一个Python 爬虫 (javascript动态数据) 的难题?
- 最近学习javascript 动态数据的python爬虫. 一般都是在谷歌浏览器里打断点单步执行调试
- 然后一般都是单步执行几步或十几步就结束.
- 然后分析每一步的逻辑
- 基本上没问题
现在遇到一个网站就很奇怪
- 访问
https://www.anobii.com/zh-Hant/search/9789620764547/books - 真正请求页是
https://api.anobii.com/editions/search?search=9789620764547&page=0&language=&locale=IT - 预览里有json数据
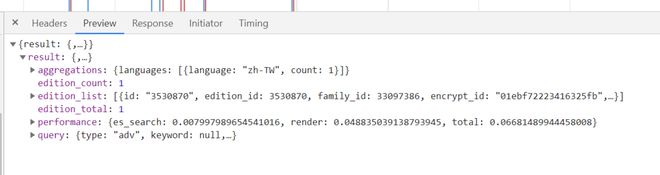
- 确定js文件
https://www.anobii.com/main.323b679edc82241a.js, 并搜索关键字editions/search - 在文件中只有两处, 在第一处打断点.刷新页面, 成功暂停.
- 然后单步执行, 点了几百步, 还没结束, 也不是单一的循环.
- 像这种情况, 总不可能去一步步分析逻辑吧? 几百甚至上千步, 代码近6万行.
- 那该怎么处理呢??
- 访问
回答:
算了
# -*- coding: UTF-8 -*-import requests as r
__author__ = 'lpe234'
def get_token():
url = 'https://api.anobii.com/auth/token'
data = {
"grant_type": "client_credentials",
"client_id": "6cb3a6ab746f553c4330b74906ba55cb",
"client_secret": "fG3d1y1izNS5cZlClKkxm5bC1MjQch5z"
}
resp = r.post(url, json=data)
if resp.ok:
return resp.json()['result']['token']
return None
def search(params: str, token: str):
url = 'https://api.anobii.com/editions/search?search={}&page=0&language=&locale=IT'.format(params)
headers = {
'Authorization': 'Bearer ' + token
}
resp = r.get(url, headers=headers)
print(resp.json())
def main():
token = get_token()
if token:
search('python', token)
if __name__ == '__main__':
main()
你想分析啥呢。请求参数很清晰呀。
URL: https://api.anobii.com/editions/searchparams: search=python&page=0&language=&locale=IT
再加个jwt的headers. authorization
jwt示例: {"typ":"JWT","alg":"RS256"}{"iat":1654039290,"exp":1654125690,"sub":"","iss":"https://api.anobii.com","aud":"1000002","roles":[],"email":"guest@anobii.com","ip":"124.133.119.214","cc":"CN"}
直接请求就行了。完全没啥可分析的
或者你研究一下有道翻译吧,那个有点签名。就研究下sign怎么生成的。 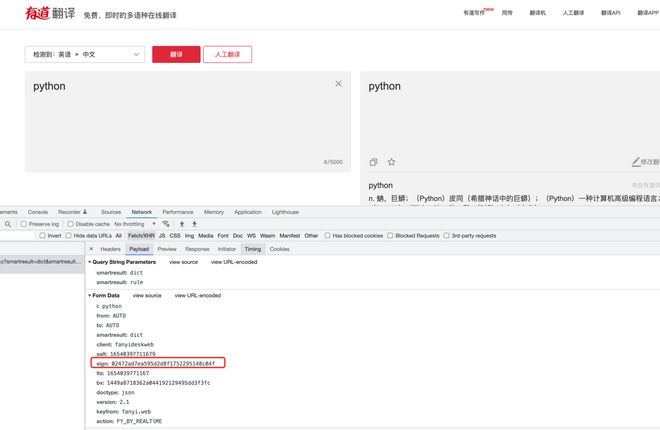
已参与了 SegmentFault 思否社区 10 周年「问答」打卡 ,欢迎正在阅读的你也加入。
以上是 一个Python 爬虫 (javascript动态数据) 的难题? 的全部内容, 来源链接: utcz.com/p/938452.html