爬虫ConnectionError MaxRetryError怎么解决?
试了两种代码,找了无数解决方案。。。
也解决不了
错误如下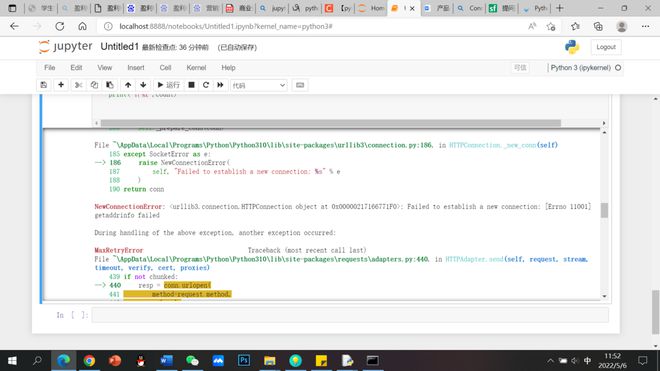
我的代码
import pandas as pdimport random
from time import sleep
import requests
save_path='D:/年报'
download_path='http://static.cninfo.com.cn/'
User_Agent=['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36 Edg/100.0.1185.29']
headers={
'Host':'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Accept-Encoding': 'gzip, deflate',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json, text/javascript,*/*;q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'origin':'www.cninfo.com.cn',
'referer':'www.cninfo.com.cn/new/commonurl?url=disloure/list/notice',
'X-Requested-With': 'XMLHttpRequest',
}
def get_orgid(namelist):
orglist=[]
url = "http://www.cninfo.com./new/information/topSearch/detailOfQuery"
hd={
'Host':'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma':'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'close',
'Content -Length': '70',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36 Edg/100.0.1185.29',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json, text/javascript,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
for name in namelist:
data = {
'keyWord':name,
'maxSecNum': 10,
'maxListNum': 5,
}
r = requests.post(url,headers=hd,data=data)
org_id=r.json()["keyBoardList"][0]["orgId"]
orglist.append(org_id)
formatlist=list(set(orglist))
formatlist.sort(key=orglist.index)
return formatlist
def single_page(stock):
query_path = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
headers['User-Agent']=random.choice(User_Agent)
print(stock)
query = {
'stock' : stock,
'tabName ' : 'fulltext',
'pageSize': 30,
'pageNum': 1,
'column': 'szse',
'category': 'category_ndbg_szsh; ',
'plate': '',
'seDate': '',
'trade':'',
'searchkey ': '',
'secid': '',
'sortName': '',
'sortType':'',
'isHLtitle': 'true',
}
namelist=request.post(query_path,headers=headers,data=query)
single_page=namelist.json()['announcements']
print(len(single_page))
return single_page
def saving(single_page):
headers={
'Host':'www.cninfo.com.cn',
'Connection': 'close',
'upgrade-insecure-requests':'1',
'Accept-Encoding': 'gzip, deflate',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q-0.7,en-US;q=0.6',
'referer':'www.cninfo.com.cn/new/commonurl?url=disloure/list/notice',
'Cookie':'routeID=ucl',
}
for i in single_page:
if "摘要"in i['announcementTitle'] or "公告" in i['announcementTitle']:
continue
elif "年年度报告"in i['announcementTitle']:
download = download_path + i["adjunctUr1"]
file_path = saving_path +'/'+name
print(file_path)
time.sleep(random.random()* 2)
headers[ 'User-Agent']= random.choice(User_Agent)
r = requests.get(download,headers=headers)
time.sleep(10)
print(r.status_code)
f= open(file_path,"wb")
f.write(r.content)
f.close()
if __name__== '__main__':
Sec = pd.read_excel('C:/Users/dell/Desktop/01.xlsx',dtype={'code':'object'})
Seclist = list(Sec['code'])
Namelist = list(Sec['name'])
org_list= get_orgid(Namelist)
Sec['orgid'] = org_list
Sec.to_excel('C:/Users/dell/Desktop/01.xlsx',sheet_name='sheet-2',index=False)
stock = ''
count = 0
for rows in Sec.iterrows():
stock = str(rows[1]['code'])+','+str(rows[1]['orgid'])+':'
try:
page_data = single_page(stock)
except:
print('page error')
saving(page_data)
count = count+1
print('计数',count)
实在不懂,求帮助!!!
