C语言实现英文文本词频统计
这几天写了一个基于C语言对文本词频进行统计的程序,开发及调试环境:mac集成开发环境Xcode;测试文本,马丁.路德金的《I have a dream》原文演讲稿。
主要运行步骤:
1. 打开文本把文本内容读入流中并且开辟相应空间放入内存
2 .对文本内容进行处理,去除大写字母(转化为小写),去除特殊字符
3. 基于单链表对词频进行统计
4. 把统计结果进行归并排序
5.打印输出全部词频或者频率最高的10个单词和其出现次数
6.释放所有结点消耗的内存
废话不多说,上代码!
//
// main.c
// word_frequency_statistic
//
// Created by tianling on 14-3-16.
// Copyright (c) 2014年 tianling. All rights reserved.
// 实现英文文本的词频统计
//
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define ERROR 1
#define OK 0
const int WORD_LENGTH = 250;//定义单个单词最大长度
typedef int status;
/*
**定义存储单词及其出现次数的结构体
*/
typedef struct Node{
char word[WORD_LENGTH];
int time;
struct Node *next;
}wordNode;
wordNode *headNode = NULL;//定义链表头指针
/*
**函数声明
*/
wordNode *wordSearch(char *word,int *num);
status wordCount(char *word,int *num);
void printCountList(int *num);
void PrintFirstTenTimes();
void mergeSort(wordNode **head);
void FrontBackSplit(wordNode *head,wordNode **pre,wordNode **next);
void wordJob(char word[]);
wordNode *SortedMerge(wordNode *pre,wordNode *next);
void release();
status main(int argc,char *argv[])
{
char temp[WORD_LENGTH];//定义用以临时存放单词的数组
FILE *file;
int count,articleWordNum = 0;//定义统计结点个数的变量
int *num = &articleWordNum,choose;
/*
**读取文件
*/
if((file = fopen("/Users/tianling/Documents/Data_Structure/word_frequency_statistic/word_frequency_statistic/article.txt", "r")) == NULL){
//这里是绝对路径,基于XCode编译器查找方便的需求
printf("文件读取失败!");
exit(1);
}
while((fscanf(file,"%s",temp))!= EOF){
wordJob(temp);
count = wordCount(temp,num);
}
fclose(file);//关闭文件
printCountList(num);
printf("***********请选择***********\n");
printf("*****1. 输出词频最高的10个词**\n");
printf("*****2. 退出****************\n");
scanf("%d",&choose);
if(choose == 1){
mergeSort(&headNode);
PrintFirstTenTimes();
}else{
release();
exit(0);
}
release();
return 0;
}
/*
**查找单词所在结点
*/
wordNode *wordSearch(char *word,int *num){
wordNode *node;//声明一个新结点
if(headNode == NULL){//若头结点为空
node = (wordNode*)malloc(sizeof(wordNode));
strcpy(node->word, word);//将第一个单词赋值给这个新结点
node->time = 0;//初始化该单词的出现次数
*num+=1;
headNode = node;//将头结点指向这个新结点
return node;
}
wordNode *nextNode = headNode;
wordNode *preNode = NULL;
while(nextNode != NULL && strcmp(nextNode->word, word) != 0){
preNode = nextNode;
nextNode = nextNode->next;
}
//若该单词不存在,则在链表中生成新结点
if(nextNode == NULL){
node = (wordNode*)malloc(sizeof(wordNode));
strcpy(node->word, word);
node->time = 0;
node->next = headNode->next;
headNode->next = node;
*num+=1;
return node;
}else
return nextNode;
}
/*
**词频统计
*/
status wordCount(char *word,int *num){
wordNode *tmpNode = NULL;
tmpNode = wordSearch(word,num);
if(tmpNode == NULL){
return ERROR;
}
tmpNode->time++;
return 0;
}
/*
**打印所有词频
*/
void printCountList(int *num){
if(headNode == NULL){
printf("该文件无内容!");
}else{
wordNode *preNode = headNode;
printf("总词量 %d \n",*num);
while(preNode != NULL){
printf("%s 出现次数 %d\n",preNode->word,preNode->time);
preNode = preNode->next;
}
}
}
/*
**打印词频最高的10个词
*/
void PrintFirstTenTimes(){
if(headNode == NULL){
printf("该文件无内容!");
}else{
wordNode *preNode = headNode;
int i = 0;
printf("出现次数最多的10个词如下: \n");
while (preNode != NULL && i<=10) {
printf("%s 出现次数 %d\n",preNode->word,preNode->time);
preNode = preNode->next;
i++;
}
}
}
/*
**对词频统计结果进行归并排序
*/
void mergeSort(wordNode **headnode){
wordNode *pre,*next,*head;
head = *headnode;
//若链表长度为0或1则停止排序
if(head == NULL || head->next == NULL){
return;
}
FrontBackSplit(head,&pre,&next);
mergeSort(&pre);
mergeSort(&next);
*headnode = SortedMerge(pre,next);
}
/*
**将链表进行分组
*/
void FrontBackSplit(wordNode *source,wordNode **pre,wordNode **next){
wordNode *fast;
wordNode *slow;
if(source == NULL || source->next == NULL){
*pre = source;
*next = NULL;
}else{
slow = source;
fast = source->next;
while(fast != NULL){
fast = fast->next;
if(fast != NULL){
slow = slow->next;
fast = fast->next;
}
}
*pre = source;
*next = slow->next;
slow->next = NULL;
}
}
/*
**根据排序结果更换头结点
*/
wordNode *SortedMerge(wordNode *pre,wordNode *next){
wordNode *result = NULL;
if(pre == NULL)
return next;
else if(next == NULL)
return pre;
if(pre->time >= next->time){
result = pre;
result->next = SortedMerge(pre->next,next);
}else{
result = next;
result->next = SortedMerge(pre,next->next);
}
return result;
}
/*
**处理大写字母及特殊字符
*/
void wordJob(char word[]){
int i,k;
char *specialChar = ",.;:'?!><+=|*&^%$#@\"";//定义特殊字符集
for(i = 0;i<strlen(word);i++){
//筛选并将字符串中的大写字母转化为小写字母
if(word[i]>='A'&& word[i]<='Z'){
word[i] += 32;
}
//筛选并去除字符串中的特殊字符
for(k = 0;k<strlen(specialChar);k++){
if(word[i] == specialChar[k]){
while(i<strlen(word)){
word[i] = word[i+1];
i++;
}
}
}
}
}
/*
**释放所有结点内存
*/
void release(){
if(headNode == NULL)
return;
wordNode *pre = headNode;
while(pre != NULL){
headNode = pre->next;
free(pre);
pre = headNode;
}
}
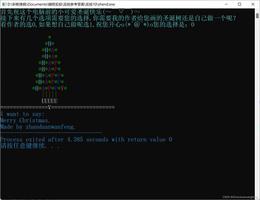
调试结果:(Xcode环境)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
以上是 C语言实现英文文本词频统计 的全部内容, 来源链接: utcz.com/p/244980.html