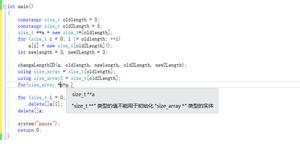
为什么aiofiles 比普通文件操作还要慢?

多个日志文件中查找是否含有某个字符串,发现aiofiles很慢,不知道是否使用方法有误?恳请指点
files = [ r'C:\log\20210523.log',
r'C:\log\20210522.log',
r'C:\log\20210521.log',
r'C:\log\20210524.log',
r'C:\log\20210525.log',
r'C:\log\20210520.log',
r'C:\log\20210519.log',
]
async def match_content_in_file(filename:str,content:str,encoding:str="gbk")->bool:
async with aiofiles.open(filename,mode="r",encoding=encoding) as f:
# text = await f.read()
# return content in text
async for line in f:
if content in line:
return True
def match_content_in_file2(filename:str,content:str,encoding:str="gbk")->bool:
with open(filename,mode="r",encoding=encoding) as f:
# text = f.read()
# return content in text
for line in f:
if content in line:
return True
async def main3():
start = time.time()
tasks = [match_content_in_file(f,'808395') for f in files]
l = await asyncio.gather(*tasks)
print(l)
end = time.time()
print(end - start)
def main2():
start = time.time()
l = []
for f in files:
l.append(match_content_in_file2(f,'808395'))
print(l)
end = time.time()
print(end-start)
if __name__ == '__main__':
asyncio.run(main3()) # 很慢
main2() # 很快
实测情况(每个文件约7.5M)
- 逐行读取文件内容异步方式耗时巨大。
[True, True, True, None, None, True, True]异步方式: 40.80606389045715
-------------------------------------
[True, True, True, None, None, True, True]
同步方式: 0.48870062828063965
- 一次性读取文件内容,异步方式和同步方式差别不大,但还是同步快一点
[True, True, True, False, False, True, True]异步方式: 0.6835882663726807
-------------------------------------
[True, True, True, False, False, True, True]
同步方式: 0.6745946407318115
环境
python 3.9.2 win10
回答:
硬盘读取一个文件是最快的, 同时多读几个文件, 要在多个磁盘块中反复切换, 反而慢.
读文件和网络通讯不一样, 网络请求是在发送后, 需要等待, 这个时候可以使用协程提升并发数量.
硬盘不行.
回答:
aio是io复用,只能解决io性能问题,可以看下cpu,如果单核cpu已经打满了的话,用协程也不会提升性能的
回答:
为什么我测试正好相反呢, 环境 3.8.2
import timeimport asyncio
files = [
r'C:\log\20210523.log',
r'C:\log\20210522.log',
r'C:\log\20210521.log',
r'C:\log\20210524.log',
r'C:\log\20210525.log',
r'C:\log\20210520.log',
r'C:\log\20210519.log',
]
def match_content_in_file(f, s):
time.sleep(1) # 都是sleep 1s
async def match_content_in_file_asc(f,s):
await asyncio.sleep(1) # 都是sleep 1s
async def main3():
start = time.time()
tasks = [match_content_in_file_asc(f,'808395') for f in files]
l = await asyncio.gather(*tasks)
print(l)
end = time.time()
print(end - start)
def main2():
start = time.time()
l = []
for f in files:
l.append(match_content_in_file(f,'808395'))
print(l)
end = time.time()
print(end-start)
if __name__ == '__main__':
asyncio.run(main3()) # 很快
main2() # 很慢
outputs
/bin/python3 test.py[None, None, None, None, None, None, None]
1.000645637512207
[None, None, None, None, None, None, None]
7.005064249038696
回答:
这个测试很有趣,我也测了一下
- 当文件都不存在时,aiofiles快很多
~/test ᐅ python3 -VPython 3.8.1
~/test ᐅ python3 aiotest.py
[None, None, None, None, None, None, None]
1.0032050609588623
[None, None, None, None, None, None, None]
7.023258686065674
~/test ᐅ sw_vers
ProductName: Mac OS X
ProductVersion: 10.15.7
BuildVersion: 19H2
当文件存在时,aiofiles慢了很多很多
import asyncioimport os
import time
from random import randint
from pathlib import Path
import aiofiles
BASE_DIR = Path('log')
files = [
'20210523.log',
'20210522.log',
'20210521.log',
'20210524.log',
'20210525.log',
'20210520.log',
'20210519.log',
]
def gen_files():
if not BASE_DIR.exists():
BASE_DIR.mkdir(parents=True)
for fname in files:
if not (p := BASE_DIR / fname).exists():
nums = [randint(10**6, 10**7-1) for _ in range(1024*1024)]
p.write_text('\n'.join(map(str, nums)))
print(f'{p} created!')
os.system(f'ls -lh {BASE_DIR}')
async def match_content_in_file(filename:str,content:str,encoding:str="gbk")->bool:
async with aiofiles.open(filename,mode="r",encoding=encoding) as f:
# text = await f.read()
# return content in text
async for line in f:
if content in line:
return True
def match_content_in_file2(filename:str,content:str,encoding:str="gbk")->bool:
with open(filename,mode="r",encoding=encoding) as f:
# text = f.read()
# return content in text
for line in f:
if content in line:
return True
async def main3():
print('Start async process...')
start = time.time()
tasks = [match_content_in_file(BASE_DIR/f,'808395') for f in files]
l = await asyncio.gather(*tasks)
print(l)
end = time.time()
print(end - start)
def main2():
print('Start sync process...')
start = time.time()
l = []
for f in files:
l.append(match_content_in_file2(BASE_DIR/f,'808395'))
print(l)
end = time.time()
print(end-start)
if __name__ == '__main__':
gen_files() # 生成测试用文件
asyncio.run(main3()) # 很慢
main2() # 很快
结果:
total 114688-rw-r--r-- 1 lian staff 8.0M 6 12 00:24 20210519.log
-rw-r--r-- 1 lian staff 8.0M 6 12 00:24 20210520.log
-rw-r--r-- 1 lian staff 8.0M 6 12 00:23 20210521.log
-rw-r--r-- 1 lian staff 8.0M 6 12 00:23 20210522.log
-rw-r--r-- 1 lian staff 8.0M 6 12 00:23 20210523.log
-rw-r--r-- 1 lian staff 8.0M 6 12 00:24 20210524.log
-rw-r--r-- 1 lian staff 8.0M 6 12 00:24 20210525.log
Start async process...
[True, True, True, True, True, True, True]
283.923513174057
Start sync process...
[True, True, True, True, True, True, True]
0.46163487434387207
以上是 为什么aiofiles 比普通文件操作还要慢? 的全部内容, 来源链接: utcz.com/p/937976.html