前端异常处理详解
除了调试,处理异常或许是程序员编程时间占比最高的了。我们天天和各种异常打交道,就好像我们天天和 Bug 打交道一样。因此正确认识异常,并作出合适的异常处理就显得很重要了。
我们先尝试抛开前端这个限定条件,来看下更广泛意义上程序的报错以及异常处理。不管是什么语言,都会有异常的发生。而我们程序员要做的就是正确识别程序中的各种异常,并针对其做相应的异常处理。
然而,很多人对异常的处理方式是事后修补,即某个异常发生的时候,增加对应的条件判断,这真的是一种非常低效的开发方式,非常不推荐大家这么做。那么究竟如何正确处理异常呢?由于不同语言有不同的特性,因此异常处理方式也不尽相同。但是异常处理的思维框架一定是一致的。本文就前端异常进行详细阐述,但是读者也可以稍加修改延伸到其他各个领域。
什么是异常
用直白的话来解释异常的话,就是程序发生了意想不到的情况,这种情况影响到了程序的正确运行。
从根本上来说,异常就是一个数据结构,其保存了异常发生的相关信息,比如错误码,错误信息等。以 JS 中的标准内置对象 Error 为例,其标准属性有 name 和 message。然而不同的浏览器厂商有自己的自定义属性,这些属性并不通用。比如 Mozilla 浏览器就增加了 filename 和 stack 等属性。
值得注意的是错误只有被抛出,才会产生异常,不被抛出的错误不会产生异常。比如:
function t() {console.log("start");
new Error();
console.log("end");
}
t();

(动画演示)
这段代码不会产生任何的异常,控制台也不会有任何错误输出。
异常的分类
按照产生异常时程序是否正在运行,我们可以将错误分为编译时异常和运行时异常。
编译时异常指的是源代码在编译成可执行代码之前产生的异常。而运行时异常指的是可执行代码被装载到内存中执行之后产生的异常。
编译时异常
我们知道 TS 最终会被编译成 JS,从而在 JS Runtime中执行。既然存在编译,就有可能编译失败,就会有编译时异常。
比如我使用 TS 写出了如下代码:
const s: string = 123;这很明显是错误的代码, 我给 s 声明了 string 类型,但是却给它赋值 number。
当我使用 tsc(typescript 编译工具,全称是 typescript compiler)尝试编译这个文件的时候会有异常抛出:
tsc a.tsa.ts:1:7 - error TS2322: Type '123' is not assignable to type 'string'.
1 const s: string = 123;
~
Found 1 error.
这个异常就是编译时异常,因为我的代码还没有执行。
然而并不是你用了 TS 才存在编译时异常,JS 同样有编译时异常。有的人可能会问 JS 不是解释性语言么?是边解释边执行,没有编译环节,怎么会有编译时异常?
