
用python实现库存的先进先出分配?
我现在有一张表,示例如下,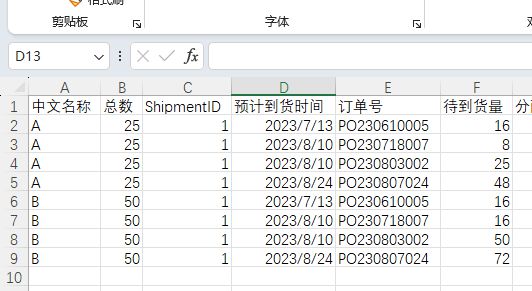
其中总数列是每个产品要出库的数量,
ShipmentID是出库的批次,每个产品可能有很多个批次(虽然示例表只给了一个)
每个产品都对应了很多订单,预计到货时间列是订单号对应的到货时间,
待到货量即订单的数量,
现在需要把每个订单中的待到货量按先进先出即预计到货时间在前的先出,分配给不同批次的出库量。
得到的结果如下图所示。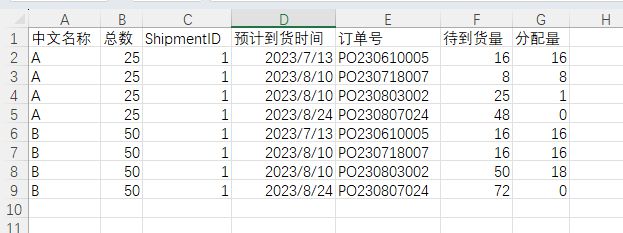
我根据网上搜到的提示,写了半天,写出几行代码,如下所示:
import pandas as pd# 读取表格数据
df = pd.read_excel(r"D:\打单报关数据\PO分配改良.xlsx",sheet_name = "Sheet2")
# 按预计到货时间升序排序
df = df.sort_values(by=['中文名称','ShipmentID','预计到货时间'])
# 创建新列用于记录分配结果
df['分配数量'] = 0
allocated_qty = 0 # 分配数量
df["辅助列"] = df['中文名称']+df['ShipmentID'].astype(str)+df['订单号']
for data_id in df['辅助列'].unique():
data_df = df[df['辅助列'] == data_id]
total_qty = data_df['总数'].sum()
order_qty = data_df['待到货量'].sum()
if order_qty >= total_qty:
allocated_qty = total_qty
else:
allocated_qty = order_qty
df.loc[data_df.index,'分配数量'] = allocated_qty
order_qty = order_qty - allocated_qty
total_qty = total_qty - allocated_qty
if order_qty == 0 and total_qty ==0:
break
df
但是这样写出来的结果是下面这样的: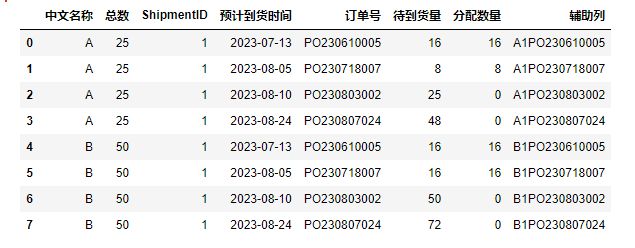
这显然是错的,不知道为什么会出现这样的错误,我想知道正确的怎么写?我知道应该用循坏,但是我实在没写上来。如果有人能够给予帮助,将感激不尽。
回答:
你可以将问题拆解。目前情况是:你需要将某件商品,例如A,总数按照到货时间分配给所有A的分配数量。
那么你按照【中文名称】分组,获得例子中的A=25,B=50。例如有很多种,那么用一个字典储存:d={'A':25,'B':50,'C':100,...}。
表格照旧打开,按照你之前的,并且按照【到货时间】和【中文名称】升序。
接着遍历字典,for k,v in d.items():... 这个k就是ABC,v就是总数。 然后用pandas的条件取值,我pandas很久没用了,具体的你查一下。例如要取中文名称是A的,df['中文名称'==k],然后按照循序,遍历每一个符合条件的,把v不断减少【待到货量】,填到【分配数量】这边。 注意数值边界,不要有负数
以上是 用python实现库存的先进先出分配? 的全部内容, 来源链接: utcz.com/p/938988.html


