mysql 一千万的数据量如何一秒内实现模糊搜索?
数据库是mysql5.7,数据量就认为一千万吧,想在这一千万的数据量中实现高效的模糊查询,有什么好的办法么?
走不了索引,单字段搜索,要精确搜索, 类似于 select * from table where title like %关键词% limit 100 这种。
这里面加了个限制,只返回前100条数据。不然更慢了。
感觉无解了,因为模糊搜索,走不了索引,所以每次全量查询就很慢。大概在10s左右。
==================
试过了很多种方法,效果都不太理想。
1、换es这个方案就大可不必了,划不着,没有精力再去维护一个es,还得数据同步,最重要是占内存。
2、mysql的分词索引这个方案也试过了,非常难用,而且对中文支持极其不友好,而且搜索不精准。
3、自己手动维护一个索引表这个方案也考虑过,感觉也不太可行,增加代码复杂度,而且分词导致搜索不准确。
4、分库分表这个方案也不用推荐了哈。
不要借助第三方的中间件哈,比如es,大数据数据库等。
目前只有一个 mysql + java程序。目前想到的有一个可行的方案是这样的,将数据全部加载到内存中,
在内存中实现模糊搜索,效果确实是很快,测试了3百万的数据量,都是在500ms内完成的。
但是问题点在于,太太太占内存了,差不多一百万的数据量占100M的内存空间。但是分给整个java的
堆内存才512M。也就是说,除了java程序自己本身消耗的内存, 也就最多 缓存300W条的数据量差不多,
加不了内存哈,就这么大的内存了,所以说,在不加内存的情况下 如何实现快速模糊搜索呢?
希望大佬指点一下,在这先谢谢了。
内存这个是真的加不了,毕竟现在服务器死贵。能给到java程序的最多也就512M的内存了,所以有没有
可以从jvm优化这块下手的,或者其他方案来实现的呢?
对了,不知道everything是如何实现搜索的,这个搜索起来真的是飞快,有大佬知道么?
回答:
数据库新手,一个很简单的想法,为嘛不能做个类似下表的索引呢?
索引表
| 当前词 | 下一词 | 原记录主键ID |
|---|---|---|
| mysql | 一 | 1 |
| 一 | 千 | 1 |
| 千 | 万 | 1 |
| 万 | 的 | 1 |
| …… | …… | …… |
| 模 | 糊 | 1 |
| 糊 | 搜 | 1 |
| 搜 | 索 | 1 |
| 索 | null | 1 |
搜索“模糊搜索”
SELECT 原记录主键ID FROM (SELECT 原记录主键ID FROM 索引表 WHERE 当前词 = '模' AND 下一词 = '糊')
JOIN (SELECT 原记录主键ID FROM 索引表 WHERE 当前词 = '糊' AND 下一词 = '搜') USING(原记录主键ID)
JOIN (SELECT 原记录主键ID FROM 索引表 WHERE 当前词 = '搜' AND 下一词 = '索') USING(原记录主键ID)
JOIN (SELECT 原记录主键ID FROM 索引表 WHERE 当前词 = '索' AND 下一词 IS NULL) USING(原记录主键ID)
回答:
检索大多数情况都是空间换时间,没有内存那基本无解
回答:
使用mysql自带的ngram全文索引插件吧.
免强能用.
https://dev.mysql.com/doc/ref...
官方文档
回答:
如果数据分冷热,可以加载5%或者10%的数据到内存。然后根据lfu、lru算法来更新热点数据。内存的没有的数据库里面查,不至于服务中断。不然无解。
回答:
我们有1.2亿条数据,大概占了300多G存储空间,要是全部加到内存里查立马破产
回答:
MySQL使用全文索引+ngram全文解析器进行全文检索
回答:
为啥100万的数据需要100M的内存空间呢,如果你只加载 title 和 id 到内存中,title 最坏情况都是汉字,采用 UTF-8 编码,长度最大为100 即 300 字节,id 是 long 类型 占 8 字节 300 + 8 + 32 (不确定但差不多 对象头或者其他) 总共 340 字节,如果乘以 1000 万 总共也就 300 多M 虽然没解决你的问题
回答:
https://www.cnblogs.com/woooodlin/articles/15532446.html
覆盖索引➕减少回表
网上看到的,我没试过
=======================
2023-06-16更新
刚在阮一峰的每周推荐里看到
https://www.jefftk.com/p/you-dont-always-need-indexes
感觉也挺有意思的
他直接用grep命令来搜文件实现全文搜索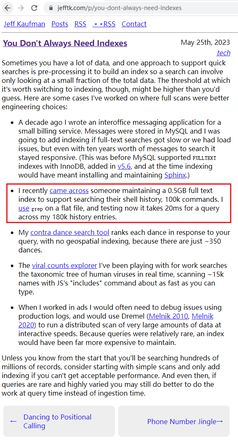
=============================
2023-06-28更新
其实这种问题最好是从产品设计上解决。