别急,我举个例子你就明白了。如下代码:
function t() {console.log('start')
await sa
console.log('end')
}
t()
上面的代码由于存在语法错误,不会编译通过,因此并不会打印start,侧面证明了这是一个编译时异常。尽管 JS 是解释语言,也依然存在编译阶段,这是必然的,因此自然也会有编译异常。
总的来说,编译异常可以在代码被编译成最终代码前被发现,因此对我们的伤害更小。接下来,看一下令人心生畏惧的运行时异常。
运行时异常
相信大家对运行时异常非常熟悉。这恐怕是广大前端碰到最多的异常类型了。众所周知的 NPE(Null Pointer Exception) 就是运行时异常。
将上面的例子稍加改造,得到下面代码:
function t() {console.log("start");
throw 1;
console.log("end");
}
t();

(动画演示)
如上,则会打印出start。由于异常是在代码运行过程中抛出的,因此这个异常属于运行时异常。相对于编译时异常,这种异常更加难以发现。上面的例子可能比较简单,但是如果我的异常是隐藏在某一个流程控制语句(比如 if else)里面呢?程序就可能在客户的电脑走入那个抛出异常的 if 语句,而在你的电脑走入另一条。这就是著名的 《在我电脑上好好的》 事件。
异常的传播
异常的传播和我之前写的浏览器事件模型有很大的相似性。只不过那个是作用在 DOM 这样的数据结构,这个则是作用在函数调用栈这种数据结构,并且事件传播存在捕获阶段,异常传播是没有的。不同 C 语言,JS 中异常传播是自动的,不需要程序员手动地一层层传递。如果一个异常没有被 catch,它会沿着函数调用栈一层层传播直到栈空。
异常处理中有两个关键词,它们是throw(抛出异常) 和 catch(处理异常)。 当一个异常被抛出的时候,异常的传播就开始了。异常会不断传播直到遇到第一个 catch。 如果程序员没有手动 catch,那么一般而言程序会抛出类似unCaughtError,表示发生了一个异常,并且这个异常没有被程序中的任何 catch 语言处理。未被捕获的异常通常会被打印在控制台上,里面有详细的堆栈信息,从而帮助程序员快速排查问题。实际上我们的程序的目标是避免 unCaughtError这种异常,而不是一般性的异常。
一点小前提
由于 JS 的 Error 对象没有 code 属性,只能根据 message 来呈现,不是很方便。我这里进行了简单的扩展,后面很多地方我用的都是自己扩展的 Error ,而不是原生 JS Error ,不再赘述。
oldError = Error;Error = function ({ code, message, fileName, lineNumber }) {
error = new oldError(message, fileName, lineNumber);
error.code = code;
return error;
};
手动抛出 or 自动抛出
异常既可以由程序员自己手动抛出,也可以由程序自动抛出。
throw new Error(`I'm Exception`);(手动抛出的例子)
a = null;a.toString(); // Thrown: TypeError: Cannot read property 'toString' of null
(程序自动抛出的例子)
自动抛出异常很好理解,毕竟我们哪个程序员没有看到过程序自动抛出的异常呢?
那什么时候应该手动抛出异常呢?
一个指导原则就是你已经预知到程序不能正确进行下去了。比如我们要实现除法,首先我们要考虑的是被除数为 0 的情况。当被除数为 0 的时候,我们应该怎么办呢?是抛出异常,还是 return 一个特殊值?答案是都可以,你自己能区分就行,这没有一个严格的参考标准。 我们先来看下抛出异常,告诉调用者你的输入,我处理不了这种情况。
function divide(a, b) {a = +a;
b = +b; // 转化成数字
if (!b) {
// 匹配 +0, -0, NaN
throw new Error({
code: 1,
message: "Invalid dividend " + b,
});
}
if (Number.isNaN(a)) {
// 匹配 NaN
throw new Error({
code: 2,
message: "Invalid divisor " + a,
});
}
return a / b;
}
上面代码会在两种情况下抛出异常,告诉调用者你的输入我处理不了。由于这两个异常都是程序员自动手动抛出的,因此是可预知的异常。
刚才说了,我们也可以通过返回值来区分异常输入。我们来看下返回值输入是什么,以及和异常有什么关系。
