python爬取微博正常的评论文本,为什么会得到像U+200E、U+202E、U+202C这样的奇怪字符串?
这是我用requests库在微博上爬取关于堕胎评论的时候得到的奇怪字符串: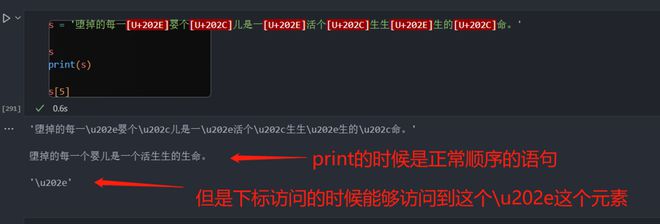
字符串顺序是乱的,但是通过print函数打印这个字符串却是正常的,我把这个字符串放到pandas的dataframe里面过后这堆字符串也能正常显示,但是一旦通过下标访问,或者遍历这个字符串的时候,他还是有这种\u202e这样的字符,而且顺序也是乱的。
我去微博看了原博然后手动复制,也是正常的字符串。我检查了一下编码,微博的网页是utf-8没错,我也指定了 response 对象为utf-8编码 response.encoding='utf-8'
请问为什么爬虫会爬取到这样夹杂着一堆\u202e \u202c的字符串?怎么把这种字符串转换成正常的字符串呢?
另外,我的requests版本是2.27.1,python版本是3.8.13。
回答:
\u202E 和 \u202C 是方向格式控制符\u202E 会使后面字符从右往左显示,\u202C 是取消方向格式
所以把 \u202E\u202C 删除,再把中间字符反转回来即可
import rereversedRE = re.compile(r'\u202E(.*?)(?:\u202C|$)', re.DOTALL)
s = '\u202Ecba\u202Cdef\u202Eihg\u202C'
print(s)
s = reversedRE.sub(lambda m: m[1][::-1], s)
print(s) # abcdefghi
以上是 python爬取微博正常的评论文本,为什么会得到像U+200E、U+202E、U+202C这样的奇怪字符串? 的全部内容, 来源链接: utcz.com/p/938560.html