Python B-Tree B 树 数据结构
B 树英文是 B-Tree,所以中文的B树或者B-树都是同一个东西。至于其中的字母B,则不代表任何东西,既不是 Binary,也不是 Balance.
B树的数据结构定义
B 树是一种多路搜索树,对于一个 m-阶 的B树:
- Every node has at most m children. 每个结点最多有m个子结点
- Every non-leaf node (except root) has at least ⌈m/2⌉ child nodes. 每个结点(除了根结点)最少有⌈m/2⌉个子结点
- The root has at least two children if it is not a leaf node. 根结点至少有两个子结点(除非根结点就是叶结点)
- A non-leaf node with k children contains k − 1 keys. 如果一个结点有 k 个子结点,说明它含有 k – 1 个 key.
- All leaves appear in the same level and carry no information. 所有的叶结点都处在同一层并且不携带任何信息(其实就是None)
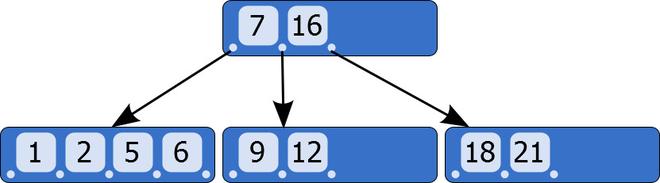
从定义中可以看出,B树和其它的平衡查找树的最大区别就是不再是一个二叉树,每个结点可以存放多个值(key),并且指向多个子结点。具体地说,一个结点中存放的数据结构为:(n,a0,K1,a1,K2,…,Kn,an),其中 n 代表这个结点含有的 key 的个数,Ki 代表存放的key(也就是二叉树中的value,比如2,23,57…),按升序排列,ai 则是指向子结点的指针,并且 ai 指向的子结点中存放的 key 值总是大于 ai 左边的 key 小于 ai 右边的 key(注意是开区间)。比如a1指向的子结点中存放的元素一定介于K1和K2之间。
B树比起平衡搜索树更加矮胖,这样做大大减小了树的高度,在B树中插入时,B树的高度也会增长得很缓慢,因为每一层都可以容纳很多元素。在最好的情况下,每个结点都被填满,即存放了 m – 1 个元素,最好情况下,B 树的高度为:
![]()
最坏情况下,每个结点只有 d = ⌈m/2⌉ 个子结点,B树的高度为:
![]()
由于B树在高度方面有很大优势,因此,对于文件系统以及数据库,B树是一个不错的选择。在这类应用中,磁盘IO的时间已经远远超过了读取到数据之后在内存中进行处理的时间,所以提升速度的关键是减小磁盘IO。如果每读一次结点,都要进行一次磁盘IO,那当然是希望尽量减少读结点的次数,即使在B树种读了一个结点之后会需要在内存中进行多次比较(一个结点里面有很多元素),那样也会快得多。
关于B树,推荐阅读:B-tree – Wikipedia
B 树的查找和插入
B树的查找类似于二叉搜索树的查找,在每个结点,找到待查找元素在哪个范围之间,再进入对应的子结点继续比较
插入元素的时候,先找到元素应该插入的位置,此时:
如果该结点存放的元素数量还没有超过最大限制,那么直接将该元素插入该结点
如果该结点已经满了,那就将其分裂(Split)为两个结点:
- 首先从该结点存放的所有元素以及待插入元素中选出一个中位数;
- 把小于中位数的元素放在分裂出来的左结点,大于中位数的元素放在右结点;
- 这个中位数则插入该结点的父结点。如果父结点已满,继续往上分裂;如果没有父结点,则创造一个新的父结点(会增加树的高度)
这个网站提供了B树的可视化操作:BTree Visualization
B 树的删除
参考:
- B 树的删除操作(视频)
- B 树和 B+ 树的插入、删除图文详解
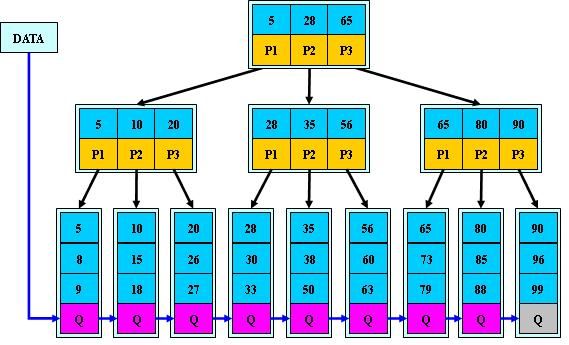
B+ 树
B+ 树是B 树的变种。广泛用于各种文件系统和数据库引擎中。B+ 树的定义与B树基本相同,不同的地方在于:
- 如果一个结点有 k 个 key,那它有k个子结点
- 子结点中的数据大于等于左边的 key 小于右边的 key
- 叶结点中以链表(有序)的形式存放了所有的数据,也包含中间结点的key(因此,B+ 树的搜索总是会到达叶结点,中间结点不保存数据,只是用来索引的)
以上是 Python B-Tree B 树 数据结构 的全部内容, 来源链接: utcz.com/z/264541.html