补充
gaierror Traceback (most recent call last)File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\urllib3\connection.py:174, in HTTPConnection._new_conn(self)
173 try:
--> 174 conn = connection.create_connection(
175 (self._dns_host, self.port), self.timeout, **extra_kw
176 )
178 except SocketTimeout:
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\urllib3\util\connection.py:72, in create_connection(address, timeout, source_address, socket_options)
68 return six.raise_from(
69 LocationParseError(u"'%s', label empty or too long" % host), None
70 )
---> 72 for res in socket.getaddrinfo(host, port, family, socket.SOCK_STREAM):
73 af, socktype, proto, canonname, sa = res
File ~\AppData\Local\Programs\Python\Python310\lib\socket.py:955, in getaddrinfo(host, port, family, type, proto, flags)
954 addrlist = []
--> 955 for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
956 af, socktype, proto, canonname, sa = res
gaierror: [Errno 11001] getaddrinfo failed
During handling of the above exception, another exception occurred:
NewConnectionError Traceback (most recent call last)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\urllib3\connectionpool.py:703, in HTTPConnectionPool.urlopen(self, method, url, body, headers, retries, redirect, assert_same_host, timeout, pool_timeout, release_conn, chunked, body_pos, **response_kw)
702 # Make the request on the httplib connection object.
--> 703 httplib_response = self._make_request(
704 conn,
705 method,
706 url,
707 timeout=timeout_obj,
708 body=body,
709 headers=headers,
710 chunked=chunked,
711 )
713 # If we're going to release the connection in ``finally:``, then
714 # the response doesn't need to know about the connection. Otherwise
715 # it will also try to release it and we'll have a double-release
716 # mess.
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\urllib3\connectionpool.py:398, in HTTPConnectionPool._make_request(self, conn, method, url, timeout, chunked, **httplib_request_kw)
397 else:
--> 398 conn.request(method, url, **httplib_request_kw)
400 # We are swallowing BrokenPipeError (errno.EPIPE) since the server is
401 # legitimately able to close the connection after sending a valid response.
402 # With this behaviour, the received response is still readable.
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\urllib3\connection.py:239, in HTTPConnection.request(self, method, url, body, headers)
238 headers["User-Agent"] = _get_default_user_agent()
--> 239 super(HTTPConnection, self).request(method, url, body=body, headers=headers)
File ~\AppData\Local\Programs\Python\Python310\lib\http\client.py:1282, in HTTPConnection.request(self, method, url, body, headers, encode_chunked)
1281 """Send a complete request to the server."""
-> 1282 self._send_request(method, url, body, headers, encode_chunked)
File ~\AppData\Local\Programs\Python\Python310\lib\http\client.py:1328, in HTTPConnection._send_request(self, method, url, body, headers, encode_chunked)
1327 body = _encode(body, 'body')
-> 1328 self.endheaders(body, encode_chunked=encode_chunked)
File ~\AppData\Local\Programs\Python\Python310\lib\http\client.py:1277, in HTTPConnection.endheaders(self, message_body, encode_chunked)
1276 raise CannotSendHeader()
-> 1277 self._send_output(message_body, encode_chunked=encode_chunked)
File ~\AppData\Local\Programs\Python\Python310\lib\http\client.py:1037, in HTTPConnection._send_output(self, message_body, encode_chunked)
1036 del self._buffer[:]
-> 1037 self.send(msg)
1039 if message_body is not None:
1040
1041 # create a consistent interface to message_body
File ~\AppData\Local\Programs\Python\Python310\lib\http\client.py:975, in HTTPConnection.send(self, data)
974 if self.auto_open:
--> 975 self.connect()
976 else:
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\urllib3\connection.py:205, in HTTPConnection.connect(self)
204 def connect(self):
--> 205 conn = self._new_conn()
206 self._prepare_conn(conn)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\urllib3\connection.py:186, in HTTPConnection._new_conn(self)
185 except SocketError as e:
--> 186 raise NewConnectionError(
187 self, "Failed to establish a new connection: %s" % e
188 )
190 return conn
NewConnectionError: <urllib3.connection.HTTPConnection object at 0x0000025D9346B1F0>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed
During handling of the above exception, another exception occurred:
MaxRetryError Traceback (most recent call last)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\requests\adapters.py:440, in HTTPAdapter.send(self, request, stream, timeout, verify, cert, proxies)
439 if not chunked:
--> 440 resp = conn.urlopen(
441 method=request.method,
442 url=url,
443 body=request.body,
444 headers=request.headers,
445 redirect=False,
446 assert_same_host=False,
447 preload_content=False,
448 decode_content=False,
449 retries=self.max_retries,
450 timeout=timeout
451 )
453 # Send the request.
