多线程并发查询百万数据的内存占用问题?
开启十个线程,每个线程都会去查询500W的数据。
@Test void testThread() throws InterruptedException {
int size = 10;
CountDownLatch countDownLatch = new CountDownLatch(size);
for (int i = 0; i < size; i++) {
CompletableFuture.runAsync(() -> {
testPage();
countDownLatch.countDown();
});
}
countDownLatch.await();
}
@Test
void testPage(){
//查询出表中总记录数
Long total = orderMapper.selectCount(null);
//每次分页读取的结果数
int fetchSize = 100000;
// 分页优化参数,上次查询的最大ID
int lastMaxId = 0;
for (int i = 0; i < (total / fetchSize) + 1; i++) {
LambdaQueryWrapper<Order> orderLambdaQueryWrapper = new LambdaQueryWrapper<>();
orderLambdaQueryWrapper.gt(Order::getOrderId, lastMaxId);
List<Order> records = orderMapper.selectPage(new Page<>(1, fetchSize), orderLambdaQueryWrapper).getRecords();
records.stream().forEach(System.out::println);
//获取本次最大的Id
lastMaxId = records.get(records.size() - 1).getOrderId();
}
}
单独一个线程,堆内存占用500M。
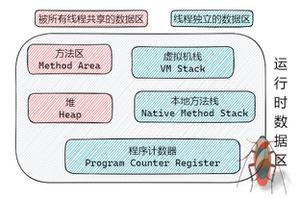
十个线程,堆内存占用最高也不过1400MB,为什么会这样呢?这些内存占用居然不会叠加的吗?
回答:
题目说十个线程各查 500 万,代码里是十个现成分批查,一批 10 万,500 万和 10 万的差距还是挺大的
多线程环境下这么观察内存使用其实没法观察,不如把单线程查询需要多少内存算准了,多线程就做个乘法的事
另外如果想知道内存使用多少,直接看字段大小就能大概估算出来
回答:
我觉得从“单线程查出数据时堆内存占用500M”不能得出“数据库全量数据对象的大小是500M左右”的结论,所以“10个线程是1400M不是叠加”这个结论也站不住脚。假设你的程序启动成本就是400M,一个线程在持续查询时内存占用是100M;那么10个就是1000M,加上启动成本就是1400M,也能解释你现在这个现象。
想要获得更精准一点的统计可以用jprofiler,可以根据类和调用来分析堆中的数据。不过,这样做的前提也是你的对象存在堆中,如果像代码这样查出来就丢,大概率是进不到老年代,在伊甸区就被回收了。
以上是 多线程并发查询百万数据的内存占用问题? 的全部内容, 来源链接: utcz.com/p/945410.html