Cassandra 如何实现使用 column name 存储数据
顺便想问一下大家对 CQL 的看法。
为什么我有这个疑问呢?

因为学习 Cassandra 的时候,看的是这两篇教程:
- Cassandra 数据模型设计最佳实践(上部)
- Cassandra 数据模型设计最佳实践(下部)
这两篇教程中是以类似 HBase 的 rowkey、Column Name 和 Column Key 对 Cassandra 加以描述的,但是我在看 Cassandra 的使用教程(Cassandra 教程)的时候。发现 CQL 隐藏了 row key、column Key 这些概念。emmmm...
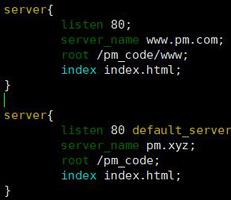
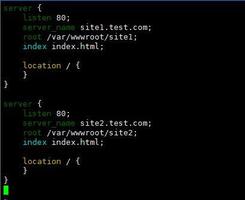
这就带来一个问题,假设我这样使用 Cassandra 来实现保存用户点赞过的所有文章:rowkey 是 user_id,column Key 是 timestamp + tweet_id
每当用户点赞一个文章(tweet),就找到对应的 user_id 的行,新增一列表示点赞记录。
我在 CQL 下去实现的话,等于我不能使用 ”创建数据“ 的 CQL,而是要使用 ”修改表“ 的 CQL 去实现是吗?
修改表:ALTER (TABLE | COLUMNFAMILY) <tablename> <instruction>
创建数据:INSERT INTO <tablename> (<column1 name>, <column2 name>....) VALUES (<value1>, <value2>....) USING <option>
不知道我有没有描述清楚我的提问,大概意思就是把 Cassandra 当宽列数据库来实现的话,就得使用 CQL 的”修改表“而不是”创建数据“来实现数据的插入是吗?
如果是这样的话,等于又要新增 column Key 和 column value 的话,等于要分成两句话来实现了是吗?
即:先 ALTER TABLE,再 INSERT INTO
cassandra 有提供把两个 cql 语句作为一个操作一次执行的功能吗?类似 redis 的 lua 脚本可以把多个操作原子化
以上是 Cassandra 如何实现使用 column name 存储数据 的全部内容, 来源链接: utcz.com/p/944206.html