浏览器批量下载打包成ZIP时,前端该如何优化下载显示?
浏览器批量下载打包成ZIP文件时,目前能想到的2种方案都无法令人满意,有没有大神提供一种比较友好的下载方案?
方案1、后端直接持续输出文件流,但是无法提供Response Header里的Content-Length属性的值,导致浏览器不能显示下载进度
方案2、后端先把各种文件打包成ZIP包保存到服务器上然后输出ZIP的文件流到前端,这种方式因为ZIP文件已经在服务器上了文件大小可以确定所以可以返回Response Header里的Content-Length属性的值,浏览器可以看到下载进度,但是在等待后端将文件打包成ZIP包的过程中,浏览器是一直在转圈的,并不会下载文件,知道后端打包好ZIP包输出文件流的时候才会开始下载文件
后端打包好之后输出文件流才开始下载
回答:
恰巧最近也刚做过这个需求,实现思路为:浏览器发出下载请求,服务器开始打包,打包时间超过2S,直接响应给前端:文件正在打包,打包完成后自动下载,此时前端可以先干别的事,等待服务器打包完成后使用mqtt将打包后的文件地址发送给前端,前端收到消息根据地址进行下载,并显示进度.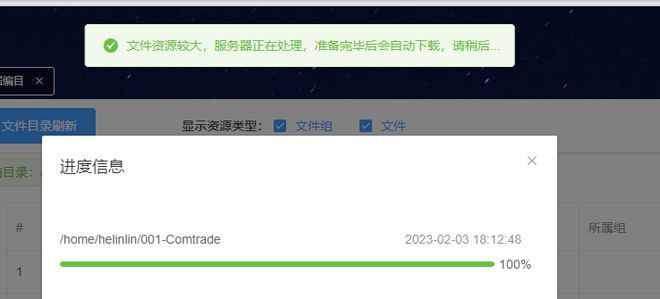
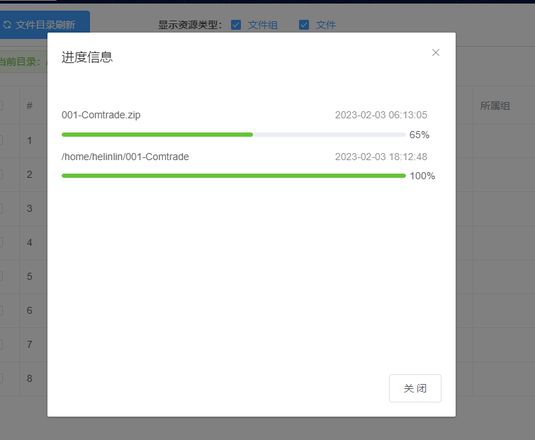
回答:
在我的认知里,无解。
下载进度是计算 总量和已下载 的比值,如果任何一个未知,那怎么算呢?浏览器也不是神啊。
所以问题是,怎么在打包过程中提前知道打包后的压缩包文件大小。
那么新问题来了,还没打包完怎么知道最终的大小呢?
所以,建议下载搞成异步的,提交下载请求,然后界面上可以显示还剩多久打包完(多少个文件是已知的吧),打包完,给个链接(或自动重定向)点击下载。
以上是 浏览器批量下载打包成ZIP时,前端该如何优化下载显示? 的全部内容, 来源链接: utcz.com/p/944961.html