pandas groupby 计算不同参数的unique 值
pandas groupby 计算unique值,其中第一个Para['uniCount'], 运行为nan, 2 成功了,写法都一样 帮忙看下哪里错了, 或者换种写法?
1.
para['uniCount'] = dfpartable.groupby('Par', as_index=True).apply(lambda x: x.Value.nunique())
2.
paraStep['uniCount'] = dfpartable.groupby(['Par','Step'], as_index=True).apply(lambda x: x.Value.nunique())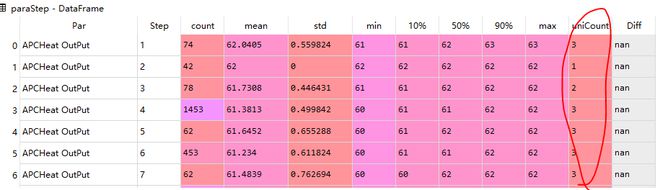
- dfpartable 如下
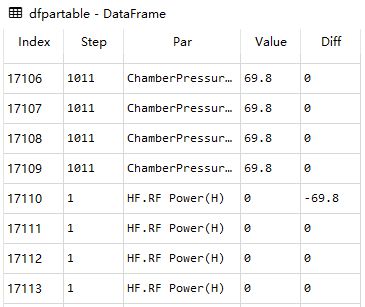
回答:
这两组代码应该都无法运行成功吧?理论上 groupby 之后的 index 和之前的 index 是对不上的,建立新列肯定会有产生 NAN。建议直接使用 transform:
>>> df['uniCount'] = df.groupby('Par')['Value'].transform('nunique')以上是 pandas groupby 计算不同参数的unique 值 的全部内容, 来源链接: utcz.com/p/938154.html