Python 字符串对象实现原理
在 Python 世界中将对象分为两种:一种是定长对象,比如整数,整数对象定义的时候就能确定它所占用的内存空间大小,另一种是变长对象,在对象定义时并不知道是多少,比如:str,list, set, dict等。
>>> import sys>>> sys.getsizeof(1000)
28
>>> sys.getsizeof(2000)
28
>>> sys.getsizeof("python")
55
>>> sys.getsizeof("java")
53
如上,整数对象所占用的内存都是28字节,和具体的值没关系,而同样都是字符串对象,不同字符串对象所占用的内存是不一样的,这就是变长对象,对于变长对象,在对象定义时是不知道对象所占用的内存空间是多少的。
字符串对象在 Python 内部用PyStringObject表示,PyStringObject和PyIntObject一样都属于不可变对象,对象一旦创建就不能改变其值。(注意:变长对象和不可变对象是两个不同的概念)。PythonStringObject的定义:
[stringobject.h]typedef struct {
PyObject_VAR_HEAD
long ob_shash;
int ob_sstate;
char ob_sval[1];
} PyStringObject;
不难看出Python的字符串对象内部就是由一个字符数组维护的,在整数的实现原理一文中提到PyObject_HEAD,对于PyObject_VAR_HEAD就是在PyObject_HEAD基础上多出一个ob_size属性:
[object.h]#define PyObject_VAR_HEAD
PyObject_HEAD
int ob_size; /* Number of items in variable part */
typedef struct {
PyObject_VAR_HEAD
} PyVarObject;
ob_size保存了变长对象中元素的长度,比如PyStringObject对象”Python”的ob_size为6。ob_sval是一个初始大小为1的字符数组,且ob_sval[0] = ‘\0’,但实际上创建一个PyStringObject时ob_sval指向的是一段长为ob_size+1个字节的内存。ob_shash是字符串对象的哈希值,初始值为-1,在第一次计算出字符串的哈希值后,会把该值缓存下来,赋值给ob_shash。ob_sstate用于标记该字符串对象是否进过intern机制处理(后文会介绍)。
PyStringObject 对象创建过程
[stringobject.c]PyObject * PyString_FromString(const char *str)
{
register size_t size;
register PyStringObject *op;
assert(str != NULL);
size = strlen(str);
// [1]
if (size > PY_SSIZE_T_MAX - PyStringObject_SIZE) {
PyErr_SetString(PyExc_OverflowError,
"string is too long for a Python string");
return NULL;
}
// [2]
if (size == 0 && (op = nullstring) != NULL) {
#ifdef COUNT_ALLOCS
null_strings++;
#endif
Py_INCREF(op);
return (PyObject *)op;
}
// [3]
if (size == 1 && (op = characters[*str & UCHAR_MAX]) != NULL) {
#ifdef COUNT_ALLOCS
one_strings++;
#endif
Py_INCREF(op);
return (PyObject *)op;
}
// [4]
/* Inline PyObject_NewVar */
op = (PyStringObject *)PyObject_MALLOC(PyStringObject_SIZE + size);
if (op == NULL)
return PyErr_NoMemory();
PyObject_INIT_VAR(op, &PyString_Type, size);
op->ob_shash = -1;
op->ob_sstate = SSTATE_NOT_INTERNED;
Py_MEMCPY(op->ob_sval, str, size+1);
/* share short strings */
if (size == 0) {
PyObject *t = (PyObject *)op;
PyString_InternInPlace(&t);
op = (PyStringObject *)t;
nullstring = op;
Py_INCREF(op);
} else if (size == 1) {
PyObject *t = (PyObject *)op;
PyString_InternInPlace(&t);
op = (PyStringObject *)t;
characters[*str & UCHAR_MAX] = op;
Py_INCREF(op);
}
return (PyObject *) op;
}
- 如果字符串的长度超出了Python所能接受的最大长度(32位平台是2G),则返回Null。
- 如果是空字符串,那么返回特殊的PyStringObject,即nullstring。
- 如果字符串的长度为1,那么返回特殊PyStringObject,即onestring。
- 其他情况下就是分配内存,初始化PyStringObject,把参数str的字符数组拷贝到PyStringObject中的
ob_sval指向的内存空间。
字符串的 intern 机制
PyStringObject的ob_sstate属性用于标记字符串对象是否经过intern机制处理,intern处理后的字符串,比如”Python”,在解释器运行过程中始终只有唯一的一个字符串”Python”对应的PyStringObject对象。
>>> a = "python">>> b = "python"
>>> a is b
True
如上所示,创建a时,系统首先会创建一个新的PyStringObject对象出来,然后经过intern机制处理(PyString_InternInPlace),接着查找经过intern机制处理的PyStringObject对象,如果发现有该字符串对应的PyStringObject存在,则直接返回该对象,否则把刚刚创建的PyStringObject加入到intern机制中。由于a和b字符串字面值是一样的,因此a和b都指向同一个PyStringObject(“python”)对象。那么intern内部又是一个什么样的机制呢?