默认加上其他的带索引的条件,如时间范围,比如默认只查最近30天内的。
查不到数据的时候,再提示他要不要查更久远的
回答:
除了ES还有个Sphinx.也是使用倒排索引的方式。
直接链接数据库,字段都一样,但是缺点就是需要自己做数据同步(一行命令就ok)。
比ES轻了一点。
回答:
为了在一秒内实现 MySQL 中数据量为一千万的表的模糊搜索,你需要考虑以下几点:
- 确保你的搜索语句使用了索引。如果没有索引,MySQL 将会扫描整张表,这将会非常慢。
- 尽可能地减少搜索的范围。例如,如果你只想搜索某一列,可以使用 WHERE column LIKE '%keyword%' 的形式来减少搜索范围。
- 使用 Full-Text Search(全文搜索)。这是 MySQL 的一项特性,能够快速地搜索大型文本字段。
- 在表上建立足够多的索引,以便 MySQL 可以快速地找到你要搜索的数据。
- 考虑使用其他的搜索引擎,例如 Elasticsearch,它可以在大型数据集中进行高效的搜索。
回答:
分页查询 + 利用主键索引和 mysql 缓存,sql 类似于,select * from table where id>=上次查询最后匹配的数据主键(初始1)title like %关键词% limit 100(数量多调整测试),不知道有没有用
回答:
总感觉你这是强行把不适合的业务场景,强加到mysql上
拒绝第三方中间件,你是懒得上手吧。es的单机版运行,1核2G就可以。
就想mysql走天下,哎。es,solr的诞生不都是解决海量的数据吗
自己去用下分词的工具包比如hanlp,将数据预处理分词到词库中。还可以自定义业务域字典,提高精准匹配的结果,原理都是倒排的东西,就看自己去不去琢磨
回答:
可以使用mysql ngram 插件处理,但是出来的结果可能与你需要的 like %xxx% 的语义不符。
另外一个是,设置另外一个表:id,title,然后对这个表分表,查询的时候并发查询(第一个链接查询 1 - 100w,第二个链接查询 100w - 200w),返回id(100个)后,再去获取对应的数据。并且对mysql配置进行调优,如加大 buffer。最后对ES感兴趣的欢迎进我主页查看我的小册《Elasticsearch 从入门到实践》~
回答:
当数据量较大时,实现模糊搜索需要一些优化技巧。以下是一些可能有用的优化方法:
- 使用索引:索引可以加快查询速度,特别是在进行模糊搜索时。在MySQL中,可以使用索引来加速模糊搜索。例如,可以使用LIKE操作符作为模糊搜索的关键字,并将需要搜索的列添加到索引中。
- 缩小查询范围:在进行模糊搜索时,如果数据量较大,可以考虑缩小查询范围。例如,可以使用WHERE子句指定查询的列和范围,或者使用LIMIT限制返回的结果集大小。
- 使用缓存:如果查询的结果很少变化,可以将结果缓存起来,避免重复计算。例如,可以使用Redis等缓存系统来缓存搜索结果。
- 优化查询语句:在进行模糊搜索时,需要确保查询语句的优化。例如,可以使用POSTGRESQL的CONCAT函数将多个字符串连接起来,或者使用POSTGRESQL的GLOB函数进行模糊搜索。
- 使用分布式存储:如果数据量太大,可以考虑使用分布式存储系统,例如Hadoop、HBase等。这些系统可以将数据分布在多个节点上,从而加快查询速度。
在实际应用中,可能需要结合多种优化方法来实现模糊搜索。通过合理使用上述优化技巧,可以在一秒内实现模糊搜索,同时保证查询效率。
回答:
Everything 应该是做的全文索引。如果字段内容多,建议还是走全文索引。
如果字段内容不多,可以根据实际情况想一点其他途径的优化,
比如先按 LIKE 'XXXX%' 来检索,这个是可以走索引的。检索不出来,或者检索出来数量较少的情况下再使用 '%xxx%' 模糊搜索。
如果是手机尾号搜索这种可以存一个逆序手机号字段,再通过前缀匹配来使用索引检索。
回答:
chatgpt的回答:Everything是一款用于搜索本地电脑文件的软件。它能够快速搜索出电脑中的所有文件,并将搜索结果实时显示在屏幕上。
Everything的搜索速度之所以快,是因为它使用了倒排索引的技术。在倒排索引中,每个文件都对应一个词表,其中包含了该文件中所有出现过的词。当搜索时,Everything只需要查找所有搜索词的词表,然后找出所有词表中共同出现的文件,即可找到所有包含搜索词的文件。
此外,Everything还提供了其他优化搜索速度的技术,比如多线程搜索、内存缓存和磁盘预读等。这些技术能够提高搜索效率,使得Everything的搜索速度更快。
总之,Everything的搜索速度之所以快,是因为它使用了倒排索引的技术,并提供了其他优化搜索速度的技术。这些技术能够快速检索出电脑中的所有文件,并将搜索结果实时显示在屏幕上。
以上是 mysql 一千万的数据量如何一秒内实现模糊搜索? 的全部内容, 来源链接: utcz.com/p/945014.html