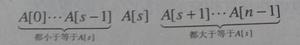针对字符串排序进行改进的一种快速排序算法
原文:http://www.jinbuguo.com/theory/str_qsort.html
代码
这是一个字符串数组的内存排序函数,是一种基于 Quick Sort 算法,针对字符串的改进版本。此函数有个特殊的假定:Strs[0] 必须是最小值,Strs[num-1] 必须是最大值。
__forceinline void StrSort(char** Strs, size_t num){//注意:Strs[0]必须是最小值,Strs[num-1]必须是最大值;num>0
size_t lo=0, mid_lo, mid_hi, hi=num-1; //当前子表的 低/中低/中高/高 指针
size_t loguy, higuy; //用于划分步骤的低/高滑动指针
size_t size=num; //当前子表大小
unsigned short preLen=0; //当前子表的公共前缀长度
unsigned char *src, *dst; //用于比较两个字符串(防止破坏原字符串)[必须强制为unsigned char*,由于'\0'结尾的原因]
short comp=0; //上述两字符串的比较结果:负 src<dst,零 src=dst,正 src>dst
size_t p, max; //小子表冒泡排序时的滑动索引和指向局部最大值的索引
char* tmp; //临时字符串
size_t lostk[32]={0}, histk[32]={0}; //保存子表低/高指针的FILO栈[因为小表优先处理,所以32已经足够大了]
char stkptr=0; //上述栈的深度
if(NULL==Strs||num<2) return; //无事可做
PseudoRecursion://更新lo,hi后,跳转到此处模拟递归
preLen=0; src=Strs[lo]; dst=Strs[hi]; while(*src==*dst && *dst) src++,dst++,preLen++; //计算当前子表的公共前缀长度
if((size=hi-lo+1)<11)
{//如果子表中乱序元素个数<=8,则时间复杂度为O(n^2)的冒泡算法效果最好[前人的经验,没有理由]
hi--; lo++;//因为首尾已经分别是最小/大值了
while(hi>lo)
{
max=lo;//假定索引lo指向局部最大值
for(p=lo+1; p<=hi; p++)
{//寻找指向数组中局部最大值的真实索引max
comp=0; src=Strs[p]+preLen; dst=Strs[max]+preLen; while(!(comp=*src-*dst) && *dst) src++,dst++; //比较两个字符串
if(comp>0) max=p;//如果p指向的值更大就更新max
}
tmp=Strs[max]; Strs[max]=Strs[hi]; Strs[hi]=tmp; //交换,使得hi处为局部最大值
hi--;
}
}
else
{//子表较大(>=11),继续分割
mid_lo=mid_hi=lo+size/2;//用于划分子表的中间索引[不能用(lo+hi)/2,可能会溢出]
loguy=lo+1; higuy=hi-1;//低/高端滑动指针[因为首尾已经分别是最小/大值了]
while(1)
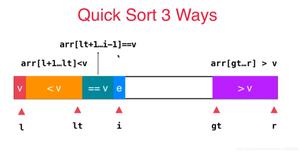
{//下面采取的策略是分割成3子表而不是传统的2子表,这对于改善有大量相同元素的表的效率有极大的提高!