[stringobject.c]static PyObject *interned;
void PyString_InternInPlace(PyObject **p)
{
register PyStringObject *s = (PyStringObject *)(*p);
PyObject *t;
if (s == NULL || !PyString_Check(s))
Py_FatalError("PyString_InternInPlace: strings only please!");
/* If it's a string subclass, we don't really know what putting
it in the interned dict might do. */
// [1]
if (!PyString_CheckExact(s))
return;
// [2]
if (PyString_CHECK_INTERNED(s))
return;
// [3]
if (interned == NULL) {
interned = PyDict_New();
if (interned == NULL) {
PyErr_Clear(); /* Don't leave an exception */
return;
}
}
t = PyDict_GetItem(interned, (PyObject *)s);
if (t) {
Py_INCREF(t);
Py_DECREF(*p);
*p = t;
return;
}
if (PyDict_SetItem(interned, (PyObject *)s, (PyObject *)s) < 0) {
PyErr_Clear();
return;
}
/* The two references in interned are not counted by refcnt.
The string deallocator will take care of this */
Py_REFCNT(s) -= 2;
PyString_CHECK_INTERNED(s) = SSTATE_INTERNED_MORTAL;
}
- 先类型检查,intern机制只处理字符串
- 如果该PyStringObject对象已经进行过intern机制处理,则直接返回
- interned其实一个字典对象,当它为null时,初始化一个字典对象,否则,看该字典中是否存在一个key为
(PyObject *)s的value,如果存在,那么就把该对象的引用计数加1,临时创建的那个对象的引用计数减1。否则,把(PyObject *)s同时作为key和value添加到interned字典中,与此同时它的引用计数减2,这两个引用计数减2是因为被interned字典所引用,但这两个引用不作为垃圾回收的判断依据,否则,字符串对象永远都不会被垃圾回收器收集了。
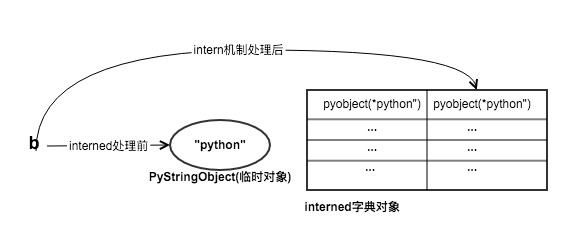
上述代码中,给b赋值为”python”后,系统中创建了几个PyStringObject对象呢?答案是:2,在创建b的时候,一定会有一个临时的PyStringObject作为字典的key在interned中查找是否存在一个PyStringObject对象的值为”python”。
字符串的缓冲池
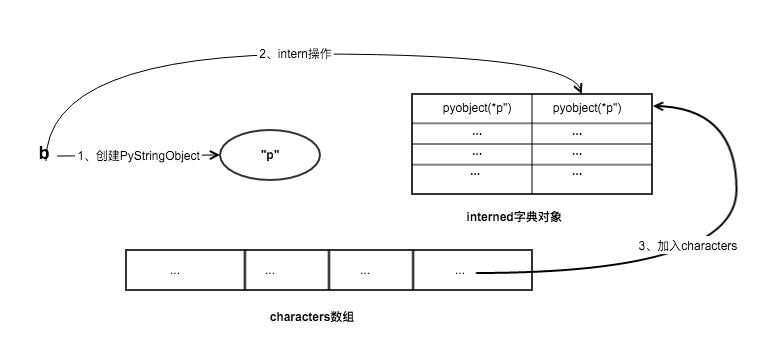
字符串除了有intern机制缓存字符串之外,字符串还有一种专门的短字符串缓冲池characters。用于缓存字符串长度为1的PyStringObject对象。
static PyStringObject *characters[UCHAR_MAX + 1]; //UCHAR_MAX = 255
创建长度为1的字符串时流程:
...else if (size == 1) {
PyObject *t = (PyObject *)op;
PyString_InternInPlace(&t);
op = (PyStringObject *)t;
characters[*str & UCHAR_MAX] = op;
Py_INCREF(op);
- 首先创建一个PyStringObject对象。
- 进行intern操作
- 将PyStringObject缓存到characters中
- 引用计数增1
总结
- 字符串用 PyStringObject 表示
- 字符串属于变长对象
- 字符串属于不可变对象
- 字符串用 intern 机制提高 python 的效率
- 字符串有专门的缓冲池存储长度为1的字符串对象
以上是 Python 字符串对象实现原理 的全部内容, 来源链接: utcz.com/p/233336.html