是否有高效读取1000万条Excel数据的Java解决方案?
Java怎么读取很大数据量的 Excel (1000万条数据),希望一行一行读取数据。
目前使用POI进行了文件读取,但是耗费时间很长,大约用了1分钟。大家有没有更快的解决方案
回答:
GcExcel可以轻松打开20万条数据的Excel文件。
这是性能对比结果: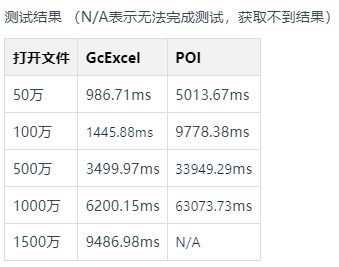
关于如何一行一行读取数据,GcExcel 可以通过区域读取一片区域,如果只想读取一行数据的话,可以通过Excel的坐标系来控制。
public void FetchRowData() { Workbook wb = new Workbook();
IWorksheet sheet = wb.getWorksheets().get(0);
//如果内存足够的话可以使用
//Object[][] data = (Object[][]) sheet.getUsedRange().getValue();
Object[][] data = (Object[][]) sheet.getRange("A1: Z500").getValue();
for (int i = 0; i < data.length; i++) {
Object[] row = data[i];
//下来可以根据 row 来进行后续操作
}
}
回答:
一般这种可以通过并发来解决读取缓慢的问
解决方案一:xlsx-streamer
采用分段缓存的方式加载数据到内存中,此种方式在创建Workbook对象时借助xlsx-streamer(StreamingReader) 来创建一个缓冲区域批量地读取文件 ,因此不会将整个文件实例化到对象当中
引入依赖:
<!-- excel工具 --><dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>${poi.version}</version>
</dependency>
<!-- 读取大量excel数据时使用 -->
<dependency>
<groupId>com.monitorjbl</groupId>
<artifactId>xlsx-streamer</artifactId>
<version>2.1.0</version>
</dependency>
示例代码:
/** * 大批量数据读取 十万级以上
* 思路:采用分段缓存加载数据,防止出现OOM的情况
*
* @param file
* @throws Exception
*/
public static void readLagerExcel(File file) throws Exception {
InputStream inputStream = new FileInputStream(file);
long start = System.currentTimeMillis();
try (Workbook workbook = StreamingReader.builder()
.rowCacheSize(10 * 10) //缓存到内存中的行数,默认是10
.bufferSize(1024 * 4) //读取资源时,缓存到内存的字节大小,默认是1024
.open(inputStream)) { //打开资源,可以是InputStream或者是File,注意:只能打开.xlsx格式的文件
Sheet sheet = workbook.getSheetAt(0);
log.info("==读取excel完毕,耗时:{}毫秒,", System.currentTimeMillis() - start);
//遍历所有的行
for (Row row : sheet) {
System.out.println("开始遍历第" + row.getRowNum() + "行数据:");
//遍历所有的列
for (Cell cell : row) {
System.out.print(cell.getStringCellValue() + " ");
}
System.out.println(" ");
}
//总数
System.out.println("读取结束行数:" + sheet.getLastRowNum());
}
}
加载数据效果
40万级别数据近花费5.4秒
解决方案二:EasyExcel
使用EasyExcel解决大文件Excel内存溢出的问题,基于POI进行封装优化,可以在不考虑性能、内存的等因素的情况下,快速完成Excel的读、写等功能。
官网: https://easyexcel.opensource.alibaba.com/github:https://github.com/alibaba/easyexcel
引入依赖
<!-- EasyExcel 大数据量excel读写 --><dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.1.0</version>
</dependency>
示例代码
仅做简单读取示例,详细文档api可参考:读Excel|EasyExcel
/** * EasyExcel方式读取excel
* <p>
* 读取并封装为对象
*
* @param file
*/
public static void readExcelByEasyExcel(File file) {
long start = System.currentTimeMillis();
List<ExcelData> excelDataList = EasyExcel.read(file).head(ExcelData.class).sheet(0).doReadSync();
excelDataList.stream().forEach(x -> System.out.println(x.toString()));
log.info("==读取excel完毕,耗时:{}毫秒,", System.currentTimeMillis() - start);
}
/**
* EasyExcel方式读取excel
* <p>
* 不指定head类
*
* @param file
*/
public static void readExcelByEasyExcel1(File file) {
long start = System.currentTimeMillis();
List<Map<Integer, String>> listMap = EasyExcel.read(file).sheet(0).doReadSync();
listMap.stream().forEach(x -> System.out.println(JSON.toJSONString(x)));
log.info("==读取excel完毕,耗时:{}毫秒,", System.currentTimeMillis() - start);
}
回答:
除楼上之外,补充一种hutool+poi的写法,本质还是流读取的方式,非常简单而且效率很高:
maven依赖:
<dependency> <groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.22</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>5.2.4</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.2.4</version>
</dependency>
poi是针对xls的,poi-ooxml是针对xlsx的
示例的写法,就是遍历每一行你要做什么:
private RowHandler createRowHandler() { return new RowHandler() {
@Override
public void handle(int sheetIndex, int rowIndex, List<Object> rowlist) {
Console.log("[{}] [{}] {}", sheetIndex, rowIndex, rowlist);
}
};
}
ExcelUtil.readBySax("aaa.xlsx", 0, createRowHandler());//这里的0可以是sheet的索引下标,也可以是sheet的名字
以上是 是否有高效读取1000万条Excel数据的Java解决方案? 的全部内容, 来源链接: utcz.com/p/945453.html