异常 or 返回
如果是基于异常形式(遇到不能处理的输入就抛出异常)。当别的代码调用divide的时候,需要自己 catch。
function t() {try {
divide("foo", "bar");
} catch (err) {
if (err.code === 1) {
return console.log("被除数必须是除0之外的数");
}
if (err.code === 2) {
return console.log("除数必须是数字");
}
throw new Error("不可预知的错误");
}
}
然而就像上面我说的那样,divide 函数设计的时候,也完全可以不用异常,而是使用返回值来区分。
function divide(a, b) {a = +a;
b = +b; // 转化成数字
if (!b) {
// 匹配 +0, -0, NaN
return new Error({
code: 1,
message: "Invalid dividend " + b,
});
}
if (Number.isNaN(a)) {
// 匹配 NaN
return new Error({
code: 2,
message: "Invalid divisor " + a,
});
}
return a / b;
}
当然,我们使用方式也要作出相应改变。
function t() {const res = divide("foo", "bar");
if (res.code === 1) {
return console.log("被除数必须是除0之外的数");
}
if (res.code === 2) {
return console.log("除数必须是数字");
}
return new Error("不可预知的错误");
}
这种函数设计方式和抛出异常的设计方式从功能上说都是一样的,只是告诉调用方的方式不同。如果你选择第二种方式,而不是抛出异常,那么实际上需要调用方书写额外的代码,用来区分正常情况和异常情况,这并不是一种良好的编程习惯。
然而在 Go 等返回值可以为复数的语言中,我们无需使用上面蹩脚的方式,而是可以:
res, err := divide("foo", "bar");if err != nil {
log.Fatal(err)
}
这是和 Java 和 JS 等语言使用的 try catch 不一样的的地方,Go 是通过 panic recover defer 机制来进行异常处理的。感兴趣的可以去看看 Go 源码关于错误测试部分
可能大家对 Go 不太熟悉。没关系,我们来继续看下 shell。实际上 shell 也是通过返回值来处理异常的,我们可以通过 $? 拿到上一个命令的返回值,这本质上也是一种调用栈的传播行为,而且是通过返回值而不是捕获来处理异常的。
上面提到了异常传播是作用在函数调用栈上的。当一个异常发生的时候,其会沿着函数调用栈逐层返回,直到第一个 catch 语句。当然 catch 语句内部仍然可以触发异常(自动或者手动)。如果 catch 语句内部发生了异常,也一样会沿着其函数调用栈继续执行上述逻辑,专业术语是 stack unwinding。

伪代码来描述一下:
function bubble(error, fn) {if (fn.hasCatchBlock()) {
runCatchCode(error);
}
if (callstack.isNotEmpty()) {
bubble(error, callstack.pop());
}
}
这就是异常传播的一切!仅此而已。
异常的处理
我们已经了解来异常的传播方式了。那么接下来的问题是,我们应该如何在这个传播过程中处理异常呢?
我们来看一个简单的例子:
function a() {b();
}
function b() {
c();
}
function c() {
throw new Error("an error occured");
}
a();
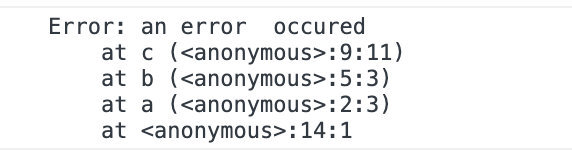
我们将上面的代码放到 chrome 中执行, 会在控制台显示如下输出:
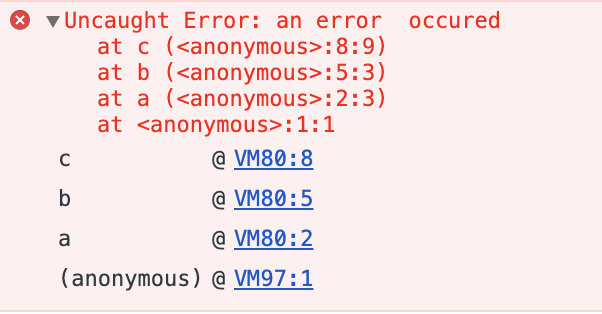
我们可以清楚地看出函数的调用关系。即错误是在 c 中发生的,而 c 是 b 调用的,b 是 a 调用的。这个函数调用栈是为了方便开发者定位问题而存在的。
上面的代码,我们并没有 catch 错误,因此上面才会有uncaught Error。
那么如果我们 catch ,会发生什么样的变化呢?catch 的位置会对结果产生什么样的影响?在 a ,b,c 中 catch 的效果是一样的么?
