
Python 根据条件查找对应物质并记录
有一个config file: dfspeciesConfig,
for col in wavecolM3L:
如果wavecolM3L list中(Col-1,Col+1) 范围内在dfspeciesConfig里面能找到对应物质, 则保留此wave, 并记录相应的species (SiO/Ni),请问如何写?
wavecolM3L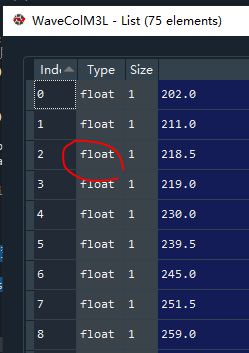
2022.05.17
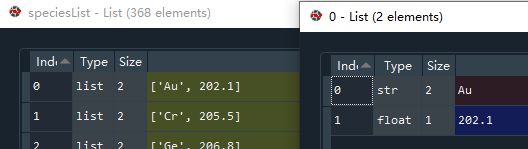
这里面speciesList 是pConfig返回的结果,跟您帮我写的那个是一个意思么? 但是有个报错
dfspeciesConfig 和需要与原始speciesList(config 标准表)比对的待比对物质列表
2022.05.17 18:15
就差一点点了, 运行单个inP =241.0, 查找到的物质是对的, 数据类型按您的改了,运行报错如下, 仍然提示'TypeError: 'float' object is not subscriptable: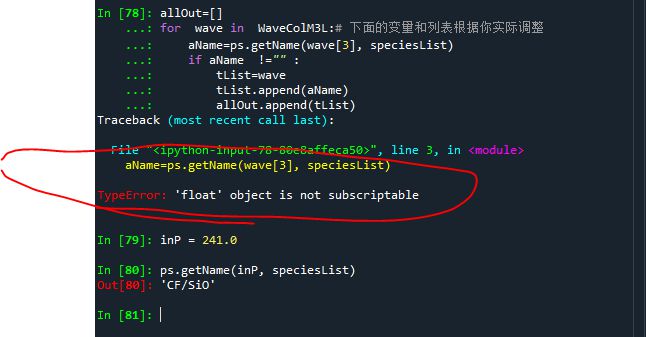
回答:
我理解,你看是否是这样的:
- 有一个名为dfspeciesConfig的配置文件中,记录了物质(名)和对应的物质特性值,比如Au对应的是201.2
- 在WaveColM3L中记录了某种测试的 物质特性值 列表
- 现在遍历WaveColM3L的每条记录,判断每条记录是否 对应于dfspeciesConfig 中的某个物质(特性),如果有对应的,则保留该记录,并在其后标注 对应的 物质名
其中3的比较中测试记录的物质特性值可能存在偏差,其对应的物质特性可能存在 正负1 的偏差,即如果 记录的值 在 某个配置值的正负1范围内,还是认为是对应于该物质。
如果是这样的,这其实类似一个特殊的查表过程,因为待查表是一个范围表,即首先需要对dfspeciesConfig解析,生成一个待查的范围表(注意这个表不能有重叠区域)
然后就是遍历过程,这里其实还需要明确所谓的保留是指什么,如果没有查到对应物质的要怎么处理?我觉得可能都要保留,只是对查到的多标注对应查到的物质可能更好。
这个估计是什么研究项目中的数据处理?!
根据题主新的介绍,我觉得关键有2个处理过程
- 就是对dfspeciesConfig预处理为一个物质特性升序排列的物质特性与物质名列表
定义一个根据物质特性查表的函数
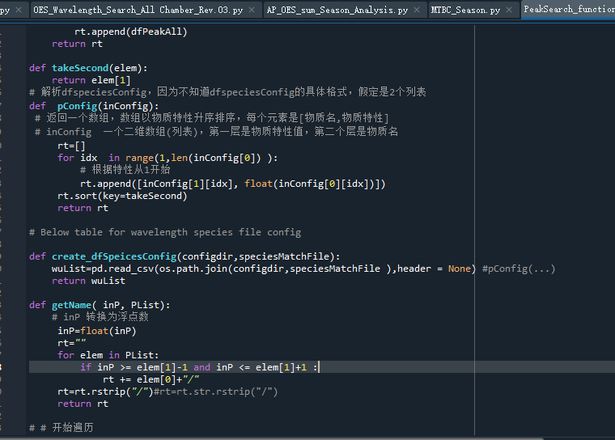
下面是这个的伪实现python">def takeSecond(elem):return elem[1]
# 解析dfspeciesConfig,因为不知道dfspeciesConfig的具体格式,假定是2个列表
def pConfig(inConfig):
# 返回一个数组,数组以物质特性升序排序,每个元素是[物质名,物质特性]
# inConfig 一个二维数组(列表),第一层是物质特性值,第二个层是物质名
rt=[]
for idx in range(len(inConfig[0]) ):
# 根据特性从0开始,下面处理了数据类型,强制转换为浮点数
rt.append([inConfig[1][idx], float(inConfig[0][idx])])
rt=rt.sort(key=takeSecond)
return rt
# 下面填入正确的数据来源
wuList=pConfig(...)
def getName( inP, PList):
rt=""
# inP 转换为浮点数
inP=float(inP)
for elem in PList:
if inP>=elem[1]-1 and inP<= elem[1]+1 :
rt+=elem[0]+"/"
rt=rt.str.rstrip("/")
return rt
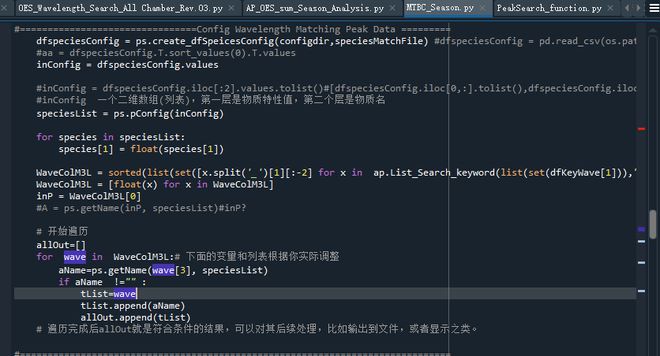
# 开始遍历
allOut=[]
# 下面的变量和列表根据你实际调整
for X in XList :
aName=getName(X, wuList )
if aName !="" :
tList=[X]
tList.append(aName)
allOut.append(tList)
# 遍历完成后allOut就是符合条件的结果,可以对其后续处理,比如输出到文件,或者显示之类。
因为上述代码没有合适的数据进行验证测试,所以是伪代码,需要根据实际调整部分地方可能才能正常工作。包括但不限于列表索引关系、数据类型转换处理等。
以上是 Python 根据条件查找对应物质并记录 的全部内容, 来源链接: utcz.com/p/938410.html



