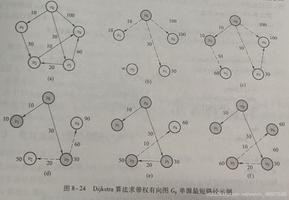
Dijkstra算法的复杂度
我从许多资料中获悉,如果使用幼稚的方法来获取min元素(线性搜索),Dijkstra的最短路径也将以O(V ^
2)复杂度运行。但是,如果使用优先级队列,则可以将其优化为O(VLogV),因为此数据结构将在O(1)时间返回min元素,但是在删除min元素之后需要O(LogV)时间来恢复堆属性。
我已经在以下链接中针对UVA问题的以下代码中实现了Dijkstra的算法:https
:
//uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&category=16&page=show_problem&problem
=1927:
#include<iostream>#include<vector>
#include <climits>
#include <cmath>
#include <set>
using namespace std;
#define rep(a,b,c) for(int c=a;c<b;c++)
typedef std::vector<int> VI;
typedef std::vector<VI> VVI;
struct cmp {
bool operator()(const pair<int,int> &a,const pair<int,int> &b) const {
return a.second < b.second;
}
};
void sp(VVI &graph,set<pair<int,int>,cmp> &minv,VI &ans,int S,int T) {
int e = -1;
minv.insert(pair<int,int>(S,0));
rep(0,graph.size() && !minv.empty() && minv.begin()->first != T,s) {
e = minv.begin()->first;
minv.erase(minv.begin());
int nb = 0;
rep(0,graph[e].size(),d) {
nb = d;
if(graph[e][d] != INT_MAX && ans[e] + graph[e][d] < ans[d]) {
set<pair<int,int>,cmp>::iterator si = minv.find(pair<int,int>(d,ans[d]));
if(si != minv.end())
minv.erase(*si);
ans[d] = ans[e] + graph[e][d];
minv.insert(pair<int,int>(d,ans[d]));
}
}
}
}
int main(void) {
int cc = 0,N = 0,M = 0,S = -1,T = -1,A=-1,B=-1,W=-1;
VVI graph;
VI ans;
set<pair<int,int>,cmp> minv;
cin >> cc;
rep(0,cc,i) {
cin >> N >> M >> S >> T;
graph.clear();
ans.clear();
graph.assign(N,VI());
ans.assign(graph.size(),INT_MAX);
minv.clear();
rep(0,N,j) {
graph[j].assign(N,INT_MAX);
}
ans[S] = 0;
graph[S][S] = 0;
rep(0,M,j) {
cin >> A >> B >> W;
graph[A][B] = min(W,graph[A][B]);
graph[B][A] = min(W,graph[B][A]);
}
sp(graph,minv,ans,S,T);
cout << "Case #" << i + 1 << ": ";
if(ans[T] != INT_MAX)
cout << ans[T] << endl;
else
cout << "unreachable" << endl;
}
}
根据我的分析,我的算法具有O(VLogV)复杂度。STL std ::
set被实现为二进制搜索树。此外,该集合也被排序。因此,从中获取的最小元素为O(1),插入和删除的每个元素均为O(LogV)。但是,我仍然可以从这个问题中获得一个TLE,根据给定的时间限制,该问题应该可以在O(VLogV)中解决。
这使我思考得更深。如果所有节点都互连在一起,以使每个顶点V具有V-1邻居,该怎么办?因为每个顶点必须每个回合都查看V-1,V-2,V-3
…节点,这会使Dijkstra的算法在O(V ^ 2)中运行吗?
再三考虑,我可能会误解最坏情况下的复杂性。有人可以在以下问题上给我建议:
- 鉴于上述反例,Dijkstra的算法O(VLogV)的表现如何?
- 如何优化我的代码,使其达到O(VLogV)复杂度(或更高)?
编辑:
我意识到我的程序毕竟不能在O(ElogV)中运行。瓶颈是由我在O(V ^ 2)中运行的输入处理引起的。dijkstra部分确实在(ElogV)中运行。
回答:
为了了解Dijkstra算法的时间复杂度,我们需要研究对用于实现Frontier集的数据结构(即minv算法中使用的数据结构)执行的操作:
- 插
- 更新资料
- 查找/删除最小值
有O(|V|)插入,O(|E|)更新,O(|V|)对算法的整个过程中的数据结构发生查找/删除最低金额的总额。
最初,Dijkstra使用未排序的数组实现了Frontier集。因此,它
O(1)用于“插入和更新”,但是O(|V|)对于“查找/删除”最小值,导致O(|E| + |V|^2),但由于|E| < |V|^2,所以具有O(|V|^2)。如果使用二进制min-heap来实现Frontier集,则
log(|v|)所有操作都必须具有,结果为O(|E|log|V| + |V|log|V|),但是由于合理假设|E| > |V|,您具有O(|E|log|V|)。然后是Fibonacci堆,您已将
O(1)“插入/更新/查找”的最小O(log|V|)时间摊销了,但将“删除”的最小时间摊销了,这为您提供O(|E| + |V|log|V|)了Dijkstra算法的当前最著名的时间范围。
最后,O(|V|log|V|)如果(|V|log|V| <
|E|),则不可能在最坏的情况下解决单源最短路径问题的算法,因为问题具有较低的下限时间,O(|E| +
|V|)即您需要检查每个顶点和边至少一次以解决问题。
以上是 Dijkstra算法的复杂度 的全部内容, 来源链接: utcz.com/qa/435756.html