我们来分别看下:
function a() {b();
}
function b() {
c();
}
function c() {
try {
throw new Error("an error occured");
} catch (err) {
console.log(err);
}
}
a();
(在 c 中 catch)
我们将上面的代码放到 chrome 中执行, 会在控制台显示如下输出:
可以看出,此时已经没有uncaught Error啦,仅仅在控制台显示了标准输出,而非错误输出(因为我用的是 console.log,而不是 console.error)。然而更重要是的是,如果我们没有 catch,那么后面的同步代码将不会执行。
比如在 c 的 throw 下面增加一行代码,这行代码是无法被执行的,无论这个错误有没有被捕获。
function c() {try {
throw new Error("an error occured");
console.log("will never run");
} catch (err) {
console.log(err);
}
}
我们将 catch 移动到 b 中试试看。
function a() {b();
}
function b() {
try {
c();
} catch (err) {
console.log(err);
}
}
function c() {
throw new Error("an error occured");
}
a();
(在 b 中 catch)
在这个例子中,和上面在 c 中捕获没有什么本质不同。其实放到 a 中捕获也是一样,这里不再贴代码了,感兴趣的自己试下。
既然处于函数调用栈顶部的函数报错, 其函数调用栈下方的任意函数都可以进行捕获,并且效果没有本质不同。那么问题来了,我到底应该在哪里进行错误处理呢?
答案是责任链模式。我们先来简单介绍一下责任链模式,不过细节不会在这里展开。
假如 lucifer 要请假。
- 如果请假天数小于等于 1 天,则主管同意即可
- 如果请假大于 1 天,但是小于等于三天,则需要 CTO 同意。
- 如果请假天数大于三天,则需要老板同意。

这就是一个典型的责任链模式。谁有责任干什么事情是确定的,不要做自己能力范围之外的事情。比如主管不要去同意大于 1 天的审批。
举个例子,假设我们的应用有三个异常处理类,它们分别是:用户输入错误,网络错误 和 类型错误。如下代码,当代码执行的时候会报错一个用户输入异常。这个异常没有被 C 捕获,会 unwind stack 到 b,而 b 中 catch 到这个错误之后,通过查看 code 值判断其可以被处理,于是打印I can handle this。
function a() {try {
b();
} catch (err) {
if (err.code === "NETWORK_ERROR") {
return console.log("I can handle this");
}
// can't handle, pass it down
throw err;
}
}
function b() {
try {
c();
} catch (err) {
if (err.code === "INPUT_ERROR") {
return console.log("I can handle this");
}
// can't handle, pass it down
throw err;
}
}
function c() {
throw new Error({
code: "INPUT_ERROR",
message: "an error occured",
});
}
a();
而如果 c 中抛出的是别的异常,比如网络异常,那么 b 是无法处理的,虽然 b catch 住了,但是由于你无法处理,因此一个好的做法是继续抛出异常,而不是吞没异常。不要畏惧错误,抛出它。只有没有被捕获的异常才是可怕的,如果一个错误可以被捕获并得到正确处理,它就不可怕。
举个例子:
function a() {try {
b();
} catch (err) {
if (err.code === "NETWORK_ERROR") {
return console.log("I can handle this");
}
// can't handle, pass it down
throw err;
}
}
function b() {
try {
c();
} catch (err) {
if (err.code === "INPUT_ERROR") {
return console.log("I can handle this");
}
}
}
function c() {
throw new Error({
code: "NETWORK_ERROR",
message: "an error occured",
});
}
a();
如上代码不会有任何异常被抛出,它被完全吞没了,这对我们调试问题简直是灾难。因此切记不要吞没你不能处理的异常。正确的做法应该是上面讲的那种只 catch 你可以处理的异常,而将你不能处理的异常 throw 出来,这就是责任链模式的典型应用。
