关于python正则re.search匹配的困惑
python">re.search(r'(%[0-9a-fA-F]{2})', r'自定:%E8%87%AA%E5%AE%9A%E5')# '%E8'
re.search(r'(%[0-9a-fA-F]{2})*', r'自定:%E8%87%AA%E5%AE%9A%E5')
# ''
re.search(r'((%[0-9a-fA-F]{2})*)', r'自定:%E8%87%AA%E5%AE%9A%E5')
# ''
re.search(r'(?<=:)((%[0-9a-fA-F]{2})*)', r'自定:%E8%87%AA%E5%AE%9A%E5')
# '%E8%87%AA%E5%AE%9A%E5'
请问为什么第一行可以匹配到一个hex,二三行却匹配到一个空字符?
为什么第四行设定了前方是一个:后,又匹配到了全部的hex字符?
回答:
请问为什么第一行可以匹配到一个hex,二三行却匹配到一个空字符?
(%[0-9a-fA-F]{2})的意思是“% 后面跟着两个范围内的数字或字母,且只匹配一次”;re.search只返回从左到右第一个匹配的对象*表示匹配零次或多次
所以第一行可以匹配到字符串最左边的 %E8,而且只匹配到一个。而第二、三行由于 * 的存在,第一个匹配到的是最左边的空字符,所以返回的是 ''。
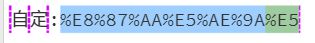
如果使用 re.finditer() 就可以看到第二、三行是都可以匹配到全部的(%E8%87%AA%E5%AE%9A%E5)。进一步,如果直接将第二行的 * 改为 +,即匹配 1 次或多次,就会返回你想要的全部 hex:
>>> matches = re.finditer(r'(%[0-9a-fA-F]{2})*', r'自定:%E8%87%AA%E5%AE%9A%E5')>>> for m in matches:
... print(m)
...
<re.Match object; span=(0, 0), match=''>
<re.Match object; span=(1, 1), match=''>
<re.Match object; span=(2, 2), match=''>
<re.Match object; span=(3, 24), match='%E8%87%AA%E5%AE%9A%E5'>
<re.Match object; span=(24, 24), match=''>
>>> re.search(r'(%[0-9a-fA-F]{2})+', r'自定:%E8%87%AA%E5%AE%9A%E5')
<re.Match object; span=(3, 24), match='%E8%87%AA%E5%AE%9A%E5'>
为什么第四行设定了前方是一个:后,又匹配到了全部的hex字符?
?< 这个东西叫后行断言(lookbehind assertion),小于号 < 表示箭头方向左向,即“回头看”。后面的 =: 就是表面意思,等于 :。综合起来就是“左边的字符是 :”。
所以 (?<=:)((%[0-9a-fA-F]{2})*) 的意思就是“匹配左边是 :,且符合 % 后面跟着两个范围内的数字或字母的模式的字符串,匹配零次或多次”。那既然有 * 的存在,为什么不会像第二、三行一样匹配到最左边的空字符呢?因为他们左边不是 :。
所以你想匹配到所有 hex 字符,最简单的就是把第二行的 * 改为 +:(%[0-9a-fA-F]{2})+。而第四行显然是有点多余了。
关于更多正则表达式的内容,例如先行断言和后行断言等,可以参见我的文章:SLP3:2.1 正则表达式。
以上是 关于python正则re.search匹配的困惑 的全部内容, 来源链接: utcz.com/p/937885.html