无法爬取某网站各项产品的url?
相关代码如图所示(第一段代码选自scraper,已用于第二段代码)
# function to get project urldef extract_project_url(df_input):
list_url = []
for ele in df_input["clickthrough_url"]:
list_url.append("https://www.indiegogo.com" + ele)
return list_url
import syssys.path.append("C:/Users/1/Desktop/indiegogo-scrapper-main/src/main.py")
import os
# load data analysis library
import pandas as pd
# load modules in scraper
from scraper import *
import multiprocessing
def main():
args = sys.argv[1:]
if os.path.exists("chromedriver\\chromedriver.exe") is False:
print("put chromedriver.exe into chromedriver directory.")
else:
if os.path.exists("data\\1.csv") is False:
print("put 1.csv into data directory.")
else:
if len(args) < 1:
print("define the json filename.")
elif args[0].find(".json") != -1:
dir_path_data = "data"
dir_path_output = "out/" + args[0]
filenames = next(os.walk(dir_path_data), (None, None, []))[2]
list_project_site = []
for ele in filenames:
df_indiegogo = pd.read_csv(dir_path_data + "\\" + ele, encoding="gbk", encoding_errors="ignore", sep='\t', on_bad_lines='skip')
list_project_site.extend(extract_project_url(df_indiegogo))
list_project_site = [[i, e] for i, e in enumerate(list_project_site)]
try:
f = open(dir_path_output, "r",)
data = json.loads(f.read())
f.close()
except Exception as e:
data = {}
list_processed = [e for e in list_project_site if e[1]
not in [data[key]["site"] for key in data]]
# process-based parallelism
# use one third of the available processors
processor = int(-1 * (multiprocessing.cpu_count() / 3) // 1 * -1)
# use one fourth of the available processors
# processor = int(multiprocessing.cpu_count()/4)
pool = multiprocessing.Pool(processes=processor)
print("*** start ***")
for b in [list_processed[i:i + processor] for i in range(0, len(list_processed), processor)]:
dict_tmp = {}
list_bres = pool.map(scrapes, b)
for i in list_bres:
dict_tmp.update(i)
if len(data) < 1:
with open(dir_path_output, 'w') as file:
json.dump(dict_tmp, file, indent=4)
else:
with open(dir_path_output, "r+") as file:
old_data = json.load(file)
old_data.update(dict_tmp)
file.seek(0)
json.dump(old_data, file, indent=4)
print("scraped", str(b[-1][0] + 1), "of", str(len(list_project_site) - 1))
break
else:
print("wrong output file extension. use json extension.")
print("*** end ***")
if __name__ == '__main__':
main()
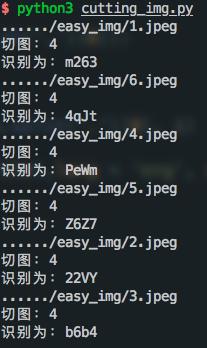
结果如下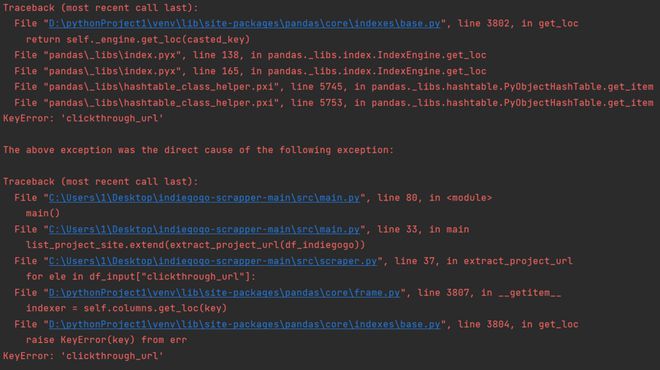
听从网上建议修改后代码和结果
# function to get project urldef extract_project_url(df_input):
list_url = []
for ele in df_input[["clickthrough_url"]]:
list_url.append("https://www.indiegogo.com" + ele)
return list_url
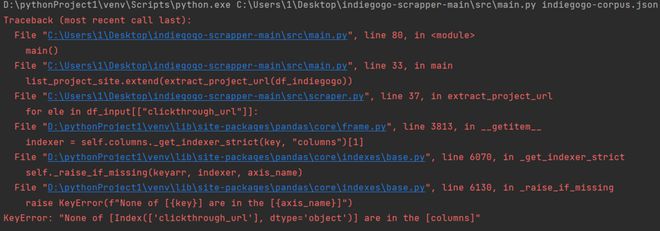
求助各位大佬此修改是否正确,错误的原因是否跟设置cookie有关,以及后续应该如何编程。如果觉得麻烦,请给予相关连接让萌新自行学习,十分感谢!
以上是 无法爬取某网站各项产品的url? 的全部内容, 来源链接: utcz.com/p/938845.html