这只是一个简单的例子,就足以绕半天。实际业务肯定比这个复杂多得多。因此异常处理绝对不是一件容易的事情。
如果说谁来处理是一件困难的事情,那么在异步中决定谁来处理异常就是难上加难,我们来看下。
同步与异步
同步异步一直是前端难以跨越的坎,对于异常处理也是一样。以 NodeJS 中用的比较多的读取文件 API 为例。它有两个版本,一个是异步,一个是同步。同步读取仅仅应该被用在没了这个文件无法进行下去的时候。比如读取一个配置文件。而不应该在比如浏览器中读取用户磁盘上的一个图片等,这样会造成主线程阻塞,导致浏览器卡死。
// 异步读取文件fs.readFileSync();
// 同步读取文件
fs.readFile();
当我们试图同步读取一个不存在的文件的时候,会抛出以下异常:
fs.readFileSync('something-not-exist.lucifer');console.log('脑洞前端');
Thrown:
Error: ENOENT: no such file or directory, open 'something-not-exist.lucifer'
at Object.openSync (fs.js:446:3)
at Object.readFileSync (fs.js:348:35) {
errno: -2,
syscall: 'open',
code: 'ENOENT',
path: 'something-not-exist.lucifer'
}
并且脑洞前端是不会被打印出来的。这个比较好理解,我们上面已经解释过了。
而如果以异步方式的话:
fs.readFile('something-not-exist.lucifer', (err, data) => {if(err) {throw err}});console.log('lucifer')
lucifer
undefined
Thrown:
[Error: ENOENT: no such file or directory, open 'something-not-exist.lucifer'] {
errno: -2,
code: 'ENOENT',
syscall: 'open',
path: 'something-not-exist.lucifer'
}
>
脑洞前端是会被打印出来的。
其本质在于 fs.readFile 的函数调用已经成功,并从调用栈返回并执行到下一行的console.log('lucifer')。因此错误发生的时候,调用栈是空的,这一点可以从上面的错误堆栈信息中看出来。
而 try catch 的作用仅仅是捕获当前调用栈的错误(上面异常传播部分已经讲过了)。因此异步的错误是无法捕获的,比如;
try {fs.readFile("something-not-exist.lucifer", (err, data) => {
if (err) {
throw err;
}
});
} catch (err) {
console.log("catching an error");
}
上面的 catching an error 不会被打印。因为错误抛出的时候, 调用栈中不包含这个 catch 语句,而仅仅在执行fs.readFile的时候才会。
如果我们换成同步读取文件的例子看看:
try {fs.readFileSync("something-not-exist.lucifer");
} catch (err) {
console.log("catching an error");
}
上面的代码会打印 catching an error。因为读取文件被同步发起,文件返回之前线程会被挂起,当线程恢复执行的时候, fs.readFileSync 仍然在函数调用栈中,因此 fs.readFileSync 产生的异常会冒泡到 catch 语句。
简单来说就是异步产生的错误不能用 try catch 捕获,而要使用回调捕获。
可能有人会问了,我见过用 try catch 捕获异步异常啊。 比如:
rejectIn = (ms) =>new Promise((_, r) => {
setTimeout(() => {
r(1);
}, ms);
});
async function t() {
try {
await rejectIn(0);
} catch (err) {
console.log("catching an error", err);
}
}
t();
本质上这只是一个语法糖,是 Promise.prototype.catch 的一个语法糖而已。而这一语法糖能够成立的原因在于其用了 Promise 这种包装类型。如果你不用包装类型,比如上面的 fs.readFile 不用 Promise 等包装类型包装,打死都不能用 try catch 捕获。
而如果我们使用 babel 转义下,会发现 try catch 不见了,变成了 switch case 语句。这就是 try catch “可以捕获异步异常”的原因,仅此而已,没有更多。
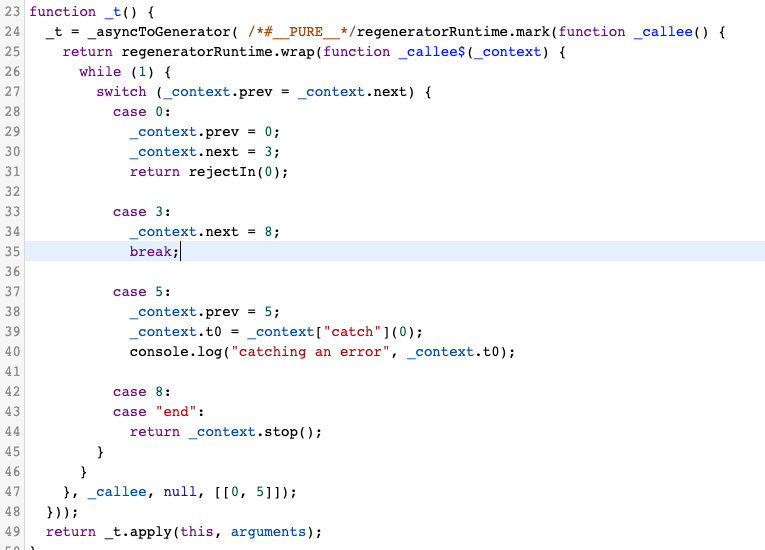
(babel 转义结果)
我使用的 babel 转义环境都记录在这里,大家可以直接点开链接查看.
