为什么requests能访问到的页面,而使用scrapy就访问不到?
我在爬取亚马逊的时候遇到一个很奇怪的问题,就是我的scrapy框架在爬取某一页面的时候会弹出验证码。
而我通过requests库直接爬取的时候,一切都正常。
很奇怪,为什么会有这样的问题,不太理解scrapy底层的我前来提问。附上代码:
使用requests库
import requestsurl = 'https://www.amazon.com/product-reviews/B078YXKQSJ'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1200.0 Iron/21.0.1200.0 Safari/537.1'
}
proxy = {
'http': 'http://223.214.204.252:18313'
}
response = requests.get(url, proxies=proxy, headers=headers)
print(response.text)
使用scrapy 部分代码
middlewares
class AmazonUserAgentDownloadMiddleware(object): user_agent = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
def process_request(self, request, spider):
user_agent = random.choice(self.user_agent)
request.headers['User-Agent'] = user_agent
class ProxyDownloadMiddleware(object):
def __init__(self):
super(IPProxyDownloadMiddleware, self).__init__()
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://%s" % '49.88.119.137:22921')
prefs = {"profile.managed_default_content_settings.images": 2}
options.add_experimental_option('prefs', prefs)
self.driver = webdriver.Chrome(chrome_options=options)
"""
请求
"""
def process_request(self, request, spider):
request.meta['proxy'] = 'http://49.88.119.137:22921'
with open('cookies.json', 'r') as fp:
file_cookies = json.loads(fp.read())
cookies_dict = dict()
for cookie in file_cookies:
# 在保存成dict时,我们其实只要cookies中的name和value,而domain等其他都可以不要
cookies_dict[cookie['name']] = cookie['value']
print(cookies_dict)
# 保存cookie到日志
logging.debug(cookies_dict)
request.cookies = cookies_dict
print(request.meta)
"""
selenium 发起请求
"""
def selenium_request(self, request, response):
print('selenium is start')
# 请求
self.driver.get(request.url)
# 等待2s
time.sleep(2)
# 获取网页源码
html = self.driver.page_source
# 判断是否是机器人
if 'Robot Check' in html:
# 判断是否需要验证码
img_src = self.driver.find_element_by_xpath("//div[@class='a-row a-text-center']/img")
if img_src:
src = img_src.get_attribute('src')
if re.match(r'https://images-na.ssl-images-amazon.com/captcha/*', src):
print("需要验证码")
# 手动填写验证码
verify_code = input("请填写验证码:")
input_box = self.driver.find_element_by_xpath("//input[@id='captchacharacters']")
input_box.send_keys(verify_code)
print("验证码填写完成请等待")
print('selenium提交表单...')
one_click = self.driver.find_element_by_xpath("//button[@class='a-button-text']")
one_click.click()
time.sleep(2)
cookies_list = self.driver.get_cookies()
json_cookies = json.dumps(cookies_list) # 通过json将cookies写入文件
html = self.driver.page_source()
with open('cookies.json', 'w') as f:
f.write(json_cookies)
self.driver.quit() # 使用完, 记得关闭浏览器, 不然chromedriver.exe进程为一直在内存中.
else:
cookies_list = self.driver.get_cookies()
json_cookies = json.dumps(cookies_list) # 通过json将cookies写入文件
with open('cookies.json', 'w') as f:
f.write(json_cookies)
return html
"""
响应
"""
def process_response(self, request, response, spider):
print('process_response ...')
# 如果是机器人 调用selenium
if 'Robot Check' in response.text:
with open(r'E:\php\www\html\Robot_Check.html', 'w') as f:
f.write(response.text)
html = self.selenium_request(request, response)
return HtmlResponse(url=self.driver.current_url, body=html, request=request, encoding='utf-8')
settings:
# -*- coding: utf-8 -*-import datetime
BOT_NAME = 'amazon'
SPIDER_MODULES = ['amazon.spiders']
NEWSPIDER_MODULE = 'amazon.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 10
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
DOWNLOADER_MIDDLEWARES = {
'amazon.middlewares.AmazonUserAgentDownloadMiddleware': 300,
'amazon.middlewares.IPProxyDownloadMiddleware': 301,
}
ITEM_PIPELINES = {
'amazon.pipelines.AmazonTwistedPipeline': 300,
}
LOG_LEVEL = 'DEBUG'
to_day = datetime.datetime.now()
log_file_path = 'log/scrapy_{}_{}_{}.log'.format(to_day.year, to_day.month, to_day.day)
LOG_FILE = log_file_path
对于scrapy出现这种问题的尝试
先说结果,出现验证码的时候通过selenium操作获取到cookie保存到本地,结果用selenium打开网页,发现并没有验证码了,但是scrapy发起的请求就有验证码。然后把selenium获得cookie放到下一次请求里,一如既往还是会出现验证码
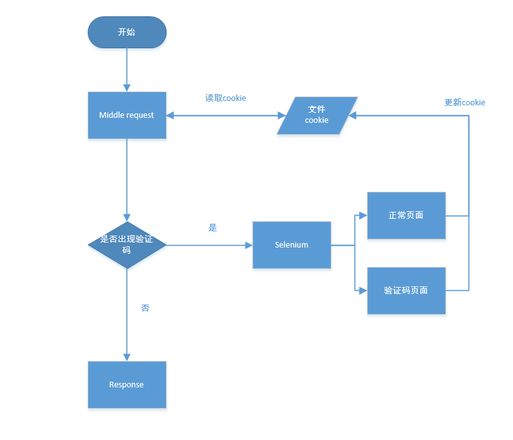
- 中间件
process_request读取本地cookie文件里的cookie,第一次开始文件是空的 - 发起请求,在中间件
process_response判断是否机器人验证码,如果是验证码打开selenium,获取到cookie保存到本地 - 下一步流程
请求爬虫大佬可以解惑~
回答:
推荐使用统一的UA与代理试试
以上是 为什么requests能访问到的页面,而使用scrapy就访问不到? 的全部内容, 来源链接: utcz.com/p/937794.html