可以使用scrapy从使用AJAX的网站中抓取动态内容吗?
我最近一直在学习Python,并全力以赴来构建网络抓取工具。一点都不花哨。其唯一目的是从博彩网站上获取数据并将其放入Excel。
大多数问题都是可以解决的,我周围有些混乱。但是,我在一个问题上遇到了巨大的障碍。如果站点加载一张马表并列出当前的投注价格,则此信息不在任何源文件中。提示是该数据有时是活动的,并且明显从某个远程服务器更新了这些数据。我PC上的HTML只是有一个漏洞,他们的服务器正在推送我需要的所有有趣数据。
现在我对动态Web内容的经验很低,所以这件事使我难以理解。
我认为Java或Javascript是关键,它经常弹出。
刮板只是赔率比较引擎。有些网站有API,但对于那些没有的API,我需要它。我正在使用python 2.7的scrapy库
如果这个问题过于开放,我深表歉意。简而言之,我的问题是:如何使用scrapy来抓取此动态数据,以便可以使用它?这样我就可以实时抓取该赔率数据了吗?
回答:
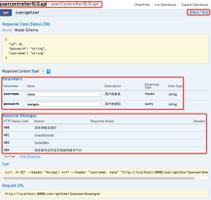
基于Webkit的浏览器(例如Google Chrome或Safari)具有内置的开发人员工具。在Chrome中,你可以将其打开Menu->Tools->Developer Tools。该Network选项卡使你可以查看有关每个请求和响应的所有信息:
在图片的底部,你可以看到我已将请求过滤到XHR-这些是由javascript代码发出的请求。
提示:每次加载页面时都会清除日志,在图片底部,黑点按钮将保留日志。
在分析了请求和响应之后,你可以模拟来自网络爬虫的这些请求并提取有价值的数据。在许多情况下,获取数据比解析HTML更容易,因为该数据不包含表示逻辑,并且其格式设置为可被javascript代码访问。
以上是 可以使用scrapy从使用AJAX的网站中抓取动态内容吗? 的全部内容, 来源链接: utcz.com/qa/408317.html