异步的错误处理推荐使用容器包装,比如 Promise。然后使用 catch 进行处理。实际上 Promise 的 catch 和 try catch 的 catch 有很多相似的地方,大家可以类比过去。
和同步处理一样,很多原则都是通用的。比如异步也不要去吞没异常。下面的代码是不好的,因为它吞没了它不能处理的异常。
p = Promise.reject(1);p.catch(() => {});
更合适的做法的应该是类似这种:
p = Promise.reject(1);p.catch((err) => {
if (err == 1) {
return console.log("I can handle this");
}
throw err;
});
彻底消除运行时异常可能么?
我个人对目前前端现状最为头疼的一点是:大家过分依赖运行时,而严重忽略编译时。我见过很多程序,你如果不运行,根本不知道程序是怎么走的,每个变量的 shape 是什么。怪不得处处都可以看到 console.log。我相信你一定对此感同身受。也许你就是那个写出这种代码的人,也许你是给别人擦屁股的人。为什么会这样? 就是因为大家太依赖运行时。TS 的出现很大程度上改善了这一点,前提是你用的是 typescript,而不是 anyscript。其实 eslint 以及 stylint 对此也有贡献,毕竟它们都是静态分析工具。
我强烈建议将异常保留在编译时,而不是运行时。不妨极端一点来看:假如所有的异常都在编译时发生,而一定不会在运行时发生。那么我们是不是就可以信心满满地对应用进行重构啦?
幸运的是,我们能够做到。只不过如果当前语言做不到的话,则需要对现有的语言体系进行改造。这种改造成本真的很大。不仅仅是 API,编程模型也发生了翻天覆地的变化,不然函数式也不会这么多年没有得到普及了。
如果才能彻底消除异常呢?在回答这个问题之前,我们先来看下一门号称没有运行时异常的语言 elm。elm 是一门可以编译为 JS 的函数式编程语言,其封装了诸如网络 IO 等副作用,是一种声明式可推导的语言。 有趣的是,elm 也有异常处理。 elm 中关于异常处理(Error Handling)部分有两个小节的内容,分别是:Maybe 和 Result。elm 之所以没有运行时异常的一个原因就是它们。 一句话概括“为什么 elm 没有异常”的话,那就是elm 把异常看作数据(data)。
举个简单的例子:
maybeResolveOrNot = (ms) =>setTimeout(() => {
if (Math.random() > 0.5) {
