leader,由leader根据follower的ZXID与自己的相差的阶段数采取不同的措施实现整个集群的数据同步(若相差较小,则使用Leader发送从Follolwer.lastZXID到Leader.lastZXID议案的DIFF指令给Follower同步数据,若相差较大则直接发送leader的快照给follower)?
etcd
etcd作为最近很火的一个高可用性?键值对服务发现系统被Kubernetes等系统广泛使用
他相比与zookeeper来说更加简单,在面对较小集群时可能会效率更高些?,而且他的编写语言Go本身就是一种多线程编程语言,确实有很大吸引人的地方(虽然我不懂Go语言,但是在学习docker时也是一睹其风采了)
在Raft中,任何时候一个服务器可以扮演下面角色之一:
Leader: 处理所有客户端交互,日志复制等,一般一次只有一个Leader.
Follower: 类似选民,完全被动
Candidate候选人: 类似Proposer律师,可以被选为一个新的领导人。
1.leader选举阶段
和zookeeper一样 刚刚开始所有节点都会希望选取自己作为leader,但是不一样的是etcd却简单的多,他维持一个计时器,当这个计时器过时还没有leader发来心跳信息或者候选人发来的投票信息,就当自动成为选民向其他节点发送选取自己为leader的请求,若收到多数派的投票就当选 ,如果很不凑巧,有两个节点同时发起并且获得的投票数相同,那么过三百毫秒后两个节点再次进行争夺,这次相同投票数的概率就十分低,实在不行再来一次
2.消息同步阶段
假设Leader领导人已经选出,在leader接受到?消息请求,这时leader增加一个日志的要求,比如日志是"GO":
- Leader要求Followe遵从他的指令,都将这个新的日志内容追加到他们各自日志中:
3.大多数follower服务器将日志写入磁盘文件后,确认追加成功,发出Commited Ok:
- 在下一个心跳heartbeat中,Leader会通知所有Follwer更新commited 项目。
对于每个新的日志记录,重复上述过程。
3.网络分区问题
如果在这一过程中,发生了网络分区或者网络通信故障,使得Leader不能访问大多数Follwers了,那么Leader只能正常更新它能访问的那些Follower服务器,而大多数的服务器Follower因为没有了Leader,他们重新选举一个候选者作为Leader,然后这个Leader作为代表于外界打交道,如果外界要求其添加新的日志,这个新的Leader就按上述步骤通知大多数Followers,如果这时网络故障修复了,那么原先的Leader就变成Follower,在失联阶段这个老Leader的任何更新都不能算commit,都回滚,接受新的Leader的新的更新。?
说了这么多?------------------动画!!!!!!
看完瞬间开朗啊,不知道是哪位大神做的~?
http://thesecretlivesofdata.com/raft/
本文内容总结:Zookeeper和etcd比较
原文链接:https://www.cnblogs.com/zccgo/p/5714280.html
以上是 Zookeeper和etcd比较 的全部内容, 来源链接: utcz.com/z/297012.html