454 else:
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\urllib3\connectionpool.py:785, in HTTPConnectionPool.urlopen(self, method, url, body, headers, retries, redirect, assert_same_host, timeout, pool_timeout, release_conn, chunked, body_pos, **response_kw)
783 e = ProtocolError("Connection aborted.", e)
--> 785 retries = retries.increment(
786 method, url, error=e, _pool=self, _stacktrace=sys.exc_info()[2]
787 )
788 retries.sleep()
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\urllib3\util\retry.py:592, in Retry.increment(self, method, url, response, error, _pool, _stacktrace)
591 if new_retry.is_exhausted():
--> 592 raise MaxRetryError(_pool, url, error or ResponseError(cause))
594 log.debug("Incremented Retry for (url='%s'): %r", url, new_retry)
MaxRetryError: HTTPConnectionPool(host='www.cninfo.com.', port=80): Max retries exceeded with url: /new/information/topSearch/detailOfQuery (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x0000025D9346B1F0>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed'))
During handling of the above exception, another exception occurred:
ConnectionError Traceback (most recent call last)
Input In [2], in <cell line: 103>()
105 Seclist = list(Sec['code'])
106 Namelist = list(Sec['name'])
--> 107 org_list= get_orgid(Namelist)
108 Sec['orgid'] = org_list
110 Sec.to_excel('C:/Users/dell/Desktop/01.xlsx',sheet_name='sheet-2',index=False)
Input In [2], in get_orgid(namelist)
37 for name in namelist:
38 data = {
39 'keyWord':name,
40 'maxSecNum': 10,
41 'maxListNum': 5,
42 }
---> 43 r = requests.post(url,headers=hd,data=data)
44 org_id=r.json()["keyBoardList"][0]["orgId"]
45 orglist.append(org_id)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\requests\api.py:117, in post(url, data, json, **kwargs)
105 def post(url, data=None, json=None, **kwargs):
106 r"""Sends a POST request.
107
108 :param url: URL for the new :class:`Request` object.
(...)
114 :rtype: requests.Response
115 """
--> 117 return request('post', url, data=data, json=json, **kwargs)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\requests\api.py:61, in request(method, url, **kwargs)
57 # By using the 'with' statement we are sure the session is closed, thus we
58 # avoid leaving sockets open which can trigger a ResourceWarning in some
59 # cases, and look like a memory leak in others.
60 with sessions.Session() as session:
---> 61 return session.request(method=method, url=url, **kwargs)
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\requests\sessions.py:529, in Session.request(self, method, url, params, data, headers, cookies, files, auth, timeout, allow_redirects, proxies, hooks, stream, verify, cert, json)
524 send_kwargs = {
525 'timeout': timeout,
526 'allow_redirects': allow_redirects,
527 }
528 send_kwargs.update(settings)
--> 529 resp = self.send(prep, **send_kwargs)
531 return resp
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\requests\sessions.py:645, in Session.send(self, request, **kwargs)
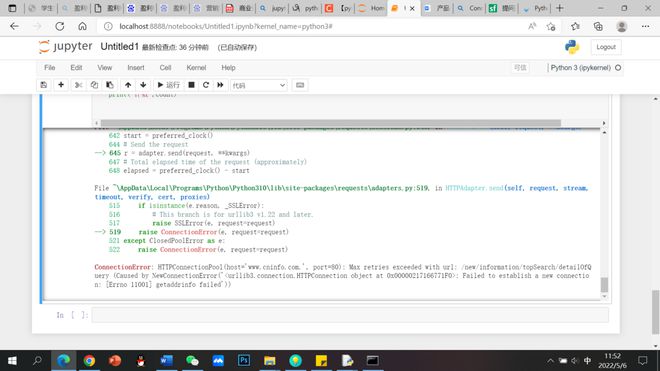
642 start = preferred_clock()
644 # Send the request
--> 645 r = adapter.send(request, **kwargs)
647 # Total elapsed time of the request (approximately)
648 elapsed = preferred_clock() - start
File ~\AppData\Local\Programs\Python\Python310\lib\site-packages\requests\adapters.py:519, in HTTPAdapter.send(self, request, stream, timeout, verify, cert, proxies)
515 if isinstance(e.reason, _SSLError):
516 # This branch is for urllib3 v1.22 and later.
517 raise SSLError(e, request=request)
--> 519 raise ConnectionError(e, request=request)
521 except ClosedPoolError as e:
522 raise ConnectionError(e, request=request)
ConnectionError: HTTPConnectionPool(host='www.cninfo.com.', port=80): Max retries exceeded with url: /new/information/topSearch/detailOfQuery (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x0000025D9346B1F0>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed'))
回答:
首先,你截图的报错信息没有截到最关键的地方(哪一行出错),一般来说拍错首先要定位到错误出现在哪里,才能准确判断错误。
ConnectionError MaxRetryError 通常出现在网络请求失败的时候,无非是网络不可达或者目标网站有反爬机制。
网络不可达
- 检查目标网站能否访问
- 检查 URL 能否访问
反爬机制
- 通过变换 UA 尝试能否访问
- 判断是否存在其他反爬机制
调试爬虫之前要确保你的 HTTP 请求在浏览器中能接收到响应。
以上是 爬虫ConnectionError MaxRetryError怎么解决? 的全部内容, 来源链接: utcz.com/p/938406.html