console.log("ok");
} else {
throw new Error("error");
}
});
上面的代码有一半的可能报错。那么在 elm 中就不允许这样的情况发生。所有的可能发生异常的代码都会被强制包装一层容器,这个容器在这里是 Maybe。

在其他函数式编程语言名字可能有所不同,但是意义相同。实际上,不仅仅是异常,正常的数据也会被包装到容器中,你需要通过容器的接口来获取数据。如果难以理解的话,你可以将其简单理解为 Promsie(但并不完全等价)。
Maybe 可能返回正常的数据 data,也可能会生成一个错误 error。某一个时刻只能是其中一个,并且只有运行的时候,我们才真正知道它是什么。从这一点来看,有点像薛定谔的猫。
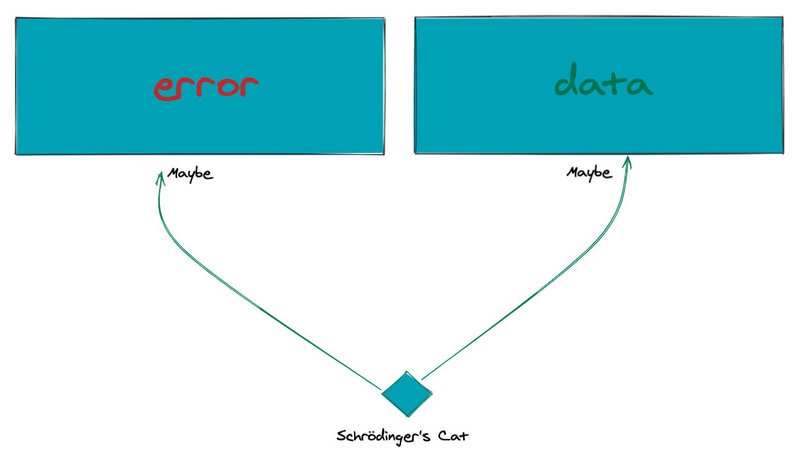
不过 Maybe 已经完全考虑到异常的存在,一切都在它的掌握之中。所有的异常都能够在编译时推导出来。当然要想推导出这些东西,你需要对整个编程模型做一定的封装会抽象,比如 DOM 就不能直接用了,而是需要一个中间层。
再来看下一个更普遍的例子 NPE:
null.toString();elm 也不会发生。原因也很简单,因为 null 也会被包装起来,当你通过这个包装类型就行访问的时候,容器有能力避免这种情况,因此就可以不会发生异常。当然这里有一个很重要的前提就是可推导,而这正是函数式编程语言的特性。这部分内容超出了本文的讨论范围,不再这里说了。
运行时异常可以恢复么?
最后要讨论的一个主题是运行时异常是否可以恢复。先来解释一下,什么是运行时异常的恢复。 还是用上面的例子:
function t() {console.log("start");
throw 1;
console.log("end");
}
t();
这个我们已经知道了, end 是不会打印的。 尽管你这么写也是无济于事:
function t() {try {
console.log("start");
throw 1;
console.log("end");
} catch (err) {
console.log("relax, I can handle this");
}
}
t();
如果我想让它打印呢?我想让程序面对异常可以自己 recover 怎么办?我已经捕获这个错误, 并且我确信我可以处理,让流程继续走下去吧!如果有能力做到这个,这个就是运行时异常恢复。
遗憾地告诉你,据我所知,目前没有任何一个引擎能够做到这一点。
这个例子过于简单, 只能帮助我们理解什么是运行时异常恢复,但是不足以让我们看出这有什么用?

