Node Stream 流(一)流的基本介绍及流下载文件
什么是流,为什么要使用流?之前对流的概念一直比较模糊。最近有时间好好的看了看关于流的知识,总算有了一个比较清晰的认识。
首先我们来看一下什么是流。
就我自己的观点来看,其实流就是在两个设备之间建立一个管道,然后通过管道将数据以流动的方式传输。如何来理解这个以流动的方式呢?
举个例子来说吧,当我们读取文件的时候,如果不使用流的方式读取的话,我们会将整个文件的内容先通过I/O设备写进内存,然后再由消费者去内存中读取。而使用流的方式是边将文件内容写入缓存边由消费者去读取,不用将整个文件先写进内存,从而节省了内存的空间。
不使用流的方式

当一个文件非常大的时候我们看到,不使用流的方式的话,占用的内存也是相当大的。这样就影响了响应的速度。对用户的体验也是有一定的影响的。
var http = require('http');var fs = require('fs');
var server = http.createServer(function (req, res) {
fs.readFile(__dirname + '/data.txt', function (err, data) {
res.writeHead(200,{
'Content-Type': 'application/octet-stream',
'Content-Disposition': 'attachment; filename=data.txt',
'Accept-Length': 1024,
});
res.end(data);
});
}).listen(8000)
上面是一段文件下载的功能。要下载的文件假设500M的话,其内存占用如下
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5601 root 15 0 1212m 516m 9460 R 0.7 51.7 0:10.09 node
5643 root 15 0 12764 1116 836 R 0.3 0.1 0:00.47 top
下载一个500M的文件,上述方法会占用500多兆的内存。所以说我们应该尽量避免上述方式出现在我们代码中。
下面我们看流的方式读取文件
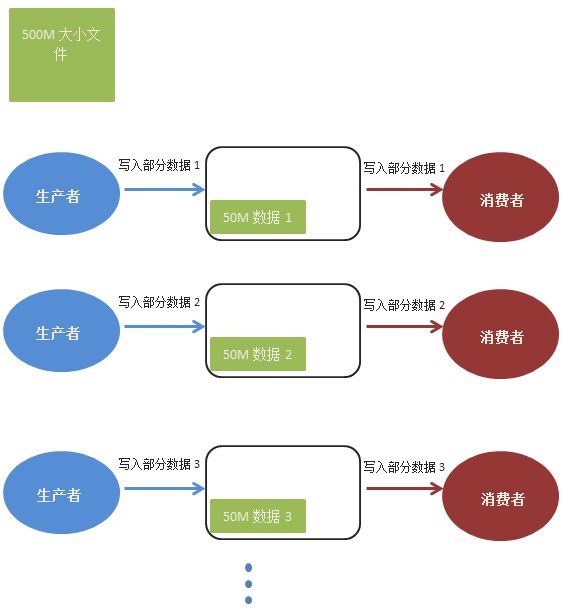
我们看使用流的方式的话,内存占用非常小,当然上面只是假定每次都是50M。经过测试内存使用情况流的方式平均是前者的十分之一。
其实上面流的过程我们可以这样理解

这就是我理解的流。
var http = require('http'); var fs = require('fs');var server = http.createServer(function (req, res) {
res.writeHead(200,{
'Content-Type': 'application/octet-stream',
'Content-Disposition': 'attachment; filename=data.txt',
'Accept-Length': 1024,
});
var stream = fs.createReadStream(__dirname + '/data1.txt' );
stream.pipe(res)
}).listen(8000);
上面代码是使用流的方式来下载文件,其内存占用情况如下。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5673 root 15 0 776m 49m 9992 S 7.3 5.0 0:04.47 node
5683 root 15 0 12764 1112 836 R 0.3 0.1 0:00.18 top
我们看到占用内存再50M左右。是不使用流的方式的十分之一。
至于为什么使用流,流的好处通过我们上面的例子我们也能看到,其最大的一个好处就是节省内存,提高程序的运行速度。通过上面两段文件下载的代码我们也能得到结论。除此之外node中的管道函数.pipe()(管道是流中一个非常重要的概念)还能根据消费者读取的速度通过阀门来控制写入的速度。
代码中在合适的地方加入流的使用,确能大大提高程序的性能。
本文转载自:迹忆客(https://www.jiyik.com)
以上是 Node Stream 流(一)流的基本介绍及流下载文件 的全部内容, 来源链接: utcz.com/z/290135.html