为什么用scrapy爬数据会被反扒发现,使用requests就没有问题?
url = "https://news.51cto.com/" headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
text = requests.get(url, headers=headers).text
print(text)
// 使用requests请求headers加个user-agent就能爬到数据
class SetHeaderDownloaderMiddleware(object): def process_request(self, request, spider):
request.headers.setdefault("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36")
//scrapy 添加了一个headers的中间件
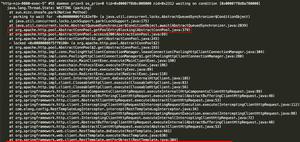
scrapy shell https://news.51cto.com
scrapy 就被反扒的程序发现?

是什么原因?
回答:
反扒机制很多,对于请求头的限制是一般的限制手段,你保证了请求头相同,但是requests和scrapy有其他不同机制,举个例子:①网站会对同一IP一段时间内请求次数进行监控,而scrapy会开多线程,频繁请求等,但是requests是你运行一次程序才访问一次,不会频繁访问
以上只是一个例子,你最好去除scrapy和requests的区别,控制变量,排除因素
以上是 为什么用scrapy爬数据会被反扒发现,使用requests就没有问题? 的全部内容, 来源链接: utcz.com/p/937742.html