我们来看一个更加复杂的例子,我们这里直接使用上面实现过的函数divide。
function t() {try {
const res = divide("foo", "bar");
alert(`you got ${res}`);
} catch (err) {
if (err.code === 1) {
return console.log("被除数必须是除0之外的数");
}
if (err.code === 2) {
return console.log("除数必须是数字");
}
throw new Error("不可预知的错误");
}
}
如上代码,会进入 catch ,而不会 alert。因此对于用户来说, 应用程序是没有任何响应的。这是不可接受的。
如果我们的代码在进入 catch 之后还能够继续返回出错位置继续执行就好了。

如何实现异常中断的恢复呢?我刚刚说了:据我所知,目前没有任何一个引擎能够做到异常恢复。那么我就来发明一个新的语法解决这个问题。
function t() {try {
const res = divide("foo", "bar");
alert(`you got ${res}`);
} catch (err) {
console.log("releax, I can handle this");
resume - 1;
}
}
t();
上面的 resume 是我定义的一个关键字,功能是如果遇到异常,则返回到异常发生的地方,然后给当前发生异常的函数一个返回值 -1,并使得后续代码能够正常运行,不受影响。这其实是一种 fallback。
这绝对是一个超前的理念。当然挑战也非常大,对现有的体系冲击很大,很多东西都要改。我希望社区可以考虑把这个东西加到标准。
最佳实践
通过前面的学习,你已经知道了异常是什么,异常是怎么产生的,以及如何正确处理异常(同步和异步)。接下来,我们谈一下异常处理的最佳实践。
我们平时开发一个应用。 如果站在生产者和消费者的角度来看的话。当我们使用别人封装的框架,库,模块,甚至是函数的时候,我们就是消费者。而当我们写的东西被他人使用的时候,我们就是生产者。
实际上,就算是生产者内部也会有多个模块构成,多个模块之间也会有生产者和消费者的再次身份转化。不过为了简单起见,本文不考虑这种关系。这里的生产者指的就是给他人使用的功能,是纯粹的生产者。
从这个角度出发,来看下异常处理的最佳实践。
作为消费者
当作为消费者的时候,我们关心的是使用的功能是否会抛出异常,如果是,他们有哪些异常。比如:
import foo from "lucifer";try {
foo.bar();
} catch (err) {
// 有哪些异常?
}
当然,理论上 foo.bar 可能产生任何异常,而不管它的 API 是这么写的。但是我们关心的是可预期的异常。因此你一定希望这个时候有一个 API 文档,详细列举了这个 API 可能产生的异常有哪些。
比如这个 foo.bar 4 种可能的异常 分别是 A,B,C 和 D。其中 A 和 B 是我可以处理的,而 C 和 D 是我不能处理的。那么我应该:
import foo from "lucifer";try {
foo.bar();
} catch (err) {
if (err.code === "A") {
return console.log("A happened");
}
if (err.code === "B") {
return console.log("B happened");
}
throw err;
}
可以看出,不管是 C 和 D,还是 API 中没有列举的各种可能异常,我们的做法都是直接抛出。
作为生产者
如果你作为生产者,你要做的就是提供上面提到的详细的 API,告诉消费者你的可能错误有哪些。这样消费者就可以在 catch 中进行相应判断,处理异常情况。
你可以提供类似上图的错误表,让大家可以很快知道可能存在的可预知异常有哪些。不得不吐槽一句,在这一方面很多框架,库做的都很差。希望大家可以重视起来,努力维护良好的前端开发大环境。
总结
本文很长,如果你能耐心看完,你真得给可以给自己鼓个掌 👏👏👏。
我从什么是异常,以及异常的分类,让大家正确认识异常,简单来说异常就是一种数据结构而已。
接着,我又讲到了异常的传播和处理。这两个部分是紧密联系的。异常的传播和事件传播没有本质不同,主要不同是数据结构不同,思想是类似的。具体来说异常会从发生错误的调用处,沿着调用栈回退,直到第一个 catch 语句或者栈为空。如果栈为空都没有碰到一个 catch,则会抛出uncaught Error。 需要特别注意的是异步的异常处理,不过你如果对我讲的原理了解了,这都不是事。
然后,我提出了两个脑洞问题:
- 彻底消除运行时异常可能么?
- 运行时异常可以恢复么?
这两个问题非常值得研究,但由于篇幅原因,我这里只是给你讲个轮廓而已。如果你对这两个话题感兴趣,可以和我交流。
最后,我提到了前端异常处理的最佳实践。大家通过两种角色(生产者和消费者)的转换,认识一下不同决定关注点以及承担责任的不同。具体来说提到了 明确声明可能的异常以及 处理你应该处理的,不要吞没你不能处理的异常。当然这个最佳实践仍然是轮廓性的。如果大家想要一份 前端最佳实践 checklist,可以给我留言。留言人数较多的话,我考虑专门写一个前端最佳实践 checklist 类型的文章。
以上是 前端异常处理详解 的全部内容, 来源链接: utcz.com/p/26128.html