请问如果用正则从文本中抽取按关键词成对匹配的文本?
背景是这样的。 有这样格式的原始文本:
Question 1:
XXXXXXXXXXXXXXXXXXXX
Response 1:
YYYYYYYYYYYYYYYYYYYY
Question 2:
XXXXXXXXXXXXXXXXXXXX
Response 2:
YYYYYYYYYYYYYYYYYYYY
........
现在想用java程序抽取出一对对的Question-Answer对。我自己先弄了个糙快猛的做法,没用regex,主要就是用apache common包里面String工具类的substringBetween方法。 我的大概思路是这样的,首先查找出Response字样的个数。 然后for循环里面进行文本操作, 比如Question 1就取"Question 1:"到"Response 1"字样中间的, Response 1就取"Response 1"到"Question 2"之间的; 最后一个回答单独处理下
这种方案有很大的局限性。 首先是正文里面不能有Response字样(不然第一步查个数就比实际的QA对多了)。 二是对格式的要求限死了,要包括标点符号都符合才行。
然而实际情况是,有的输入文本只有一对QA,就直接是不带番号的,即
Question:
XXXXXXXXXXXXXX
Reponse:
YYYYYYYYYYYYYYYY
还有部分输入文本的标题有些出入,不是Question和Response,而是Comment和Explanation.
我模糊感觉这种应该要用正则表达式来匹配吧。 自己琢磨一段时间,还是没弄出来。求助一下大家思路。
回答:
按行读/按行处理
如果本行是Question开头(或者写个正则匹配一下),那么接下来的是问题
如果本行匹配Response,那么和Question中间的部分是问题
如果本上又是Question,那么答案结束
回答:
(?<=(^|\n)[QR]uestion\s\d\:\s)(1+(?=\n(\w\s\d\:\s*|$)))
试试呢
- \n ↩
回答:
可以通过"Question 1:"+ 换行符 /"Response 1:"+ 换行符 这样的规则来进行匹配
有了规则,无论是使用正则或者其它方式,都是可以解析出来的
回答:
代码:
public static void main(String[] args) { String regex="((?:Question|Comment)\\s*\\d*):([\\s\\S]*?)((?:Response|Explanation)\\s*\\d*):([\\s\\S]*?)(?=(?:Question|Comment)\\s*\\d*:|$)";
String str="背景是这样的。 有这样格式的原始文本:\r\nQuestion 1:\r\nXXXXXXXXXXXResponseXXXXXXXXX\r\nResponse 1:\r\nYYYYYYYYYYYYResponseYYYYYYYY\r\n\r\nQuestion 2:\r\nXXXXXXXXXXXXXXXXXXXX\r\nResponse 2:\r\nYYYYYYYYYYYYYYYYYYYY\r\n\r\nComment 2:\r\nXXXXXXXXXXXXXXXXXXXX\r\nExplanation 2:\r\nYYYYYYYYYYYYYYYYYYYY\r\nQuestion :\r\nXXXXXXXXXXXXXXXXXXXX\r\nResponse :\r\nYYYYYYYYYYYYYYYYYYYY\r\n";
Matcher m=Pattern.compile(regex).matcher(str);
List<Map<String,String>> items=new ArrayList<Map<String,String>>();
Map<String,String> item=null;
while(m.find()) {
item=new HashMap<String,String>();
item.put(m.group(1), m.group(2));
item.put(m.group(3), m.group(4));
items.add(item);
}
System.out.println(items);
}
结果: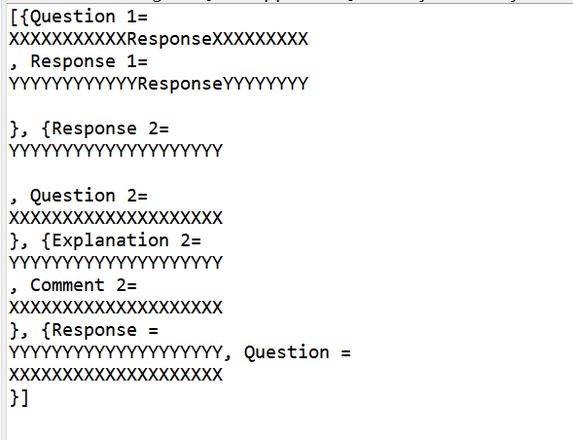
以上是 请问如果用正则从文本中抽取按关键词成对匹配的文本? 的全部内容, 来源链接: utcz.com/p/944899.html

![正则表达式中 [\s\S]* 什么意思 居然能匹配所有字符 [] 不是范围描述符吗?](/wp-content/uploads/thumbs/270159_thumbnail.jpg)