while(loguy<mid_lo)
{//将loguy向高端滑动
comp=0; src=Strs[loguy]+preLen; dst=Strs[mid_lo]+preLen; while(!(comp=*src-*dst)&&*dst)src++,dst++; //比较两个字符串
if(comp<0) loguy++; //低端较小,符合顺序(继续下一个)
else if(comp>0) break; //低端较大,需要交换(暂停移动)
else { mid_lo--; tmp=Strs[loguy]; Strs[loguy]=Strs[mid_lo]; Strs[mid_lo]=tmp; }//相等,减小mid_lo并交换
}
while(mid_hi<higuy)
{//将higuy向低端滑动
comp=0; src=Strs[mid_hi]+preLen; dst=Strs[higuy]+preLen; while(!(comp=*src-*dst)&&*dst)src++,dst++; //比较两个字符串
if(comp<0) higuy--; //低端较小,符合顺序(继续下一个)
else if(comp>0) break; //低端较大,需要交换(暂停移动)
else { mid_hi++; tmp=Strs[higuy]; Strs[higuy]=Strs[mid_hi]; Strs[mid_hi]=tmp; }//相等,增大mid_hi并交换
}
//根据不同的情况采取不同的措施
if(loguy==mid_lo&&mid_hi==higuy) break;
tmp=Strs[loguy]; Strs[loguy]=Strs[higuy]; Strs[higuy]=tmp;
if(loguy<mid_lo&&mid_hi<higuy){loguy++; higuy--;}
else if(loguy==mid_lo&&mid_hi<higuy){mid_lo++; mid_hi++; tmp=Strs[mid_hi]; Strs[mid_hi]=Strs[higuy]; Strs[higuy]=tmp;}
else {mid_lo--; mid_hi--; tmp=Strs[loguy]; Strs[loguy]=Strs[mid_lo]; Strs[mid_lo]=tmp;}//if(loguy<mid_lo&&mid_hi==higuy)
}
//分割完毕;下面优先处理较小的子表,以避免栈溢出
if(mid_lo-lo<hi-mid_hi)
{//低端子表较小
if(hi-mid_hi>2){lostk[stkptr]=mid_hi; histk[stkptr]=hi; ++stkptr;} //将高端子表压栈//仅压3元素以上的子表
if(mid_lo-lo>2){hi=mid_lo; goto PseudoRecursion;}//仅处理3元素以上的子表
}
else
{//高端子表较小
if(mid_lo-lo>2){lostk[stkptr]=lo; histk[stkptr]=mid_lo; ++stkptr;} //将低端子表压栈//仅压3元素以上的子表
if(hi-mid_hi>2){lo=mid_hi; goto PseudoRecursion;}//仅处理3元素以上的子表
}
}
if(--stkptr>=0){ lo=lostk[stkptr]; hi=histk[stkptr]; goto PseudoRecursion; }
else return;
}
关于该算法的几点说明
为什么不直接用递归而是使用一个栈来模拟递归?
一方面可以减小函数递归调用带来的开销(其实维护一个栈需要的开销与递归差不多,只稍微少一点点而以)。
另一方面是最主要的原因,使用栈可以优先处理较小的子表,这样即使在最坏的情况下,栈的深度也不会超过30,而递归无法保证优先处理小的子表,从而无法保证栈的深度较小,而在最坏的情况下栈的深度将等于(num-10),这是不可接受的(内存也许会爆掉)!
为什么要假定:Strs[0] 必须是最小值,Strs[num-1] 必须是最大值?
通常仅仅在处理大量数据的时候才会非常关心效率的问题,而此时的数据通常保存在硬盘上,从硬盘调入内存的时候,瓶颈在硬盘,故而可以利用此速度差在读取的同时轻易找出最小/大字符串的值,并将其调换到字符串数组的首尾。进而给此排序函数提供额外的信息。
为什么要多花几个步骤来维护一个3子表,而不是传统的2子表?
因为传统 QuickSort 的2子表在数组中没有什么重复元素的情况下工作的非常好,但是一旦表中出现大量的重复元素,效率就会变得不可思议的低!而3子表在这种情况下仍然能工作的非常好,所以多花些步骤避免难堪的最坏结果是值得的。
为什么要在处理每个子表前计算公共前缀的长度?
算法中有大量的字符串比较,耗去了主要的时间,因为比较两有10个相同前缀的字符串需要多做10次无效劳动。所以如何减少无效劳动就显得很重要,因此在基于每个子表的最小/大字符串已知的情况下,可以计算出该子表的公共前缀的长度,从而线性的减少无效劳动,节约的时间很可观。
为什么将交换函数和比较函数集成在内部?
当然是为了最大限度减少函数调用的开销喽~虽然这样做的结果是代码看上去更加臃肿。但是为了效率,还是值得的!
为什么在子表较小(<11)的时候停止递归,转而使用冒泡排序?
前人的经验表明,在无序数组长度<=8的情况下,时间复杂度为O(n^2)的冒泡算法效果最好。因此它很适合用来处理最终的小子表。
以上是 针对字符串排序进行改进的一种快速排序算法 的全部内容, 来源链接: utcz.com/z/264669.html